Hi, I'm fairly new to Proxmox and only just set up my first actual cluster made of 3 PCs/nodes.
Everything seemed to be working fine and showed up correctly and I started to set up Ceph for a shared storage.
I gave all 3 PCs an extra physical SSD for the shared storage additional to the Proxmox NVMe and installed Ceph on all 3 nodes.
Then I created the 3 OSDs with the SSDs, one per node. They all show green and up/in.
Then I created a pool, which immediately showed up below all 3 nodes on the left after refreshing.
After that I created 3 Monitors, one for each pool and they all show status running.
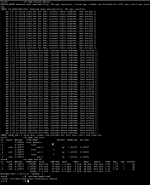
I was expecting it to be done and working but when I clicked on the Ceph overview, it showed status HEALTH_WARN.
The summary has two reports:
- Reduced data availability: 128 pgs inactive
- 3 slow ops, oldest one blocked for 2337 sec, osd.1 has slow ops
Before I wrote this post, the second one said 2 slow ops.
(update edit: it is now at 4)


Does anyone have an idea what the issue could be? Any help appreciated and feel free to ask if more details are needed for a troubleshoot!
---!UPDATE: SOLVED!---
Apparently the SATA port for the ceph SSD on node 2 (osd.1) had issues but was still intact enough to show the ssd in the system and create an OSD. I don't know if the port was partially broken or if it just had a loose contact, the whole thing behaved strangely anyway. When I plugged it into a different port, it didn't show the SSD at all at first but then it randomly showed up and worked.
So if someone with a similar issue - where the whole setup seems to be right but still gets a health warn - finds this thread, it might be a hardware related issue. Track down the whole troubleshooting route, even on the parts you'd rule out by logic.
Everything seemed to be working fine and showed up correctly and I started to set up Ceph for a shared storage.
I gave all 3 PCs an extra physical SSD for the shared storage additional to the Proxmox NVMe and installed Ceph on all 3 nodes.
Then I created the 3 OSDs with the SSDs, one per node. They all show green and up/in.
Then I created a pool, which immediately showed up below all 3 nodes on the left after refreshing.
After that I created 3 Monitors, one for each pool and they all show status running.
I was expecting it to be done and working but when I clicked on the Ceph overview, it showed status HEALTH_WARN.
The summary has two reports:
- Reduced data availability: 128 pgs inactive
- 3 slow ops, oldest one blocked for 2337 sec, osd.1 has slow ops
Before I wrote this post, the second one said 2 slow ops.
(update edit: it is now at 4)
Does anyone have an idea what the issue could be? Any help appreciated and feel free to ask if more details are needed for a troubleshoot!
---!UPDATE: SOLVED!---
Apparently the SATA port for the ceph SSD on node 2 (osd.1) had issues but was still intact enough to show the ssd in the system and create an OSD. I don't know if the port was partially broken or if it just had a loose contact, the whole thing behaved strangely anyway. When I plugged it into a different port, it didn't show the SSD at all at first but then it randomly showed up and worked.
So if someone with a similar issue - where the whole setup seems to be right but still gets a health warn - finds this thread, it might be a hardware related issue. Track down the whole troubleshooting route, even on the parts you'd rule out by logic.
Last edited:





")