Hello,
We are a recent proxmox adopter in an enterprise environment. We currently have rolled out proxmox to a small number of hosts, but hope to expand. Unfortunately a few issues have been plaguing us we would like to resolve.
Currently, we have 27 servers running proxmox 4.4, installed and configured via the online documentation, running approximately 120 VMs.
The servers are:
22x Dell R420, 64GB RAM
5x Supermicro 1028R, 128GB RAM
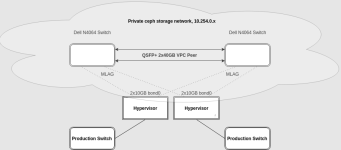
They are backed by a dedicated storage network, each having dual 10Gbp/s links, serving a ceph cluster of 46 SSDs. They are uplinked to our production network on a 3rd 10Gbp/s link.
The specific problem we are having is that the hypervisors seem to be spontaneously rebooting under load. We have ruled out:
1) Power. All machines have redundant and properly specced power.
2) Memory/CPU. The problem drifts from machine to machine and can be replicated by producing artificial load or moving a greedy VM to it.
Suspecting this might be watchdog related, we disabled the hardware watchdog on the Supermicro chassis, but the random reboots continued. We eventually narrowed it down to a particular VM that is very heavy on on CPU and RAM demands. If that VM is on the host, it eventually spontaneously reboots.
Following that lead, I experimented on a random hypervisor, and merely put a lot of I/O stress onto it's local disk with bonnie++. After just a few minutes, that machine became the 6th in the cluster to randomly restart. I can't find any data in the logs suggesting this was expected, no errors or warnings, nothing out of the ordinary. The machine is there one minute, and gone the next, still serving its VMs up until the point it mysteriously reboots.
Currently, I suspect proxmox itself is rebooting the machines, and am requesting some assistance in verifying that and seeing what I can do about it.
We are a recent proxmox adopter in an enterprise environment. We currently have rolled out proxmox to a small number of hosts, but hope to expand. Unfortunately a few issues have been plaguing us we would like to resolve.
Currently, we have 27 servers running proxmox 4.4, installed and configured via the online documentation, running approximately 120 VMs.
The servers are:
22x Dell R420, 64GB RAM
5x Supermicro 1028R, 128GB RAM
They are backed by a dedicated storage network, each having dual 10Gbp/s links, serving a ceph cluster of 46 SSDs. They are uplinked to our production network on a 3rd 10Gbp/s link.
The specific problem we are having is that the hypervisors seem to be spontaneously rebooting under load. We have ruled out:
1) Power. All machines have redundant and properly specced power.
2) Memory/CPU. The problem drifts from machine to machine and can be replicated by producing artificial load or moving a greedy VM to it.
Suspecting this might be watchdog related, we disabled the hardware watchdog on the Supermicro chassis, but the random reboots continued. We eventually narrowed it down to a particular VM that is very heavy on on CPU and RAM demands. If that VM is on the host, it eventually spontaneously reboots.
Following that lead, I experimented on a random hypervisor, and merely put a lot of I/O stress onto it's local disk with bonnie++. After just a few minutes, that machine became the 6th in the cluster to randomly restart. I can't find any data in the logs suggesting this was expected, no errors or warnings, nothing out of the ordinary. The machine is there one minute, and gone the next, still serving its VMs up until the point it mysteriously reboots.
Currently, I suspect proxmox itself is rebooting the machines, and am requesting some assistance in verifying that and seeing what I can do about it.
") ).
).