Bestehendes Proxmox von NoName 512GB SSD auf eine Samsung 980 PRO NVMe M.2 SSD, 1 TB SSD umziehen.
- Thread starter distanzcheck
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Naja, der Default ist ja wie folgt:
Also wird an jeden ersten Sontag im Monat getrimmt und an jeden Zweiten gescrubt. Warum willst du denn von Default abweichen? Solange du da keinen guten Grund für hast, würde ich es lassen. Der scrub-Prozess prüft, ob die Daten korrekt gelesen werden können und stellt (sofern die Platten in einen Mirror oder RAIDZ liegen) ggf. defekte Daten wieder her: https://klarasystems.com/articles/understanding-zfs-scrubs-and-data-integrity/ Er ist somit auch ein Indikator für möglicherweise defekte Platten, beim Auftreten eines Fehlers in Scrub sollte man als nächstes einen S.M.A.R.T-Test laufen lassen: https://www.thomas-krenn.com/de/wiki/SMART_Tests_mit_smartctl#Verfügbare_Tests
https://docs.linuxfabrik.ch/base/filesystem/disk-smart.html
Da dafür alle Daten eingelesen werden müssen, sorgt das für entsprechend mehr Last auf den Platten/SSDs mit entsprechender Folge für die Performance")
zfs trim hingegen ist dafür da den durch Daten belegten Platz nach den Löschen wieder freizugeben (das passiert standardmäßig nicht automatisch, das kann man zwar ändern, sollte man aber nicht, da das mehr Last erzeugt und sich entsprechend in der Performance bemerkbar macht: https://forum.proxmox.com/threads/p...uilt-in-trim-cron-job-vs-zfs-autotrim.114943/ )
https://openzfs.github.io/openzfs-docs/man/master/8/zpool-trim.8.html
Je nach Paranoiagrad oder wie oft man Daten löscht beide Jobs auch öfter laufen lassen, wenn einen ein monatlicher Check/Trim zu wenig ist, aber solange man selbst keinen Grund nennen kann, würde ich das nicht tun. Und nicht falsch verstehen: Paranoia ist durchaus ein legitimer Grund, aber man sollte sich halt vorher überlegen, warum man das eigentlich macht. Siehe dazu auch folgende Diskussion auf hackernews: https://news.ycombinator.com/item?id=46688149
cat /etc/cron.d/zfsutils-linux
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# TRIM the first Sunday of every month.
24 0 1-7 * * root if [ $(date +\%w) -eq 0 ] && [ -x /usr/lib/zfs-linux/trim ]; then /usr/lib/zfs-linux/trim; fi
# Scrub the second Sunday of every month.
24 0 8-14 * * root if [ $(date +\%w) -eq 0 ] && [ -x /usr/lib/zfs-linux/scrub ]; then /usr/lib/zfs-linux/scrub; fi
Also wird an jeden ersten Sontag im Monat getrimmt und an jeden Zweiten gescrubt. Warum willst du denn von Default abweichen? Solange du da keinen guten Grund für hast, würde ich es lassen. Der scrub-Prozess prüft, ob die Daten korrekt gelesen werden können und stellt (sofern die Platten in einen Mirror oder RAIDZ liegen) ggf. defekte Daten wieder her: https://klarasystems.com/articles/understanding-zfs-scrubs-and-data-integrity/ Er ist somit auch ein Indikator für möglicherweise defekte Platten, beim Auftreten eines Fehlers in Scrub sollte man als nächstes einen S.M.A.R.T-Test laufen lassen: https://www.thomas-krenn.com/de/wiki/SMART_Tests_mit_smartctl#Verfügbare_Tests
https://docs.linuxfabrik.ch/base/filesystem/disk-smart.html
Da dafür alle Daten eingelesen werden müssen, sorgt das für entsprechend mehr Last auf den Platten/SSDs mit entsprechender Folge für die Performance
zfs trim hingegen ist dafür da den durch Daten belegten Platz nach den Löschen wieder freizugeben (das passiert standardmäßig nicht automatisch, das kann man zwar ändern, sollte man aber nicht, da das mehr Last erzeugt und sich entsprechend in der Performance bemerkbar macht: https://forum.proxmox.com/threads/p...uilt-in-trim-cron-job-vs-zfs-autotrim.114943/ )
https://openzfs.github.io/openzfs-docs/man/master/8/zpool-trim.8.html
Je nach Paranoiagrad oder wie oft man Daten löscht beide Jobs auch öfter laufen lassen, wenn einen ein monatlicher Check/Trim zu wenig ist, aber solange man selbst keinen Grund nennen kann, würde ich das nicht tun. Und nicht falsch verstehen: Paranoia ist durchaus ein legitimer Grund, aber man sollte sich halt vorher überlegen, warum man das eigentlich macht. Siehe dazu auch folgende Diskussion auf hackernews: https://news.ycombinator.com/item?id=46688149

Danke für die ausführliche Antwort Johannes,
auch wenn ich jetzt auch wieder nur mir Halbwissen antworten kann, dachte ich eben mit dem wöchentlichen (statt monatlichen) trimmen würde ich die write amplification reduzieren? Da ich ja keine Enterprise NVMe habe, wollte ich möglichst schonend mit ihr umgehen. Scrub ist ja bei mir (1 NVMe) "nur" hinsichtlich der Gesundheit der NVMe interessant.
