Merry Christmas, everyone, if that's what you're into.
I have been using Ceph for a few months now and it has been a great experience. I have four Dell R740s and one R730 in the cluster, and I plan to add two C240 M4s to deploy a mini-cloud at other locations (but that's a conversation for another day).
I have been running Ceph on one subnet with 10GBe NICs. Most of my LAN is 10GBe, except for PIs and NUCs (for personal use) and PBS (working on a better solution for that). I have done a lot of research on Ceph, including reading documentation, forum posts, and watching countless YouTube videos. However, a lot of it still seems like voodoo to me, as I am a slow learner. One thing that was clear is that Ceph should be on its own subnet or mesh network.
Initially, I had a C3850 with 1GBE and a multi-10GBe module. But I have since added a second switch, a Cisco N9K-C92160YC-X with 48 ports of 1/10/25G SFP and 6 40G QSFP (or 4 100G). I also replaced the NDC of each PowerEdge with a Mellanox Dual Gbe NIC. On Monday night, I reconfigured the network.
The first warning sign was when it took over an hour to restore a small VM from PBS, which usually takes less than a minute. I read something about increasing the MTU to 9000, but that only made things worse. Fast forward to today, and I have OSDs dropping like flies and the entire cluster is essentially inoperable. The more I tinker with it, the worse it gets.
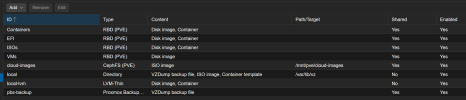
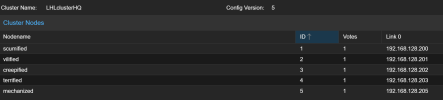
I have attached photos of my network user interface for each node, as well as the storage user interface. I am most likely neglecting some small, but significant part of the configuration, and I hope I'm not making myself out to be too much of an imbecile. I would greatly appreciate any guidance on setting this up correctly, rather than reverting back to the basic setup. Thank you for taking the time to read this. Merry Christmas.
I have been using Ceph for a few months now and it has been a great experience. I have four Dell R740s and one R730 in the cluster, and I plan to add two C240 M4s to deploy a mini-cloud at other locations (but that's a conversation for another day).
I have been running Ceph on one subnet with 10GBe NICs. Most of my LAN is 10GBe, except for PIs and NUCs (for personal use) and PBS (working on a better solution for that). I have done a lot of research on Ceph, including reading documentation, forum posts, and watching countless YouTube videos. However, a lot of it still seems like voodoo to me, as I am a slow learner. One thing that was clear is that Ceph should be on its own subnet or mesh network.
Initially, I had a C3850 with 1GBE and a multi-10GBe module. But I have since added a second switch, a Cisco N9K-C92160YC-X with 48 ports of 1/10/25G SFP and 6 40G QSFP (or 4 100G). I also replaced the NDC of each PowerEdge with a Mellanox Dual Gbe NIC. On Monday night, I reconfigured the network.
The first warning sign was when it took over an hour to restore a small VM from PBS, which usually takes less than a minute. I read something about increasing the MTU to 9000, but that only made things worse. Fast forward to today, and I have OSDs dropping like flies and the entire cluster is essentially inoperable. The more I tinker with it, the worse it gets.
Code:
[global]
auth_client_required = cephx
auth_cluster_required = cephx
auth_service_required = cephx
cluster_network = 10.0.0.0/24
fsid = e4aa8136-854c-4504-b839-795aaac19cd3
mon_allow_pool_delete = true
mon_host = 192.168.128.200 192.168.128.202 192.168.128.201
ms_bind_ipv4 = true
ms_bind_ipv6 = false
osd_pool_default_min_size = 2
osd_pool_default_size = 3
public_network = 192.168.128.0/24
[client]
keyring = /etc/pve/priv/$cluster.$name.keyring
[client.crash]
keyring = /etc/pve/ceph/$cluster.$name.keyring
[mds]
keyring = /var/lib/ceph/mds/ceph-$id/keyring
[mds.scumified]
host = scumified
mds_standby_for_name = pve
[mon.creepified]
public_addr = 192.168.128.202
[mon.scumified]
public_addr = 192.168.128.200
[mon.vilified]
public_addr = 192.168.128.201mds_standby_for_name that is new, never used to say that.
