Latest activity
-
Ei configured Openid on azure im PMG but when i try to login i get: OpenID Connect login failed, please try again authentication failure no such user ('user@domain.com@AzureSSO') (401)
-
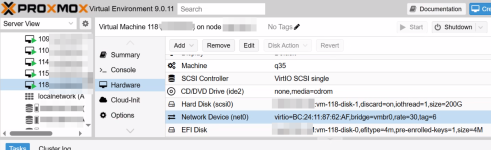
Mmikewich posted the thread <span>nodename</span> showing up in front of everything in Proxmox VE: Installation and configuration.we ran into a weird issue. when we came in this morning and checked our main cluster node, we get <span> in front of everything in the GUI. reset browser cache and still there. tried apt reset via shell and still no go. anyone ever run into this...
-
-
FFrancisS replied to the thread Ceph 19.2.1 2 OSD(s) experiencing slow operations in BlueStore.Hello, Sorry for the late update, I replaced all the Crucial disks and now no slow messages... and no more performance "problems". Best regards. Francis
-
LLarsen replied to the thread Rules logging.Can't help you there, but as I was looking for something similar, I have created https://bugzilla.proxmox.com/show_bug.cgi?id=7395 as a feature request.
-
LLarsen replied to the thread Get specific rule by log code.I have created https://bugzilla.proxmox.com/show_bug.cgi?id=7395 as a feature request. A workaround for you could be to log the subject, but this would apply to every mail received...
-
IIvane replied to the thread Proxmox “command is not allowed” freeze message.Thanks for the reply. I have responded.
-
 fiona replied to the thread [SOLVED] Permission(s) required for snapshot rollback only.Hi, does the user itself have the permission to do the rollback? A token always has a subset of the permissions of the user it is associated to.
fiona replied to the thread [SOLVED] Permission(s) required for snapshot rollback only.Hi, does the user itself have the permission to do the rollback? A token always has a subset of the permissions of the user it is associated to. -
Ssgw replied to the thread OCFS2(unsupported): Frage zu Belegung.In meinem Fall ist es eben so: * SAN ist vorhanden, jeweils 2 FC-Controller pro Node, etc -> das will der Kunde nicht wegwerfen, wenn es soweit gut funktioniert * 5 Platten drin, RAID5 (nicht mein Wunsch, aber ist so), eine LUN, da drauf das...
-
Lluizfgoncalves posted the thread Intel igpu Passthrough gives no HDMI Signal in Proxmox VE: Installation and configuration.Hi everyone. I'm new at Proxmox and virtualization, and I'm currently stuck in making the GPU Passthrough work for my Pop OS 22.04. It seems to be partially working, as I can see the ProxMox boot screen on TV, but after that I get a "No signal"...
-
 UdoB replied to the thread OCFS2(unsupported): Frage zu Belegung.So hätte ich das (als Ceph-Laie) nicht formuliert. Das, was Ceph unbedingt braucht, ist ein schnelles Netz - oder auch zwei. Und zwar idealerweise ein separates. Für mich hört sich das echt nach Storage-Area-Network an ;-)
UdoB replied to the thread OCFS2(unsupported): Frage zu Belegung.So hätte ich das (als Ceph-Laie) nicht formuliert. Das, was Ceph unbedingt braucht, ist ein schnelles Netz - oder auch zwei. Und zwar idealerweise ein separates. Für mich hört sich das echt nach Storage-Area-Network an ;-) -
Naja Ceph ist ja ein verteiltes System, was darauf ausgelegt ist aus zig Servern und in ihnen verbauten Platten/SSDs einen gemeinsamen Storage zu bauen. Das skaliert extrem ( je mehr Knoten und je mehr Platten desto bessere Performance), ist...
-
SProxmox: proxmox-ve: 9.1.0 (running kernel: 6.17.4-2-pve) pve-manager: 9.1.4 (running version: 9.1.4/5ac30304265fbd8e) proxmox-kernel-helper: 9.0.4 pve-kernel-5.13: 7.1-9 proxmox-kernel-6.17.4-2-pve-signed: 6.17.4-2 proxmox-kernel-6.17: 6.17.4-2...
-
LLarsen replied to the thread Get specific rule by log code.Hi koby, I am looking for exactly the same. Did you find a solution?
-
MMike_Scholes replied to the thread Verification "error" 500 Internal Server Error on S3 datastore.Great thanks
-
Ggunterwa replied to the thread [SOLVED] PVE 9.0.3 suffered from DNS Drop after a upgrade....Online waiting ...
-
TTErxleben replied to the thread OpenWRT-Gateway Failover per VM.Da checkwan.sh dazu neigte Fehlalarme zu produzieren, verlasse ich mich nun nur auf die "Meinung" der Fritzboxgateways. forcefailover.sh liefert entweder 0 oder 1, je nachdem ob man einen Ausfall simulieren möchte ohne den service neu starten zu...
-
Ttchaikov replied to the thread VMs freeze after node failure/reboot in 5-node Ceph cluster.Your reply confirms this is a two-phase problem: Phase 1: Why does re-peering take long enough to cause 120s+ blocked I/O? On NVMe with 10G networking, peering 75 PGs should complete in seconds, not minutes. Something is making it abnormally...
-
fiona replied to the thread [SOLVED] PVE 9.1.5: Linux VM Freeze Randomly.Glad to hear! See also: https://bugzilla.kernel.org/show_bug.cgi?id=199727#c8
-
FFrankiman replied to the thread [SOLVED] ZFS scrubbing does not work anymore on Kernel 6.14.11 (and cannot upgrade to 6.17.X because of NVidia).This message appears in PBS; I solved it with a reboot, and the kernel automatically changed.
-
Ppulipulichen replied to the thread [SOLVED] Why does my VM backup to PBS hang and show "dirty-bitmap status: created new"?.I did a quick test to reproduce this backup "hang" issue, and the results are pretty clear. It seems Backup Fleecing is exactly what we need for these kinds of bottlenecks. My test setup:I tried to simulate a "worst-case scenario" with a...
-