ZFS pool import fails on boot, but appears to be imported after
- Thread starter Cephei
- Start date
-
- Tags
- zfs at boot
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
I have exactly the same problem.
New ZFS Pool i removed it and created it again. The error remains.
I also added the boot delay.
The error remains.
I think it is came with the update to pve7.1-5 Under pve7.0-19 I would not have noticed.
after boot evryfin works normally and the pool also online and mountet
New ZFS Pool i removed it and created it again. The error remains.
I also added the boot delay.
The error remains.
I think it is came with the update to pve7.1-5 Under pve7.0-19 I would not have noticed.
after boot evryfin works normally and the pool also online and mountet
For testing I installed Proxmox in a VM and updated it to the last stand.
Created a Z1 Pool and restarted
Same mistake
From the web gui and the shell, the pool works normally and does not show any errors.
Possibly an output error?
Should or could it be ignored?
Created a Z1 Pool and restarted
Same mistake
From the web gui and the shell, the pool works normally and does not show any errors.
Possibly an output error?
Should or could it be ignored?
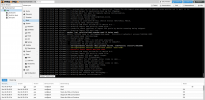
I have the same problème with a clean install on proxmox 7.1.10
The pool on Gui are mounted and work. But all the same error on boot, systemctl and more.
The pool on Gui are mounted and work. But all the same error on boot, systemctl and more.
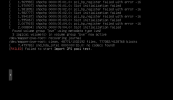
root@pve:~# zpool status
pool: DATA1
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
DATA1 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
scsi-35000c500d4a7f2f8 ONLINE 0 0 0
scsi-35000c500d5882140 ONLINE 0 0 0
scsi-35000c500c39b5dc2 ONLINE 0 0 0
errors: No known data errors
pool: DATA2
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
DATA2 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
scsi-350000c0f02d70528 ONLINE 0 0 0
scsi-350000c0f0280da24 ONLINE 0 0 0
scsi-350000c0f02d6fec0 ONLINE 0 0 0
errors: No known data errors
Code:
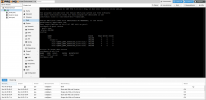
root@pve:~# zfs-import@DATA1.service
-bash: zfs-import@DATA1.service: command not found
root@pve:~# systemctl status zfs-import@DATA1
Failed to get journal cutoff time: Bad message
● zfs-import@DATA1.service - Import ZFS pool DATA1
Loaded: loaded (/lib/systemd/system/zfs-import@.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Sat 2022-02-26 06:28:55 CET; 26min ago
Docs: man:zpool(8)
Process: 904 ExecStart=/sbin/zpool import -N -d /dev/disk/by-id -o cachefile=none DATA1 (code=exited, status=1/FAILURE)
Main PID: 904 (code=exited, status=1/FAILURE)
CPU: 25ms
Feb 26 06:29:22 pve zpool[904]: cannot import 'DATA1': no such pool available
Feb 26 06:28:54 pve systemd[1]: Starting Import ZFS pool DATA1...
Feb 26 06:28:55 pve systemd[1]: zfs-import@DATA1.service: Main process exited, code=exited, status=1/FAILURE
Feb 26 06:28:55 pve systemd[1]: zfs-import@DATA1.service: Failed with result 'exit-code'.
Feb 26 06:28:55 pve systemd[1]: Failed to start Import ZFS pool DATA1.
root@pve:~# systemctl status zfs-import-cache.service
● zfs-import-cache.service - Import ZFS pools by cache file
Loaded: loaded (/lib/systemd/system/zfs-import-cache.service; enabled; vendor preset: enabled)
Active: active (exited) since Sat 2022-02-26 06:28:57 CET; 26min ago
Docs: man:zpool(8)
Process: 903 ExecStart=/sbin/zpool import -c /etc/zfs/zpool.cache -aN $ZPOOL_IMPORT_OPTS (code=exited, status=0/SUCCESS)
Main PID: 903 (code=exited, status=0/SUCCESS)
CPU: 33ms
Feb 26 06:29:22 pve zpool[903]: cannot import 'DATA2': pool already exists
Feb 26 06:29:22 pve zpool[903]: no pools available to import
Feb 26 06:29:22 pve zpool[903]: cachefile import failed, retrying
Feb 26 06:28:54 pve systemd[1]: Starting Import ZFS pools by cache file...
Feb 26 06:28:57 pve systemd[1]: Finished Import ZFS pools by cache file.
Last edited:
could you provide the complete journal of the boot after a reboot?I have the same problème with a clean install on proxmox 7.1.10
The pool on Gui are mounted and work. But all the same error on boot, systemctl and more.
(reboot and provide the output of `journalctl -b` )
I assume that your pools somehow ended up in the cache-file and are thus already imported when the service which specifically tries to import it runs
You can either export them and reimport them without cache-file (pvestatd should take care of that) or simply remove
'etc/systemd/system/zfs-import.target.wants/zfs-import@<POOLNAME>.service'
I hope this helps!

Hello, thank for reply.
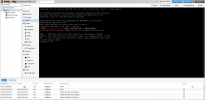
This is the journal after restart machine.
pvestatd restart = nothing
Some precisions. The server is a PowerEdge R320 with a PERC H310 mini card that I flashed.
Then I passed the HDDs to my live VM like this: qm set 100 -scsi1 /dev/disk/by-id/ata-ST1000LM048-2E7172_ZKP1LG61
I see in the log this line, I don't have a level with linux, I manage with explanations, but why there are so many lines like this:
Why my Mikrotik router close connection ?
sd 8:0:0:0: [sdg] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverb>
Feb 28 17:03:21 pve sshd[2608]: error: kex_exchange_identification: Connection closed by remote host
Feb 28 17:03:21 pve sshd[2608]: Connection closed by 192.168.2.1 port 45743
Feb 28 17:03:31 pve sshd[2636]: error: kex_exchange_identification: Connection closed by remote host
Feb 28 17:03:31 pve sshd[2636]: Connection closed by 192.168.2.1 port 45803
Feb 28 17:03:51 pve sshd[2696]: error: kex_exchange_identification: Connection closed by remote host
Feb 28 17:03:51 pve sshd[2696]: Connection closed by 192.168.2.1 port 45879
Feb 28 17:04:01 pve sshd[2726]: error: kex_exchange_identification: Connection closed by remote host
This is the journal after restart machine.
pvestatd restart = nothing
Some precisions. The server is a PowerEdge R320 with a PERC H310 mini card that I flashed.
Then I passed the HDDs to my live VM like this: qm set 100 -scsi1 /dev/disk/by-id/ata-ST1000LM048-2E7172_ZKP1LG61
I see in the log this line, I don't have a level with linux, I manage with explanations, but why there are so many lines like this:
Why my Mikrotik router close connection ?
sd 8:0:0:0: [sdg] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverb>
Feb 28 17:03:21 pve sshd[2608]: error: kex_exchange_identification: Connection closed by remote host
Feb 28 17:03:21 pve sshd[2608]: Connection closed by 192.168.2.1 port 45743
Feb 28 17:03:31 pve sshd[2636]: error: kex_exchange_identification: Connection closed by remote host
Feb 28 17:03:31 pve sshd[2636]: Connection closed by 192.168.2.1 port 45803
Feb 28 17:03:51 pve sshd[2696]: error: kex_exchange_identification: Connection closed by remote host
Feb 28 17:03:51 pve sshd[2696]: Connection closed by 192.168.2.1 port 45879
Feb 28 17:04:01 pve sshd[2726]: error: kex_exchange_identification: Connection closed by remote host
Attachments
Last edited:
+1 i have the same "issue" i am watching this
(i had a similar issue on pbs running as vm, but there i know where it was coming from, i used an p'n'p usb device with zfs and dind't exported before)
on boot i got also this error

when booting is completed and the webgui is up, the zfs pools are working without any errors
here are some zfs related parts from the log
(i had a similar issue on pbs running as vm, but there i know where it was coming from, i used an p'n'p usb device with zfs and dind't exported before)
on boot i got also this error
when booting is completed and the webgui is up, the zfs pools are working without any errors
here are some zfs related parts from the log
Code:
...........
Mar 01 16:36:48 vmhost01 systemd: Created slice system-zfs\x2dimport.slice.