auch wenn ich jetzt auch wieder nur mir Halbwissen antworten kann, dachte ich eben mit dem wöchentlichen (statt monatlichen) trimmen würde ich die write amplification reduzieren? Da ich ja keine Enterprise NVMe habe, wollte ich möglichst schonend mit ihr umgehen. Scrub ist ja bei mir (1 NVMe) "nur" hinsichtlich der Gesundheit der NVMe interessant.
Last edited:
Danke für die ausführliche Antwort Johannes,
auch wenn ich jetzt auch wieder nur mir Halbwissen antworten kann, dachte ich eben mit dem wöchentlichen (statt monatlichen) trimmen würde ich die write amplification reduzieren? Da ich ja keine Enterprise NVMe habe, wollte ich möglichst schonend mit ihr umgehen. Scrub ist ja bei mir (1 NVMe) "nur" hinsichtlich der Gesundheit der NVMe interessant.
- zfs belastet deine HW immer mehr, als ein ext4 Basissystem. Mit nur einer NVMe ist es sogar recht sinnlos und eher Karusselbremser. Wenn unbedingt gewünscht, verpasse einzelnen VMs ein zfs.
- Sorge penibel für einen passende DATENSICHERUNG der VMs.
- Sofern diese auf einem PBS stattfindet, geht das sogar rattenschnell.
- zfs mit einem Datenträger ist ziemlich für die Katz und eher kontraproduktiv.
Ja, das ist mir grundsätzlich bewusst. Ich zitiere mich hier mal selbst:
- zfs mit einem Datenträger ist ziemlich für die Katz und eher kontraproduktiv.
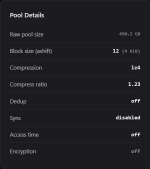
Bislang läuft mein System. Die NVMe scheint auch von den Leistungsdaten ja erstmal zu passen. Ich warte jetzt einfach mal ab. Im schlimmsten Fall verreckt mir die NVMe und im muss das ganze neu machen. Da weiß ich ja jetzt wie es geht (und auch wie es nicht gehtIch fand die Idee von der Datenkomprimierung und der Deduplizierung sehr interessant
). Dann hab ich wieder was dazu gelernt.Danke an alle, die sich Zeit für eine Antwort genommen haben!
Bitte erst mal nachschlagen, was überhaupt write amplification ist. Diese hat mir TRIM absolut nichts zu tun.trimmen würde ich die write amplification reduzieren
Warum das. Es bringt viele Features mit, man hat halt nur kein RAID. Kein RAID ist kein Verbrechen.zfs mit einem Datenträger ist ziemlich für die Katz und eher kontraproduktiv.
Ich nutze für mein privates PVE ebenfalls nur eine SSD, mit ZFS und ohne einen DRAM-Cache und PLP. Wo ist dieses Setup schlechter als mit ext4.
Attachments
Last edited:
Du erkaufst dir Features. die recht teuer sind.Warum das. Es bringt viele Features mit, man hat halt nur kein RAID. Kein RAID ist kein Verbrechen.
- anspruchsvollere HW (PLP etc.)
- anspruchsvollere, komplexere Administration
- hoher Arbeitspeicherbedarf
- noch höherer Speicherbedarf bei Deduplizierung.
- schlechtere Performance
Wenn du zfs auf nur einer Platte einsetzt, dann hast du ohne weitere, nötige Einstellungen noch nicht mal die Autokorrektur bei Datenfehlern.
Hier gibt es einige, die auf zfs schwören. Aber ich glaube nicht auf einem Einzelplattensystem.
