Hello,
I want to understand if I am reaching a bottleneck in my hyperconverged Proxmox+ Ceph cluster.
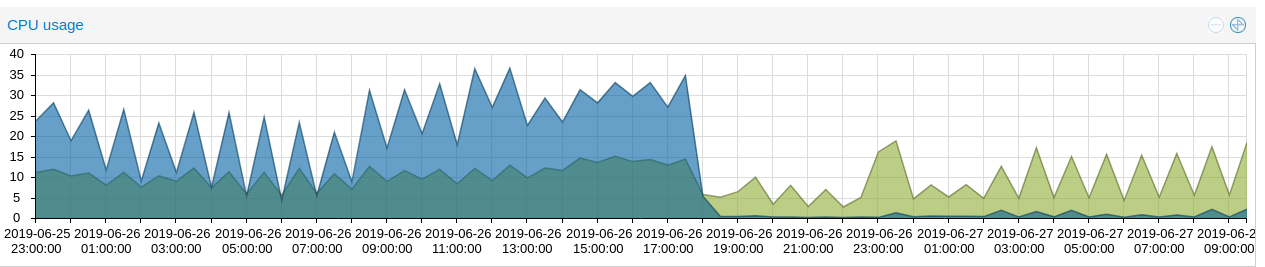
In moments of high load (multiple LXC with high I/O on small files) I see one node with:
- IO delay at 40%
- around 50% CPU usage
- load at 200 (40 total cores / 2 x Intel(R) Xeon CPU E5-2660 v3 @ 2.60GHz)
- Cpu cores assigned to Ceph OSD daemon > 100%
- Ceph writing around 30 MB/s
The disks are Intel S3520 (12 OSD / 6 nodes)
Iostat output has moments showing 100% usage:
What does it mean 100% on rbdX devices but low value on sda/sdb ?
Am I hitting both OSD CPU and disk throughput limit?
I see both ceph-osd are running on the same core. Is it possible to assign osd daemons to separate cores?
Any suggestions for optimisations?
Thank you,
P.
I want to understand if I am reaching a bottleneck in my hyperconverged Proxmox+ Ceph cluster.
In moments of high load (multiple LXC with high I/O on small files) I see one node with:
- IO delay at 40%
- around 50% CPU usage
- load at 200 (40 total cores / 2 x Intel(R) Xeon CPU E5-2660 v3 @ 2.60GHz)
- Cpu cores assigned to Ceph OSD daemon > 100%
- Ceph writing around 30 MB/s
The disks are Intel S3520 (12 OSD / 6 nodes)
Iostat output has moments showing 100% usage:
avg-cpu: %user %nice %system %iowait %steal %idle
22.29 0.00 7.62 36.19 0.00 33.90
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdc 0.00 27.50 21.00 54.50 40.50 9574.00 254.69 0.01 0.11 0.19 0.07 0.11 0.80
sda 0.50 48.00 34.50 952.50 204.00 10768.00 22.23 0.22 0.22 0.35 0.22 0.11 10.60
sdb 0.00 75.00 35.00 945.50 210.00 12916.00 26.77 0.34 0.34 0.23 0.35 0.11 10.60
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 50.00 0.00 9574.00 382.96 0.00 0.04 0.00 0.04 0.04 0.20
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd0 0.00 111.00 1.50 32.00 18.00 876.00 53.37 5.84 210.33 1.33 220.12 29.85 100.00
rbd1 0.00 69.00 1.00 18.00 12.00 446.00 48.21 6.56 392.95 0.00 414.78 50.74 96.40
rbd2 0.00 87.00 0.00 64.50 0.00 702.00 21.77 13.81 209.05 0.00 209.05 15.47 99.80
rbd3 0.00 17.00 0.00 10.00 0.00 110.00 22.00 1.00 121.00 0.00 121.00 70.80 70.80
rbd4 0.00 48.00 0.00 8.50 0.00 332.00 78.12 3.86 620.00 0.00 620.00 117.65 100.00
rbd5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd6 0.00 30.00 0.00 35.50 0.00 304.00 17.13 17.18 666.08 0.00 666.08 28.17 100.00
rbd7 0.00 86.50 0.00 63.00 0.00 870.00 27.62 20.20 475.68 0.00 475.68 15.87 100.00
rbd8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd9 0.00 58.00 0.00 14.50 0.00 490.00 67.59 5.63 490.62 0.00 490.62 68.00 98.60