...........
Mar 01 16:36:48 vmhost01 udevadm[506]: systemd-udev-settle.service is deprecated. Please fix zfs-import-cache.service, zfs-import-scan.service not to pull it in.
...........
Mar 01 16:36:48 vmhost01 systemd[1]: Finished File System Check on /dev/disk/by-uuid/72F0-4F0D.
Mar 01 16:36:48 vmhost01 kernel: ZFS: Loaded module v2.1.2-pve1, ZFS pool version 5000, ZFS filesystem version 5
Mar 01 16:36:48 vmhost01 systemd[1]: Mounting /boot/efi...
Mar 01 16:36:48 vmhost01 systemd-modules-load[463]: Inserted module 'zfs'
...........
Mar 01 16:36:50 vmhost01 systemd[1]: Finished Helper to synchronize boot up for ifupdown.
Mar 01 16:36:50 vmhost01 systemd[1]: Finished Wait for udev To Complete Device Initialization.
Mar 01 16:36:50 vmhost01 systemd[1]: Starting Import ZFS pools by cache file...
Mar 01 16:36:50 vmhost01 systemd[1]: Condition check resulted in Import ZFS pools by device scanning being skipped.
Mar 01 16:36:50 vmhost01 systemd[1]: Starting Import ZFS pool local\x2dzfs\x2dstore...
Mar 01 16:36:50 vmhost01 zpool[765]: cannot import 'local-zfs-store': no such pool available
Mar 01 16:36:50 vmhost01 systemd[1]: zfs-import@local\x2dzfs\x2dstore.service: Main process exited, code=exited, status=1/FAILURE
Mar 01 16:36:50 vmhost01 systemd[1]: zfs-import@local\x2dzfs\x2dstore.service: Failed with result 'exit-code'.
Mar 01 16:36:50 vmhost01 systemd[1]: Failed to start Import ZFS pool local\x2dzfs\x2dstore.
Mar 01 16:36:50 vmhost01 systemd[1]: Finished Import ZFS pools by cache file.
Mar 01 16:36:50 vmhost01 systemd[1]: Reached target ZFS pool import target.
Mar 01 16:36:50 vmhost01 systemd[1]: Starting Mount ZFS filesystems...
Mar 01 16:36:50 vmhost01 systemd[1]: Starting Wait for ZFS Volume (zvol) links in /dev...
Mar 01 16:36:50 vmhost01 zvol_wait[1069]: No zvols found, nothing to do.
Mar 01 16:36:50 vmhost01 systemd[1]: Finished Wait for ZFS Volume (zvol) links in /dev.
Mar 01 16:36:50 vmhost01 systemd[1]: Reached target ZFS volumes are ready.
Mar 01 16:36:50 vmhost01 systemd[1]: Finished Mount ZFS filesystems.
Mar 01 16:36:50 vmhost01 systemd[1]: Reached target Local File Systems.
...........
Mar 01 16:36:50 vmhost01 systemd[1]: Starting User Login Management...
Mar 01 16:36:50 vmhost01 systemd[1]: Started Proxmox VE watchdog multiplexer.
Mar 01 16:36:50 vmhost01 systemd[1]: Starting ZFS file system shares...
Mar 01 16:36:50 vmhost01 systemd[1]: Started ZFS Event Daemon (zed).
Mar 01 16:36:50 vmhost01 systemd[1]: Started Proxmox VE LXC Syscall Daemon.
Mar 01 16:36:50 vmhost01 rsyslogd[1119]: imuxsock: Acquired UNIX socket '/run/systemd/journal/syslog' (fd 3) from systemd. [v8.2102.0]
Mar 01 16:36:50 vmhost01 systemd[1]: e2scrub_reap.service: Succeeded.
Mar 01 16:36:50 vmhost01 watchdog-mux[1145]: Watchdog driver 'Software Watchdog', version 0
Mar 01 16:36:50 vmhost01 rsyslogd[1119]: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="1119" x-info="https://www.rsyslog.com"] start
Mar 01 16:36:50 vmhost01 systemd[1]: Finished Remove Stale Online ext4 Metadata Check Snapshots.
Mar 01 16:36:50 vmhost01 systemd[1]: Started System Logging Service.