Last edited:
Du hast ja teilweise recht, aber einen einzigen kurzen Befehl wieWenn du zfs auf nur einer Platte einsetzt, dann hast du ohne weitere "Tricks" noch nicht mal die Autokorrektur bei Datenfehlern.
zfs set copies=2 rpool/data als "weitere Tricks" zu bezeichnen drängt mich zu dieser Antwort... ;-) Vielleicht meinst du auch etwas anderes?(( Der Befehl hat negative Auswirkungen hinsichtlich Performance, erhöht natürlich die Schreiblast und ist eigentlich nur für HDD sinnvoll, weil die meist langsam sterben. SSD/NVMe starben bei mir eigentlich immer komplett - von einer Sekunde zur nächsten. ))
Dass alles weg ist, wenn der einzige Datenträger komplett ausfällt, ist ja sowieso klar - egal, welches Filesystem man verwendet.
Ich bin völlig bei dir. Habe "Tricks" nun gegen passenderes ersetzt.Du hast ja teilweise recht, aber einen einzigen kurzen Befehl wiezfs set copies=2 rpool/dataals "weitere Tricks" zu bezeichnen drängt mich zu dieser Antwort... ;-) Vielleicht meinst du auch etwas anderes?
(( Der Befehl hat negative Auswirkungen hinsichtlich Performance, erhöht natürlich die Schreiblast und ist eigentlich nur für HDD sinnvoll, weil die meist langsam sterben. SSD/NVMe starben bei mir eigentlich immer komplett - von einer Sekunde zur nächsten. ))
Dass alles weg ist, wenn der einzige Datenträger komplett ausfällt, ist ja sowieso klar - egal, welches Filesystem man verwendet.
Nope, wie gesagt, läuft auch ohne
- anspruchsvollere HW (PLP etc.)
Einmal angefasst und dann nicht wieder
- anspruchsvollere, komplexere Administration
Ok, lässt sicher aber konfigurieren und somit mindern
- hoher Arbeitspeicherbedarf
Deduplizierung nutze ich nicht
- noch höherer Speicherbedarf bei Deduplizierung.
Performance ist für einen Virtualisierer mehr als ausreichend. Teuer erkauft ist da nichts, außer der RAM. Ich halte den ARC eher klein, da ich mir bei einer SSD davon ohnehin nichts verspreche. Wenn ich könnte, würde ich ihn ausschließlich für ZFS-Metadaten nutzen.
- schlechtere Performance
Na dann ziehe 10 mal brutal den Stecker, während Last auf der Mühle liegt.Nope, wie gesagt, läuft auch ohne
Oder beobachte mal über längeren Zeitraum wie sich deine 0815-NVMe präsentiert.
Ist natürlich komplett dein Bier, wenn du riesen Vorteile in zfs ggü. einem journaling ext4 siehst.
Extrem witzig finde ich:
Einmal angefasst und dann nicht wieder
Du suchstIch halte den ARC eher klein, da ich mir bei einer SSD davon ohnehin nichts verspreche. Wenn ich könnte, würde ich ihn ausschließlich für ZFS-Metadaten nutzen.
zfs set primarycache=metadata rpool/data ?man zfsprops hat die (kurze) Beschreibung.Danke, werd ich mal probieren und gucken, ob der Cache-Bedarf auch abnimmt.Du suchstzfs set primarycache=metadata
Ich würde
primarycache Standard lassen und eher zfs_arc_meta_balance und ähnliche empfehlen. Eventuell vorher zuerst ein paar Infos einholen
Bash:
zarcsummary -s arc
zarcsummary -s archits
Last edited:
Dann bin ich mal so frei.Ich würde eherzfs_arc_meta_balanceund ähnliche empfehlen. Eventuell vorher zuerst ein paar Infos einholen
Bash:zarcsummary -s arc zarcsummary -s archits
Code:
zarcsummary -s arc
------------------------------------------------------------------------
ZFS Subsystem Report Mon Jun 22 07:40:36 2026
Linux 7.0.12-1-pve 2.4.2-pve1
Machine: pve (x86_64) 2.4.2-pve1
ARC status:
Total memory size: 15.6 GiB