Code:
HEALTH_WARN: 1 filesystem is degraded
fs cloud-images is degraded
Code:
HEALTH_WARN: 1 MDSs report slow metadata IOs
mds.scumified(mds.0): 4 slow metadata IOs are blocked > 30 secs, oldest blocked for 299 secs
Code:
HEALTH_WARN: Reduced data availability: 256 pgs inactive, 17 pgs down, 233 pgs peering, 1 pg incomplete
pg 2.16 is stuck peering for 20h, current state peering, last acting [8,16,20]
pg 2.17 is stuck peering for 14h, current state peering, last acting [23,13]
pg 2.18 is stuck peering for 14h, current state peering, last acting [18,16]
pg 2.19 is stuck peering for 14h, current state peering, last acting [6,11,13]
pg 2.1a is stuck peering for 16h, current state peering, last acting [11,14,2]
pg 2.1b is stuck peering for 14h, current state peering, last acting [22,14,11]
pg 3.16 is stuck peering for 14h, current state peering, last acting [9,1,20]
pg 3.17 is down, acting [20]
pg 3.18 is stuck peering for 14h, current state peering, last acting [18,16,6]
pg 3.19 is stuck peering for 14h, current state peering, last acting [1,22,10]
pg 3.1a is stuck peering for 14h, current state peering, last acting [16,5,20]
pg 3.1b is stuck peering for 13h, current state peering, last acting [15,7,20]
pg 4.10 is stuck peering for 14h, current state peering, last acting [13,5]
pg 4.11 is stuck peering for 14h, current state peering, last acting [7,18]
pg 4.1c is stuck peering for 14h, current state peering, last acting [15,6,23]
pg 4.1d is down, acting [18]
pg 4.1e is stuck peering for 13h, current state peering, last acting [0,7]
pg 4.1f is stuck peering for 14h, current state peering, last acting [17,8,1]
pg 5.10 is stuck peering for 14h, current state peering, last acting [20,16,7]
pg 5.11 is stuck peering for 14h, current state peering, last acting [20,8,16]
pg 5.1c is stuck peering for 32h, current state peering, last acting [15,2]
pg 5.1d is stuck peering for 14h, current state peering, last acting [9,17]
pg 5.1e is stuck peering for 14h, current state peering, last acting [7,15]
pg 5.1f is stuck peering for 14h, current state peering, last acting [11,23]
pg 6.12 is stuck peering for 14h, current state peering, last acting [13,10,20]
pg 6.13 is stuck peering for 14h, current state peering, last acting [20,23,16]
pg 6.1c is stuck peering for 14h, current state peering, last acting [14,23,5]
pg 6.1d is stuck peering for 14h, current state peering, last acting [8,22]
pg 6.1e is down, acting [23,13]
pg 6.1f is stuck peering for 13h, current state peering, last acting [3,20,11]
pg 7.10 is stuck inactive for 14h, current state peering, last acting [22,20,16]
pg 7.12 is stuck peering for 13h, current state peering, last acting [2,22]
pg 7.13 is stuck peering for 14h, current state peering, last acting [18,9,14]
pg 7.1c is down, acting [15]
pg 7.1d is stuck peering for 14h, current state peering, last acting [14,20,0]
pg 7.1e is stuck peering for 14h, current state peering, last acting [1,23,8]
pg 7.1f is stuck peering for 14h, current state peering, last acting [18,15,23]
pg 8.10 is down, acting [17]
pg 8.11 is stuck peering for 32h, current state peering, last acting [10,20,15]
pg 8.12 is stuck peering for 32h, current state peering, last acting [8,22,14]
pg 8.13 is stuck peering for 14h, current state peering, last acting [23,17]
pg 8.1c is stuck peering for 14h, current state peering, last acting [18,16]
pg 8.1d is stuck peering for 14h, current state peering, last acting [6,20,13]
pg 8.1f is stuck peering for 14h, current state peering, last acting [14,23,5]
pg 9.10 is stuck peering for 114s, current state peering, last acting [11,18]
pg 9.11 is stuck peering for 12h, current state peering, last acting [23]
pg 9.12 is stuck peering for 5h, current state peering, last acting [20,13]
pg 9.13 is stuck peering for 3m, current state peering, last acting [16,23]
pg 9.1c is stuck peering for 12m, current state peering, last acting [23,16]
pg 9.1d is stuck peering for 44m, current state peering, last acting [13,20]
pg 9.1e is stuck peering for 11m, current state peering, last acting [6,7]
Code:
HEALTH_WARN: Degraded data redundancy: 2/14449 objects degraded (0.014%), 2 pgs degraded, 3 pgs undersized
pg 6.e is activating+undersized+degraded, acting [8,1]
pg 9.14 is stuck undersized for 4m, current state undersized+peered, last acting [1]
pg 9.19 is stuck undersized for 4m, current state undersized+peered, last acting [3]
pg 9.1f is stuck undersized for 4m, current state undersized+degraded+peered, last acting [6]
Code:
HEALTH_WARN: 337 slow ops, oldest one blocked for 21260 sec, daemons [osd.0,osd.13,osd.14,osd.17,osd.18,osd.20,osd.22,osd.23,osd.3,mon.creepified]... have slow ops.I have attached photos of my network user interface for each node, as well as the storage user interface. I am most likely neglecting some small, but significant part of the configuration, and I hope I'm not making myself out to be too much of an imbecile. I would greatly appreciate any guidance on setting this up correctly, rather than reverting back to the basic setup. Thank you for taking the time to read this. Merry Christmas.
Attachments
-
 Screenshot 2024-12-25 080500.png86.6 KB · Views: 10
Screenshot 2024-12-25 080500.png86.6 KB · Views: 10 -
 Screenshot 2024-12-25 080435.png51.8 KB · Views: 9
Screenshot 2024-12-25 080435.png51.8 KB · Views: 9 -
 Screenshot 2024-12-25 080427.png52.1 KB · Views: 9
Screenshot 2024-12-25 080427.png52.1 KB · Views: 9 -
 Screenshot 2024-12-25 080416.png51.8 KB · Views: 9
Screenshot 2024-12-25 080416.png51.8 KB · Views: 9 -
 Screenshot 2024-12-25 080351.png61 KB · Views: 9
Screenshot 2024-12-25 080351.png61 KB · Views: 9 -
 Screenshot 2024-12-25 080342.png52.3 KB · Views: 9
Screenshot 2024-12-25 080342.png52.3 KB · Views: 9 -
 Screenshot 2024-12-25 080242.png53.4 KB · Views: 10
Screenshot 2024-12-25 080242.png53.4 KB · Views: 10