Mar 01 16:36:50 vmhost01 systemd[1]: Started Kernel Samepage Merging (KSM) Tuning Daemon.
Mar 01 16:36:50 vmhost01 systemd[1]: Started PVE Qemu Event Daemon.
Mar 01 16:36:50 vmhost01 zed[1149]: ZFS Event Daemon 2.1.2-pve1 (PID 1149)
Mar 01 16:36:50 vmhost01 zed[1149]: Processing events since eid=0
Mar 01 16:36:50 vmhost01 kernel: softdog: initialized. soft_noboot=0 soft_margin=60 sec soft_panic=0 (nowayout=0)
Mar 01 16:36:50 vmhost01 kernel: softdog: soft_reboot_cmd=<not set> soft_active_on_boot=0
Mar 01 16:36:50 vmhost01 systemd[1]: Finished ZFS file system shares.
Mar 01 16:36:50 vmhost01 systemd[1]: Reached target ZFS startup target.
Mar 01 16:36:50 vmhost01 dbus-daemon[1112]: [system] AppArmor D-Bus mediation is enabled
Mar 01 16:36:50 vmhost01 zed[1174]: eid=5 class=config_sync pool='local-zfs-store'
Mar 01 16:36:50 vmhost01 zed[1169]: eid=3 class=pool_import pool='local-zfs-store'
Mar 01 16:36:50 vmhost01 zed[1167]: eid=2 class=config_sync pool='local-zfs-store'
Mar 01 16:36:50 vmhost01 smartd[1121]: smartd 7.2 2020-12-30 r5155 [x86_64-linux-5.13.19-4-pve] (local build)
...........
Code:
proxmox-ve: 7.1-1 (running kernel: 5.13.19-4-pve)
pve-manager: 7.1-10 (running version: 7.1-10/6ddebafe)
pve-kernel-helper: 7.1-12
pve-kernel-5.13: 7.1-7
pve-kernel-5.13.19-4-pve: 5.13.19-9
pve-kernel-5.13.19-2-pve: 5.13.19-4
ceph-fuse: 15.2.15-pve1
corosync: 3.1.5-pve2
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.22-pve2
libproxmox-acme-perl: 1.4.1
libproxmox-backup-qemu0: 1.2.0-1
libpve-access-control: 7.1-6
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.1-3
libpve-guest-common-perl: 4.1-1
libpve-http-server-perl: 4.1-1
libpve-storage-perl: 7.1-1
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 4.0.11-1
lxcfs: 4.0.11-pve1
novnc-pve: 1.3.0-2
proxmox-backup-client: 2.1.5-1
proxmox-backup-file-restore: 2.1.5-1
proxmox-mini-journalreader: 1.3-1
proxmox-widget-toolkit: 3.4-6
pve-cluster: 7.1-3
pve-container: 4.1-4
pve-docs: 7.1-2
pve-edk2-firmware: 3.20210831-2
pve-firewall: 4.2-5
pve-firmware: 3.3-5
pve-ha-manager: 3.3-3
pve-i18n: 2.6-2
pve-qemu-kvm: 6.1.1-2
pve-xtermjs: 4.16.0-1
qemu-server: 7.1-4
smartmontools: 7.2-1
spiceterm: 3.2-2
swtpm: 0.7.0~rc1+2
vncterm: 1.7-1
zfsutils-linux: 2.1.2-pve1
Last edited:
I just want to say .. me too. One of my ZFS pools has this issue. This pool previously existed on two disks. I then destroyed it and recreated it with four disks under the same name. I was pretty scared when I saw the error. Then after boot the zfs pool seems to be working fine. I hesitate to try any of the "solutions" suggested here. Is there any software fix in the works that will take care of this error message?
Got exactly the same. Does anyone investigate this or can open an issue on github? It seems to be a real bug.
