Hi I have upgrade my old proxmox server (an atom C2550 cpu) to an intel Xeon CPU. Specifically I have a now
I am running the latest proxmox version on top of debian 12 and I have 4 VMs running. I have a remote storage option for taking backups every night that is running on another machine on my network.
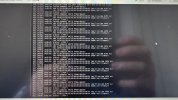
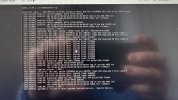
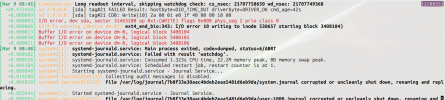
Everything runs smoothly until I try to do some IO intensive task on the server like restore a VM on the disk (backup on the remote storage works fine thought). Even if I leave the server alone and leave the restore to proceed (from remote backup to local disk) all the VMs will start spitting IO errors on their console and on their kernel "dmesg -wH" shell until the restore is completed (please see pictures).
If I try to check the server during that time there is NO error on its console or in the kernel messages but it is getting slower to a halt on the disk resquests. After that the server returns to normal but the VMs need either a reboot or also a restore since their disk could get corrupted in the process.
So far I have check the hard disk for for issues using the smartctl command but found no issues (that I can tell).
I have also try,
1) change SATA cable for the hard disk
2) change port on the motherboard
3) check if there is some visual issue on the motherboard or on disk that is preventing the cable for sitting correctly or there is some (visual) fault
4) upgrade the IPMI and BIOS to the latest version
5) checked bios settings if there is something related
Could this be something related to compatibility of my hardware with linux? Or could this be the hard disk being too slow that is causing this issues? I am asking this because I used slower disk in proxmox before and never had issues but the combination of slow ssd could be the culprit?
The same VMs (with the same hardware options) run just fine on my old machine so I am running out of ideas what to try next. Doe someone have any any other idea about what I could try or what could the issue?
Thanks
Phanos
Code:
1) Supermicro X11SSM-F motherboard,
2) Intel xeon E3-2145L v5 CPU
3) 64 GB ram
4) 512 SSD disk (CT500BX500SSD1) -- I know this disk is dramless and it is not fast but I am not sure if this is the issue.I am running the latest proxmox version on top of debian 12 and I have 4 VMs running. I have a remote storage option for taking backups every night that is running on another machine on my network.
Everything runs smoothly until I try to do some IO intensive task on the server like restore a VM on the disk (backup on the remote storage works fine thought). Even if I leave the server alone and leave the restore to proceed (from remote backup to local disk) all the VMs will start spitting IO errors on their console and on their kernel "dmesg -wH" shell until the restore is completed (please see pictures).
If I try to check the server during that time there is NO error on its console or in the kernel messages but it is getting slower to a halt on the disk resquests. After that the server returns to normal but the VMs need either a reboot or also a restore since their disk could get corrupted in the process.
So far I have check the hard disk for for issues using the smartctl command but found no issues (that I can tell).
Code:
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.8.12-8-pve] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: CT500BX500SSD1
Serial Number: 2448E9972018
LU WWN Device Id: 5 00a075 1e9972018
Firmware Version: M6CR061
User Capacity: 500,107,862,016 bytes [500 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
TRIM Command: Available
Device is: Not in smartctl database 7.3/5319
ATA Version is: ACS-3 T13/2161-D revision 4
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun Mar 9 11:21:09 2025 EET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Unavailable
APM feature is: Unavailable
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
Wt Cache Reorder: Unavailable
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 120) seconds.
Offline data collection
capabilities: (0x11) SMART execute Offline immediate.
No Auto Offline data collection support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
No Selective Self-test supported.
SMART capabilities: (0x0002) Does not save SMART data before
entering power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 10) minutes.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 100 100 000 - 0
5 Reallocated_Sector_Ct -O--CK 100 100 010 - 0
9 Power_On_Hours -O--CK 100 100 000 - 255
12 Power_Cycle_Count -O--CK 100 100 000 - 18
171 Unknown_Attribute -O--CK 100 100 000 - 0
172 Unknown_Attribute -O--CK 100 100 000 - 0
173 Unknown_Attribute -O--CK 099 099 000 - 9
174 Unknown_Attribute -O--CK 100 100 000 - 18
180 Unused_Rsvd_Blk_Cnt_Tot PO--CK 100 100 000 - 5
183 Runtime_Bad_Block -O--CK 100 100 000 - 0
184 End-to-End_Error -O--CK 100 100 000 - 0
187 Reported_Uncorrect -O--CK 100 100 000 - 0
194 Temperature_Celsius -O---K 075 068 000 - 25 (Min/Max 13/32)
196 Reallocated_Event_Count -O--CK 100 100 000 - 0
197 Current_Pending_Sector -O--CK 100 100 000 - 0
198 Offline_Uncorrectable ----CK 100 100 000 - 0
199 UDMA_CRC_Error_Count -O--CK 100 100 000 - 0
202 Unknown_SSD_Attribute ----CK 099 099 001 - 1
206 Unknown_SSD_Attribute -OSR-- 100 100 000 - 0
210 Unknown_Attribute -O--CK 100 100 000 - 0
246 Unknown_Attribute -O--CK 100 100 000 - 2526808869
247 Unknown_Attribute -O--CK 100 100 000 - 78962777
248 Unknown_Attribute -O--CK 100 100 000 - 117822464
249 Unknown_Attribute -O--CK 100 100 000 - 0
251 Unknown_Attribute -O--CK 100 100 000 - 3085416729
252 Unknown_Attribute -O--CK 100 100 000 - 0
253 Unknown_Attribute -O--CK 100 100 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x06 SL R/O 1 SMART self-test log
0x07 GPL R/O 1 Extended self-test log
0x10 GPL R/O 1 NCQ Command Error log
0x11 GPL R/O 1 SATA Phy Event Counters log
0x24 GPL R/O 88 Current Device Internal Status Data log
0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
SMART Extended Comprehensive Error Log (GP Log 0x03) not supported
SMART Error Log not supported
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 51 -
# 2 Short offline Completed without error 00% 42 -
Selective Self-tests/Logging not supported
SCT Commands not supported
Device Statistics (GP/SMART Log 0x04) not supported
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 4 0 Command failed due to ICRC error
0x0002 4 0 R_ERR response for data FIS
0x0005 4 1 R_ERR response for non-data FIS
0x000a 4 2 Device-to-host register FISes sent due to a COMRESETI have also try,
1) change SATA cable for the hard disk
2) change port on the motherboard
3) check if there is some visual issue on the motherboard or on disk that is preventing the cable for sitting correctly or there is some (visual) fault
4) upgrade the IPMI and BIOS to the latest version
5) checked bios settings if there is something related
Could this be something related to compatibility of my hardware with linux? Or could this be the hard disk being too slow that is causing this issues? I am asking this because I used slower disk in proxmox before and never had issues but the combination of slow ssd could be the culprit?
The same VMs (with the same hardware options) run just fine on my old machine so I am running out of ideas what to try next. Doe someone have any any other idea about what I could try or what could the issue?
Thanks
Phanos