rbd10 0.00 3.50 0.00 4.50 0.00 42.00 18.67 1.62 963.11 0.00 963.11 131.11 59.00
rbd11 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.15 864.00 0.00 864.00 308.00 15.40
rbd12 0.00 81.50 0.00 7.50 0.00 356.00 94.93 1.43 194.40 0.00 194.40 124.27 93.20
rbd13 0.00 1.50 0.00 1.50 0.00 12.00 16.00 0.16 289.33 0.00 289.33 104.00 15.60
rbd14 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.00 4.00 0.00 4.00 4.00 0.20
rbd15 0.00 31.50 0.00 8.50 0.00 240.00 56.47 2.80 328.24 0.00 328.24 110.35 93.80
rbd16 0.00 55.00 2.00 22.00 14.00 402.00 34.67 5.08 227.17 18.00 246.18 41.67 100.00
rbd17 0.00 123.00 0.00 32.50 0.00 818.00 50.34 6.45 193.23 0.00 193.23 30.77 100.00
rbd18 0.00 72.50 0.00 25.50 0.00 432.00 33.88 9.48 329.02 0.00 329.02 39.22 100.00
rbd19 0.00 90.00 0.00 26.50 0.00 638.00 48.15 8.15 474.19 0.00 474.19 37.51 99.40
rbd20 0.00 87.00 0.50 19.00 6.00 438.00 45.54 7.65 483.59 0.00 496.32 48.92 95.40
rbd21 0.00 2.50 0.00 2.00 0.00 18.00 18.00 0.03 17.00 0.00 17.00 17.00 3.40
rbd22 0.00 28.00 0.50 13.50 2.00 310.00 44.57 8.24 322.57 4.00 334.37 71.43 100.00
rbd23 0.00 179.50 0.50 44.50 14.00 1194.00 53.69 2.58 64.18 0.00 64.90 17.91 80.60
rbd24 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.21 460.00 0.00 460.00 416.00 20.80
rbd25 0.00 19.00 0.00 2.50 0.00 76.00 60.80 1.65 456.00 0.00 456.00 400.00 100.00
rbd26 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.15 864.00 0.00 864.00 308.00 15.40
rbd27 0.00 1.50 0.00 1.00 0.00 10.00 20.00 0.45 446.00 0.00 446.00 446.00 44.60
rbd28 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd29 0.00 0.50 0.00 1.00 0.00 6.00 12.00 0.01 10.00 0.00 10.00 10.00 1.00
rbd30 0.00 0.50 0.00 1.00 0.00 6.00 12.00 0.06 62.00 0.00 62.00 62.00 6.20
rbd31 0.00 71.00 0.00 24.00 0.00 406.00 33.83 3.85 179.08 0.00 179.08 41.67 100.00
22.29 0.00 7.62 36.19 0.00 33.90
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdc 0.00 27.50 21.00 54.50 40.50 9574.00 254.69 0.01 0.11 0.19 0.07 0.11 0.80
sda 0.50 48.00 34.50 952.50 204.00 10768.00 22.23 0.22 0.22 0.35 0.22 0.11 10.60
sdb 0.00 75.00 35.00 945.50 210.00 12916.00 26.77 0.34 0.34 0.23 0.35 0.11 10.60
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 50.00 0.00 9574.00 382.96 0.00 0.04 0.00 0.04 0.04 0.20
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd0 0.00 111.00 1.50 32.00 18.00 876.00 53.37 5.84 210.33 1.33 220.12 29.85 100.00
rbd1 0.00 69.00 1.00 18.00 12.00 446.00 48.21 6.56 392.95 0.00 414.78 50.74 96.40
rbd2 0.00 87.00 0.00 64.50 0.00 702.00 21.77 13.81 209.05 0.00 209.05 15.47 99.80