Code:
pve-manager/7.1-11/8d529482 (running kernel: 5.15.27-1-pve)
Code:
pool: storage
state: ONLINE
scan: scrub repaired 0B in 13:49:58 with 0 errors on Sun Mar 13 14:14:01 2022
config:
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-WDC_WUH721414ALE6L4_XHG5G2AH ONLINE 0 0 0
ata-WDC_WUH721414ALE6L4_9MGN47JU ONLINE 0 0 0
ata-WDC_WUH721414ALE6L4_9MGN42RU ONLINE 0 0 0
ata-WDC_WUH721414ALE6L4_9MGLX92K ONLINE 0 0 0
ata-WDC_WUH721414ALE6L4_XHG5EXHH ONLINE 0 0 0
ata-WDC_WUH721414ALE6L4_XHG5EKZH ONLINE 0 0 0
Last edited:
I currently do not see the bug here - to my understanding this is a cosmetic issue (although I get that the red 'FAILED' during booting looks scary):Got exactly the same. Does anyone investigate this or can open an issue on github? It seems to be a real bug.
I assume that your pools somehow ended up in the cache-file and are thus already imported when the service which specifically tries to import it runs
You can either export them and reimport them without cache-file (pvestatd should take care of that) or simply remove
'etc/systemd/system/zfs-import.target.wants/zfs-import@<POOLNAME>.service'
I hope this helps!
Or am I missing something where this causes actual problems?
I think it is cosmetic, but a little scary when you first see it and have not visited this thread.
I have created then destroyed my pool let's call it "tankie". After that I created a new ZFS pool called also tankie, which I populated with datasets, automated snapshots, the usual stuff.simply remove
'etc/systemd/system/zfs-import.target.wants/zfs-import@<POOLNAME>.service'
I hope this helps!
Tankie gets mounted at every reboot without issues but I'm getting that FAILURE error on boot regarding the system being unable to import tankie.
May I remove /etc/systemd/system/zfs-import.target.wants/zfs-import@tankie.service and have my pool being mounted and accessed as normal?
Thank you!
Last edited:
Or am I missing something where this causes actual problems?
Even if this is purely cosmetic (and doesn't belie a deeper problem), it would seem of value to try to prevent systemd units from reporting false-positive errors since at the very least such errors would seem to introduce unnecessary noise that might otherwise obscure the cause of true issues.
I have the same error on my end, FWIW, so perhaps it's fairly widespread?
If I follow, presumably this false positive error would be resolved if the 'zpool import' nonzero exit code is resolved, and presumably that could be done by checking that the pool isn't already imported before doing 'zpool import' again (/lib/systemd/system/zfs-import@.service)?
Did you ever get an answer to this? I didn't read the forums and I messed up my VM, destroyed it and made a new VM with the same exact name. Now I'm loading proxmox no problem and all VM's start but boot hangs trying to get the old pool to load even though the new pool is active.I have created then destroyed my pool let's call it "tankie". After that I created a new ZFS pool called also tankie, which I populated with datasets, automated snapshots, the usual stuff.
Tankie gets mounted at every reboot without issues but I'm getting that FAILURE error on boot regarding the system being unable to import tankie.
May I remove /etc/systemd/system/zfs-import.target.wants/zfs-import@tankie.service and have my pool being mounted and accessed as normal?
Thank you!
Did you run this command and if so did it mess everything up?
I installed brand new proxmox 7.3 updated kernel to 5.19, created a zfs pool called VM01 and also get the error during boot.
SYSLOG:
Dec 12 14:58:49 MOPROXMOX01 kernel: usbcore: registered new interface driver snd-usb-audio
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Finished Helper to synchronize boot up for ifupdown.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Finished Wait for udev To Complete Device Initialization.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Import ZFS pools by cache file...
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Condition check resulted in Import ZFS pools by device scanning being skipped.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Import ZFS pool VM01...
Dec 12 14:58:49 MOPROXMOX01 zpool[812]: cannot import 'VM01': pool already exists
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: zfs-import@VM01.service: Main process exited, code=exited, status=1/FAILURE
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: zfs-import@VM01.service: Failed with result 'exit-code'.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Failed to start Import ZFS pool VM01.
Dec 12 14:58:49 MOPROXMOX01 kernel: zd16: p1 p2
Dec 12 14:58:49 MOPROXMOX01 kernel: zd32: p1 p2 p3 p4
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Finished Import ZFS pools by cache file.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Reached target ZFS pool import target.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Mount ZFS filesystems...
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Wait for ZFS Volume (zvol) links in /dev...
SYSLOG:
Dec 12 14:58:49 MOPROXMOX01 kernel: usbcore: registered new interface driver snd-usb-audio
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Finished Helper to synchronize boot up for ifupdown.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Finished Wait for udev To Complete Device Initialization.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Import ZFS pools by cache file...
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Condition check resulted in Import ZFS pools by device scanning being skipped.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Import ZFS pool VM01...
Dec 12 14:58:49 MOPROXMOX01 zpool[812]: cannot import 'VM01': pool already exists
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: zfs-import@VM01.service: Main process exited, code=exited, status=1/FAILURE
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: zfs-import@VM01.service: Failed with result 'exit-code'.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Failed to start Import ZFS pool VM01.
Dec 12 14:58:49 MOPROXMOX01 kernel: zd16: p1 p2
Dec 12 14:58:49 MOPROXMOX01 kernel: zd32: p1 p2 p3 p4
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Finished Import ZFS pools by cache file.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Reached target ZFS pool import target.
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Mount ZFS filesystems...
Dec 12 14:58:49 MOPROXMOX01 systemd[1]: Starting Wait for ZFS Volume (zvol) links in /dev...
Hello All. I am curious if you ever came to a resolution on this issue. I don't like seeing errors ... even if they don't really affect anything.
I am also curious if it could be failing initially because the disk service is not fully operational, but then only moments later (milliseconds) zed runs and finds them. Could those milliseconds be all that was required for the ZFS import to succeed?
I am very new to this environment and learning, breaking, learning more...")
I have included my entire syslog if it helps, but I would really like to understand more about what is going on here too. This is a completely new install. Minor changes and updates. Preceeding tasks were as follows:

~~milliseconds later~~

I am also curious if it could be failing initially because the disk service is not fully operational, but then only moments later (milliseconds) zed runs and finds them. Could those milliseconds be all that was required for the ZFS import to succeed?
I am very new to this environment and learning, breaking, learning more...
I have included my entire syslog if it helps, but I would really like to understand more about what is going on here too. This is a completely new install. Minor changes and updates. Preceeding tasks were as follows:
- Install from usb drive
- Update source
- nano /etc/apt/sources.list
- Add lines:
#Not for production use
deb http://download.proxmox.com/debian buster pve-no-subscription
- Update / upgrade
- nano /etc/apt/sources.list.d/pve-enterprise.list
- Comment out
- #deb https://enterprise.proxmox.com/debian/pve buster pve-enterprise
- Comment out
- Update Distro:
- apt-get update
- Upgrade:
- apt dist-upgrade -y
- nano /etc/apt/sources.list.d/pve-enterprise.list
- Add two zfs mirrors
- zfsWDBlue500
- zfsNvmeMirror
~~milliseconds later~~
Attachments
Last edited:
@Stoiko Ivanov i have these exact same issues with a completely new install on a HP DL380p g8, its "unpopulated" for a coming install, after reading through the forum i understand its more a cosmetic issue as the pool in fact gets imported in the end.
I am however wondering if there is any wishes to try to find the issue?
The strange thing is that the boot volume does not get the same errors.
HP 410i raid card, all disks in separate RAID-0
pve boot disk is zfs raid 1 and my only other dataset "vol1" is 6 disks raidz2.
i can reinstall this server or just fire up another one with the same setup that i have if you guys want to have a crack on it.
could also post more logs if you want.
I am however wondering if there is any wishes to try to find the issue?
The strange thing is that the boot volume does not get the same errors.
HP 410i raid card, all disks in separate RAID-0
pve boot disk is zfs raid 1 and my only other dataset "vol1" is 6 disks raidz2.
i can reinstall this server or just fire up another one with the same setup that i have if you guys want to have a crack on it.
could also post more logs if you want.
Forgot to post my update that I ran the "remove /etc/systemd/system/zfs-import.target.wants/zfs-import@tankie.service" and everything has been working/booting without issue since on my end.
Would not recommend without fully backing up as I was in a position where I completed a full system backup and was not worried if everything failed.
Would not recommend without fully backing up as I was in a position where I completed a full system backup and was not worried if everything failed.