I have (had?) a ZFS pool setup through proxmox that stopped working. All the disks in shows up in Node > Disks, with "SMART: PASSED" but "Mounted: No"

I would like to recover this pool if possible, but if not I would love to know what happened. This was using RAIDZ1, and my understanding was that a disk failure should be recoverable. How did the entire pool fail?
In case this isn't an issue with the pool, but with PVE, this is the error that all the containers report when starting.
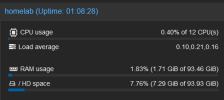
The summary shows lots of free space

but the Disks > LVM shows 97% usage. I am not sure what this means.

---
EDIT 1
I found this post and set thin_check_options = [ "-q", "--skip-mappings" ] and rebooted. The pve/data error is gone, and some containers started, but the ZFS pool is still not showing up and still returning an error trying to import it.
Bash:
root@homelab:~# zpool status
no pools available
root@homelab:~# zpool history
no pools available
root@homelab:~# zpool import tank
cannot import 'tank': I/O error
Destroy and re-create the pool from
a backup source.
root@homelab:~# ls /dev/disk/by-id
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105328K nvme-TEAM_TM8FP6512G_TPBF2310170070320761
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105328K-part1 nvme-TEAM_TM8FP6512G_TPBF2310170070320761_1
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105328K-part9 nvme-TEAM_TM8FP6512G_TPBF2310170070320761_1-part1
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105332H nvme-TEAM_TM8FP6512G_TPBF2310170070320761_1-part2
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105332H-part1 nvme-TEAM_TM8FP6512G_TPBF2310170070320761_1-part3
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105332H-part9 nvme-TEAM_TM8FP6512G_TPBF2310170070320761-part1
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105404L nvme-TEAM_TM8FP6512G_TPBF2310170070320761-part2
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105404L-part1 nvme-TEAM_TM8FP6512G_TPBF2310170070320761-part3
ata-Samsung_SSD_870_EVO_2TB_S6PNNS0W105404L-part9 wwn-0x5002538f33112e23
dm-name-pve-root wwn-0x5002538f33112e23-part1
dm-name-pve-swap wwn-0x5002538f33112e23-part9
dm-uuid-LVM-R6n6naJnN0MGscNHJMQliRntP3DadNPO3W8zZskqP5j8BDVtr2CLOlYH4JDVeuBz wwn-0x5002538f33112e27
dm-uuid-LVM-R6n6naJnN0MGscNHJMQliRntP3DadNPOJ0bU7RRhVlJBUNsR4GvNBk09kxghMlvV wwn-0x5002538f33112e27-part1
lvm-pv-uuid-1JMPCW-SdpW-Gmfq-srge-NVyN-rdvN-D6ndtC wwn-0x5002538f33112e27-part9
nvme-eui.6479a784e0000385 wwn-0x5002538f33112e6f
nvme-eui.6479a784e0000385-part1 wwn-0x5002538f33112e6f-part1
nvme-eui.6479a784e0000385-part2 wwn-0x5002538f33112e6f-part9
nvme-eui.6479a784e0000385-part3I would like to recover this pool if possible, but if not I would love to know what happened. This was using RAIDZ1, and my understanding was that a disk failure should be recoverable. How did the entire pool fail?
In case this isn't an issue with the pool, but with PVE, this is the error that all the containers report when starting.
TASK ERROR: activating LV 'pve/data' failed: Check of pool pve/data failed (status:1). Manual repair required!
The summary shows lots of free space
but the Disks > LVM shows 97% usage. I am not sure what this means.
---
EDIT 1
I found this post and set thin_check_options = [ "-q", "--skip-mappings" ] and rebooted. The pve/data error is gone, and some containers started, but the ZFS pool is still not showing up and still returning an error trying to import it.
Attachments
Last edited: