Hallo.
Diese Frage läuft sicher nicht zum ersten Mal ... aber ich möchte sie trotzdem nochmal stellen, da ich die Größenangaben bei Verwendung von ZFS-Pools weiterhin verwirrend finde.
Die Situtation ist: IBM-M4-Server mit 4 Platten zu einem Z2-Pool (mit Cache). Unter Disks -> ZFS sehe ich dies:

Also verfügbar (ohne Deduplizierung): 3.41 TB.
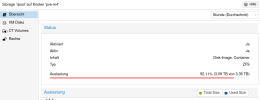
Wenn ich aber unter Storage -> Übersicht auf den ZFS-Pool schaue, sehe ich:

Dort steht nun also 3.35 TB.
Wenn ich auf die VM selbst gehe, sehe ich: Disk-Size 2.55 TB

Nun würde ich erwarten, dass das ~ 2.55/3.35 = 76% entspricht. Aber die Auslastung zeigt mir ~92% an.
Zudem warnt mich checkMK mit dieser Anzeige, wo wieder etwas anderes steht:

Ich finde das äußerst verwirrend. Welche Angabe denn nun "richtig"??
Hintergrund der Frage: Ich hatte die Partition für diese VM mit Proxmox-Bordmitteln vergrößert, da der Plattenplatz knapp geworden ist. Da ZFS bei mehr als 80% Belegung scheinbar langsam wird, wollte ich natürlich tunlichst unterhalb der 80% Grenze bleiben. Doch jetzt ist genau das Gegenteil geschehen, weil ich die Größe des Dateisystems offenbar falsch gedeutet habe.
Danke für Klärung!
Diese Frage läuft sicher nicht zum ersten Mal ... aber ich möchte sie trotzdem nochmal stellen, da ich die Größenangaben bei Verwendung von ZFS-Pools weiterhin verwirrend finde.
Die Situtation ist: IBM-M4-Server mit 4 Platten zu einem Z2-Pool (mit Cache). Unter Disks -> ZFS sehe ich dies:
Also verfügbar (ohne Deduplizierung): 3.41 TB.
Wenn ich aber unter Storage -> Übersicht auf den ZFS-Pool schaue, sehe ich:
Dort steht nun also 3.35 TB.
Wenn ich auf die VM selbst gehe, sehe ich: Disk-Size 2.55 TB
Nun würde ich erwarten, dass das ~ 2.55/3.35 = 76% entspricht. Aber die Auslastung zeigt mir ~92% an.
Zudem warnt mich checkMK mit dieser Anzeige, wo wieder etwas anderes steht:
Ich finde das äußerst verwirrend. Welche Angabe denn nun "richtig"??
Hintergrund der Frage: Ich hatte die Partition für diese VM mit Proxmox-Bordmitteln vergrößert, da der Plattenplatz knapp geworden ist. Da ZFS bei mehr als 80% Belegung scheinbar langsam wird, wollte ich natürlich tunlichst unterhalb der 80% Grenze bleiben. Doch jetzt ist genau das Gegenteil geschehen, weil ich die Größe des Dateisystems offenbar falsch gedeutet habe.
Danke für Klärung!
Attachments
Last edited:

")
") .
.
