arch: amd64
cores: 2
features: nesting=1
hostname: frigate
memory: 2048
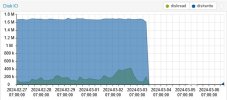
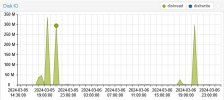
mp1: /mnt/pve/wd6000-1/ct-mounts/nvr-space,mp=/mnt/nvr-space,mountoptions=lazytime
net0: name=eth0,bridge=vmbr0,firewall=1,gw=10.10.62.254,hwaddr=96:A6:30:F6:E7:43,ip=10.10.62.8/24,type=veth
net1: name=eth1,bridge=vmbr0,firewall=1,hwaddr=3A:45:37:F6:77:2C,ip=192.168.40.8/24,tag=40,type=veth
onboot: 1
ostype: debian
rootfs: local-lvm:vm-103-disk-0,mountoptions=noatime;lazytime,size=8G
swap: 512
tags: debian12
unprivileged: 1
lxc.cgroup2.devices.allow: c 226:0 rwm
lxc.cgroup2.devices.allow: c 226:128 rwm
lxc.cgroup2.devices.allow: c 189:* rwm # usb (coral)
lxc.mount.entry: /dev/dri/card0 dev/dri/card0 none bind,optional,create=file
lxc.mount.entry: /dev/dri/renderD128 dev/dri/renderD128 none bind,optional,create=file
lxc.mount.entry: /dev/bus/usb/002 dev/bus/usb/002 none bind,optional,create=dir
lxc.mount.entry: /dev/bus/usb/003 dev/bus/usb/003 none bind,optional,create=dir
lxc.mount.entry: /dev/bus/usb/004 dev/bus/usb/004 none bind,optional,create=dir
lxc.idmap: g 0 100000 44
lxc.idmap: u 0 100000 44
lxc.idmap: g 44 44 1
lxc.idmap: u 44 44 1
lxc.idmap: g 45 100045 60
lxc.idmap: u 45 100045 60
lxc.idmap: g 105 103 1
lxc.idmap: u 105 103 1
lxc.idmap: g 106 100106 65430
lxc.idmap: u 106 100106 65430