Min target size: 3.1 % 499.7 MiB
Max target size: 6.4 % 1.0 GiB
Target size (adaptive): 79.9 % 1.0 GiB
Current size: 79.9 % 817.8 MiB
Free memory size: 4.6 GiB
Available memory size: 4.0 GiB
ARC structural breakdown (current size): 817.8 MiB
Compressed size: 45.7 % 374.0 MiB
Overhead size: 26.0 % 212.6 MiB
Bonus size: 5.0 % 40.9 MiB
Dnode size: 15.3 % 125.4 MiB
Dbuf size: 6.1 % 50.3 MiB
Header size: 1.3 % 10.5 MiB
L2 header size: 0.0 % 0 Bytes
ABD chunk waste size: 0.5 % 4.1 MiB
ARC types breakdown (compressed + overhead): 586.7 MiB
Data size: 53.5 % 314.1 MiB
Metadata size: 46.5 % 272.6 MiB
ARC states breakdown (compressed + overhead): 586.7 MiB
Anonymous data size: 7.1 % 41.9 MiB
Anonymous metadata size: 0.1 % 661.0 KiB
MFU data target: 28.0 % 164.2 MiB
MFU data size: 19.5 % 114.6 MiB
MFU evictable data size: 18.5 % 108.8 MiB
MFU ghost data size: 88.4 MiB
MFU metadata target: 41.5 % 243.3 MiB
MFU metadata size: 25.1 % 147.5 MiB
MFU evictable metadata size: 3.5 % 20.7 MiB
MFU ghost metadata size: 38.3 MiB
MRU data target: 21.5 % 126.2 MiB
MRU data size: 26.8 % 157.5 MiB
MRU evictable data size: 22.8 % 133.8 MiB
MRU ghost data size: 92.5 MiB
MRU metadata target: 9.0 % 53.0 MiB
MRU metadata size: 21.2 % 124.4 MiB
MRU evictable metadata size: 9.7 % 57.1 MiB
MRU ghost metadata size: 141.2 MiB
Uncached data size: < 0.1 % 152.0 KiB
Uncached metadata size: < 0.1 % 40.0 KiB
ARC hash breakdown:
Elements: 44.1k
Collisions: 178.9k
Chain max: 3
Chains: 419
ARC misc:
Uncompressed size: 419.4 % 1.5 GiB
Memory throttles: 0
Memory direct reclaims: 0
Memory indirect reclaims: 0
Deleted: 1.9M
Mutex misses: 29.9k
Eviction skips: 8.5M
Eviction skips due to L2 writes: 0
L2 cached evictions: 0 Bytes
L2 eligible evictions: 98.4 GiB
L2 eligible MFU evictions: 9.3 % 9.2 GiB
L2 eligible MRU evictions: 90.7 % 89.3 GiB
L2 ineligible evictions: 12.4 GiB
Code:
zarcsummary -s archits
------------------------------------------------------------------------
ZFS Subsystem Report Mon Jun 22 07:41:51 2026
Linux 7.0.12-1-pve 2.4.2-pve1
Machine: pve (x86_64) 2.4.2-pve1
ARC total accesses: 130.4M
Total hits: 98.2 % 128.0M
Total I/O hits: 0.1 % 117.2k
Total misses: 1.8 % 2.3M
ARC demand data accesses: 17.2 % 22.5M
Demand data hits: 98.0 % 22.0M
Demand data I/O hits: < 0.1 % 1.9k
Demand data misses: 2.0 % 456.4k
ARC demand metadata accesses: 78.0 % 101.8M
Demand metadata hits: 98.9 % 100.6M
Demand metadata I/O hits: < 0.1 % 10.5k
Demand metadata misses: 1.1 % 1.1M
ARC prefetch data accesses: 0.6 % 828.6k
Prefetch data hits: 37.9 % 313.7k
Prefetch data I/O hits: < 0.1 % 11
Prefetch data misses: 62.1 % 515.0k
ARC prefetch metadata accesses: 4.1 % 5.3M
Prefetch metadata hits: 94.7 % 5.1M
Prefetch metadata I/O hits: 2.0 % 104.8k
Prefetch metadata misses: 3.3 % 177.6k
ARC predictive prefetches: 88.8 % 5.5M
Demand hits after predictive: 15.5 % 851.3k
Demand I/O hits after predictive: 0.2 % 10.7k
Never demanded after predictive: 84.3 % 4.6M
ARC prescient prefetches: 11.2 % 693.5k
Demand hits after prescient: 90.0 % 624.4k
Demand I/O hits after prescient: 0.3 % 1.8k
Never demanded after prescient: 9.7 % 67.3k
ARC states hits of all accesses:
Most frequently used (MFU): 90.9 % 118.6M
Most recently used (MRU): 7.0 % 9.1M
Most frequently used (MFU) ghost: 0.1 % 121.5k
Most recently used (MRU) ghost: < 0.1 % 48.1k
Uncached: 0.2 % 325.9k