rbd3 0.00 17.00 0.00 10.00 0.00 110.00 22.00 1.00 121.00 0.00 121.00 70.80 70.80
rbd4 0.00 48.00 0.00 8.50 0.00 332.00 78.12 3.86 620.00 0.00 620.00 117.65 100.00
rbd5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd6 0.00 30.00 0.00 35.50 0.00 304.00 17.13 17.18 666.08 0.00 666.08 28.17 100.00
rbd7 0.00 86.50 0.00 63.00 0.00 870.00 27.62 20.20 475.68 0.00 475.68 15.87 100.00
rbd8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd9 0.00 58.00 0.00 14.50 0.00 490.00 67.59 5.63 490.62 0.00 490.62 68.00 98.60
rbd10 0.00 3.50 0.00 4.50 0.00 42.00 18.67 1.62 963.11 0.00 963.11 131.11 59.00
rbd11 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.15 864.00 0.00 864.00 308.00 15.40
rbd12 0.00 81.50 0.00 7.50 0.00 356.00 94.93 1.43 194.40 0.00 194.40 124.27 93.20
rbd13 0.00 1.50 0.00 1.50 0.00 12.00 16.00 0.16 289.33 0.00 289.33 104.00 15.60
rbd14 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.00 4.00 0.00 4.00 4.00 0.20
rbd15 0.00 31.50 0.00 8.50 0.00 240.00 56.47 2.80 328.24 0.00 328.24 110.35 93.80
rbd16 0.00 55.00 2.00 22.00 14.00 402.00 34.67 5.08 227.17 18.00 246.18 41.67 100.00
rbd17 0.00 123.00 0.00 32.50 0.00 818.00 50.34 6.45 193.23 0.00 193.23 30.77 100.00
rbd18 0.00 72.50 0.00 25.50 0.00 432.00 33.88 9.48 329.02 0.00 329.02 39.22 100.00
rbd19 0.00 90.00 0.00 26.50 0.00 638.00 48.15 8.15 474.19 0.00 474.19 37.51 99.40
rbd20 0.00 87.00 0.50 19.00 6.00 438.00 45.54 7.65 483.59 0.00 496.32 48.92 95.40
rbd21 0.00 2.50 0.00 2.00 0.00 18.00 18.00 0.03 17.00 0.00 17.00 17.00 3.40
rbd22 0.00 28.00 0.50 13.50 2.00 310.00 44.57 8.24 322.57 4.00 334.37 71.43 100.00
rbd23 0.00 179.50 0.50 44.50 14.00 1194.00 53.69 2.58 64.18 0.00 64.90 17.91 80.60
rbd24 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.21 460.00 0.00 460.00 416.00 20.80
rbd25 0.00 19.00 0.00 2.50 0.00 76.00 60.80 1.65 456.00 0.00 456.00 400.00 100.00
rbd26 0.00 0.00 0.00 0.50 0.00 2.00 8.00 0.15 864.00 0.00 864.00 308.00 15.40
rbd27 0.00 1.50 0.00 1.00 0.00 10.00 20.00 0.45 446.00 0.00 446.00 446.00 44.60
rbd28 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rbd29 0.00 0.50 0.00 1.00 0.00 6.00 12.00 0.01 10.00 0.00 10.00 10.00 1.00
rbd30 0.00 0.50 0.00 1.00 0.00 6.00 12.00 0.06 62.00 0.00 62.00 62.00 6.20
rbd31 0.00 71.00 0.00 24.00 0.00 406.00 33.83 3.85 179.08 0.00 179.08 41.67 100.00
What does it mean 100% on rbdX devices but low value on sda/sdb ?
Am I hitting both OSD CPU and disk throughput limit?
I see both ceph-osd are running on the same core. Is it possible to assign osd daemons to separate cores?
Any suggestions for optimisations?
Thank you,
P.
Last edited: