Hi,
till last Wednesday we had a cute high performing litte CEPH cluster running on PVE 6.4. Then i started the upgrade to Octopus as given in https://pve.proxmox.com/wiki/Ceph_Nautilus_to_Octopus. Since we did an online upgrade, we stopped the autoconvert with
but followed this up step by step by restarting one OSD after the other.
Our Setup is
5 x Storage Node, each : 16 x 2.3GHz, 64GB RAM, 1 x SSD OSD 1.6TB, 1 x 7.68TB (Both WD Enterprise, SAS-12), 3 HDD OSD (10TB, SAS-12) with Optane Cache)
4 x Compute Nodes
40 GE Storage network
10 GE Cluster/Mgmt Network
Our performance before the upgrade, Ceph 14.2.22 (about 36k IOPS on the SSD Pool)
Our performance after the update CEPH 15.2.15 (drops to max 17k IOPS on the SSD Pool)
What we have done so far (no success)
- reformat two of the SSD OSD's (one was still from luminos, non LVM)
- set bluestore_allocator from hybrid back to bitmap
- set osd_memory_target to 6442450944 for some of the SSD OSDs
- cpupower idle-set -D 11
- bluefs_buffered_io to true (even though i just see its not relevant for RBD)
- disabled default firewalls between CEPH nodes (for testing only)
- disabled apparmor
What we observe
- HDD Pool has similar behaviour
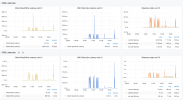
- load is higher since update, seems like more CPU consumption (see graph1), migration was on 10. Nov, around 10pm
- latency on the "big" 7TB SSD's (OSD.15) is significantly higher than on the small 1.6TB SSDs (OSD.12), see graph2
- load of OSD.15 is 4 times higher than load of OSD.12 (due to the size??)
- start of OSD.15 (the 7TB SSD's is significantly slower (~10 sec) compared to the 1.6TB SSDs
Right now we are a bit helpless, any suggestions and / or does someone else has similar experiences?
Thanks,
Kai
till last Wednesday we had a cute high performing litte CEPH cluster running on PVE 6.4. Then i started the upgrade to Octopus as given in https://pve.proxmox.com/wiki/Ceph_Nautilus_to_Octopus. Since we did an online upgrade, we stopped the autoconvert with
Code:
ceph config set osd bluestore_fsck_quick_fix_on_mount falsebut followed this up step by step by restarting one OSD after the other.
Our Setup is
5 x Storage Node, each : 16 x 2.3GHz, 64GB RAM, 1 x SSD OSD 1.6TB, 1 x 7.68TB (Both WD Enterprise, SAS-12), 3 HDD OSD (10TB, SAS-12) with Optane Cache)
4 x Compute Nodes
40 GE Storage network
10 GE Cluster/Mgmt Network
Our performance before the upgrade, Ceph 14.2.22 (about 36k IOPS on the SSD Pool)
Code:
### SSD Pool on 40GE Switches
# rados bench -p SSD 30 -t 256 -b 1024 write
hints = 1
Maintaining 256 concurrent writes of 1024 bytes to objects of size 1024 for up to 30 seconds or 0 objects
...
Total time run: 30.004
Total writes made: 1094320
Write size: 1024
Object size: 1024
Bandwidth (MB/sec): 35.6177
Stddev Bandwidth: 4.71909
Max bandwidth (MB/sec): 40.7314
Min bandwidth (MB/sec): 21.3037
Average IOPS: 36472
Stddev IOPS: 4832.35
Max IOPS: 41709
Min IOPS: 21815
Average Latency(s): 0.00701759
Stddev Latency(s): 0.00854068
Max latency(s): 0.445397
Min latency(s): 0.000909089
Cleaning up (deleting benchmark objects)Our performance after the update CEPH 15.2.15 (drops to max 17k IOPS on the SSD Pool)
Code:
# rados bench -p SSD 30 -t 256 -b 1024 write
hints = 1
Maintaining 256 concurrent writes of 1024 bytes to objects of size 1024 for up to 30 seconds or 0 objects
...
Total time run: 30.0146
Total writes made: 468513
Write size: 1024
Object size: 1024
Bandwidth (MB/sec): 15.2437
Stddev Bandwidth: 0.78677
Max bandwidth (MB/sec): 16.835
Min bandwidth (MB/sec): 13.3184
Average IOPS: 15609
Stddev IOPS: 805.652
Max IOPS: 17239
Min IOPS: 13638
Average Latency(s): 0.016396
Stddev Latency(s): 0.00777054
Max latency(s): 0.140793
Min latency(s): 0.00106735
Cleaning up (deleting benchmark objects)What we have done so far (no success)
- reformat two of the SSD OSD's (one was still from luminos, non LVM)
- set bluestore_allocator from hybrid back to bitmap
- set osd_memory_target to 6442450944 for some of the SSD OSDs
- cpupower idle-set -D 11
- bluefs_buffered_io to true (even though i just see its not relevant for RBD)
- disabled default firewalls between CEPH nodes (for testing only)
- disabled apparmor
What we observe
- HDD Pool has similar behaviour
- load is higher since update, seems like more CPU consumption (see graph1), migration was on 10. Nov, around 10pm
- latency on the "big" 7TB SSD's (OSD.15) is significantly higher than on the small 1.6TB SSDs (OSD.12), see graph2
- load of OSD.15 is 4 times higher than load of OSD.12 (due to the size??)
- start of OSD.15 (the 7TB SSD's is significantly slower (~10 sec) compared to the 1.6TB SSDs
Right now we are a bit helpless, any suggestions and / or does someone else has similar experiences?
Thanks,
Kai
Attachments

Last edited:




