Hi again,
I have my Ceph working, however i cannot seem to get the cluster working properly at all.
Cluster is losing connection at random intervals (all nodes going red-cross), and also going back to all green. I do not have a single storage volume available,while i have a NFS share, ceph-vm, ceph-lxc, LVM. Neither of those are available when restoring/creating VM's/Containers.
This is on a 3 node cluster, with 10gbe mesh for ceph. and 'just' using the standard vmbr0 for pve per default installation.
- I do have open Vswitch installed, not using it though.
- tried this 2x with clean installs on all hosts, including apt-get upgrades
- after reboot i shorly see NFS and local as storage options
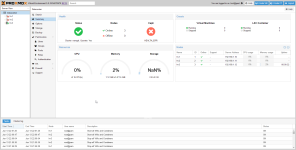
- Cluster information shows all incorrect information. each host = 48 gb and 16 cores
Screens below
Even while nodes are offline in Webgui (it still works) there still is quorum. Other hosts still ping-able as well.
journalctl -xe
I have my Ceph working, however i cannot seem to get the cluster working properly at all.
Cluster is losing connection at random intervals (all nodes going red-cross), and also going back to all green. I do not have a single storage volume available,while i have a NFS share, ceph-vm, ceph-lxc, LVM. Neither of those are available when restoring/creating VM's/Containers.
This is on a 3 node cluster, with 10gbe mesh for ceph. and 'just' using the standard vmbr0 for pve per default installation.
- I do have open Vswitch installed, not using it though.
- tried this 2x with clean installs on all hosts, including apt-get upgrades
- after reboot i shorly see NFS and local as storage options
- Cluster information shows all incorrect information. each host = 48 gb and 16 cores
Screens below
Even while nodes are offline in Webgui (it still works) there still is quorum. Other hosts still ping-able as well.
Code:
root@hv1:~# pvecm status
Quorum information
------------------
Date: Tue Jun 13 21:46:33 2017
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 0x00000001
Ring ID: 1/12
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 192.168.1.10 (local)
0x00000002 1 192.168.1.11
0x00000003 1 192.168.1.12
Code:
root@hv1:~# pveversion
pve-manager/5.0-10/0d270679 (running kernel: 4.10.11-1-pve)journalctl -xe
Code:
root@hv1:~# journalctl -xe
-- Subject: Unit rpc-statd-notify.service has finished start-up
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Unit rpc-statd-notify.service has finished starting up.
--
-- The start-up result is done.
Jun 13 21:25:20 hv1 systemd[1]: Started NFS status monitor for NFSv2/3 locking..
-- Subject: Unit rpc-statd.service has finished start-up
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Unit rpc-statd.service has finished starting up.
--
-- The start-up result is done.
Jun 13 21:25:20 hv1 kernel: FS-Cache: Loaded
Jun 13 21:25:20 hv1 kernel: FS-Cache: Netfs 'nfs' registered for caching
Jun 13 21:25:44 hv1 pveproxy[2038]: proxy detected vanished client connection
Jun 13 21:25:58 hv1 pveproxy[2036]: proxy detected vanished client connection
Jun 13 21:26:08 hv1 pveproxy[2035]: worker 2036 finished
Jun 13 21:26:08 hv1 pveproxy[2035]: starting 1 worker(s)
Jun 13 21:26:08 hv1 pveproxy[2035]: worker 11062 started
Jun 13 21:26:09 hv1 pveproxy[2037]: proxy detected vanished client connection
Jun 13 21:26:12 hv1 pveproxy[11061]: got inotify poll request in wrong process - disabling inotify
Jun 13 21:26:31 hv1 pveproxy[11061]: proxy detected vanished client connection
Jun 13 21:26:31 hv1 pveproxy[11061]: proxy detected vanished client connection
Jun 13 21:26:35 hv1 pveproxy[11061]: proxy detected vanished client connection
Jun 13 21:26:36 hv1 pveproxy[11061]: worker exit
Jun 13 21:26:38 hv1 pveproxy[2037]: proxy detected vanished client connection
Jun 13 21:26:39 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:26:59 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:27:09 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:27:39 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:28:43 hv1 pveproxy[11062]: Clearing outdated entries from certificate cache
Jun 13 21:29:01 hv1 kernel: perf: interrupt took too long (4329 > 4231), lowering kernel.perf_event_max_sample_
Jun 13 21:29:11 hv1 pveproxy[2037]: proxy detected vanished client connection
Jun 13 21:29:11 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:29:12 hv1 pmxcfs[2407]: [status] notice: received log
Jun 13 21:29:13 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:29:16 hv1 pvestatd[1716]: status update time (300.150 seconds)
Jun 13 21:29:17 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:34:22 hv1 rrdcached[1465]: flushing old values
Jun 13 21:34:22 hv1 rrdcached[1465]: rotating journals
Jun 13 21:34:22 hv1 rrdcached[1465]: started new journal /var/lib/rrdcached/journal/rrd.journal.1497382462.2513
Jun 13 21:38:28 hv1 pmxcfs[2407]: [dcdb] notice: data verification successful
Jun 13 21:39:16 hv1 pvestatd[1716]: status update time (600.133 seconds)
Jun 13 21:41:17 hv1 kernel: perf: interrupt took too long (5479 > 5411), lowering kernel.perf_event_max_sample_
Jun 13 21:44:09 hv1 pmxcfs[2407]: [status] notice: received log
Jun 13 21:45:31 hv1 pveproxy[2038]: proxy detected vanished client connection
Jun 13 21:46:01 hv1 pveproxy[11062]: proxy detected vanished client connection
Jun 13 21:46:12 hv1 pmxcfs[2407]: [status] notice: received log
Jun 13 21:49:16 hv1 pvestatd[1716]: status update time (600.152 seconds)Attachments
Last edited: