Please note that after an upgrade of a cluster from Octopus to Reef (18.2.0), which has been running since PVE 5.4, we've seen issues with this Ceph version. We seem to be hitting bugs where the OSD is unable to (quickly) find aligned 64k blocks for rocksdb. This has been fixed in 18.2.1 (by removing the requirement for the 64k block to be aligned: https://github.com/ceph/ceph/pull/54772).
If you are suffering from this, it helps if you add more OSD's so that there is more free space available. It also helps to offline compact your kv-store. We see quite a few 'laggy' pgs since the upgrade. The first night (before adding disks and compacting the kv-store) was horrible, with OSD's being flagged down because they were too slow.
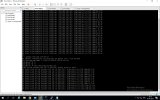
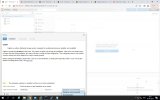
You might notice the following log messages:
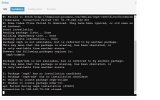
We've done offline compactation by running:
Please keep your failure domain in mind before taking OSD's offline!
If you are suffering from this, it helps if you add more OSD's so that there is more free space available. It also helps to offline compact your kv-store. We see quite a few 'laggy' pgs since the upgrade. The first night (before adding disks and compacting the kv-store) was horrible, with OSD's being flagged down because they were too slow.
You might notice the following log messages:
Code:
bluestore(/var/lib/ceph/osd/ceph-3) log_latency_fn slow operation observed for _txc_committed_kv, latency = 6.574412823s, txc = 0x55ddf99bd500We've done offline compactation by running:
Code:
ceph osd set noout
systemctl stop ceph-osd@$id
ceph-kvstore-tool bluestore-kv /var/lib/ceph/osd/ceph-$id/ compact
systemctl start ceph-osd@$id
ceph osd unset nooutPlease keep your failure domain in mind before taking OSD's offline!