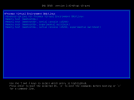
I have 3 SAS drives connected through a RAID card in JBOD, proxmox can see the drives properly, pool 'sas-backup' is made up of 1 vdev with single SAS drive and pool 'sas-vmdata' is made up of single vdev which in turn is built from 2 mirrored SAS drives. Everything seems to be working fine, however, system fails to import one of 3 zfs pools on boot with the following message:
The rest seem to import fine:
I have tried adding root delay in both grub and zfs configs with no luck. I have reinstalled proxmox a few times and recreated the same set-up with same error. Previous installation would display same error even after the pools were destroyed, so no idea why it was still trying to import. Any help/feedback greatly appreciated!
Running pve with no subscription. Version:
Code:
root@pve:~# systemctl status zfs-import@sas\\x2dbackup.service
● zfs-import@sas\x2dbackup.service - Import ZFS pool sas\x2dbackup
Loaded: loaded (/lib/systemd/system/zfs-import@.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Tue 2021-02-23 15:32:51 EST; 43min ago
Docs: man:zpool(8)
Process: 941 ExecStart=/sbin/zpool import -N -d /dev/disk/by-id -o cachefile=none sas-backup (code=exited, status=1/FAILURE)
Main PID: 941 (code=exited, status=1/FAILURE)
Feb 23 15:32:51 pve systemd[1]: Starting Import ZFS pool sas\x2dbackup...
Feb 23 15:32:51 pve zpool[941]: cannot import 'sas-backup': no such pool available
Feb 23 15:32:51 pve systemd[1]: zfs-import@sas\x2dbackup.service: Main process exited, code=exited, status=1/FAILURE
Feb 23 15:32:51 pve systemd[1]: zfs-import@sas\x2dbackup.service: Failed with result 'exit-code'.
Feb 23 15:32:51 pve systemd[1]: Failed to start Import ZFS pool sas\x2dbackup.The rest seem to import fine:
Code:
root@pve:~# systemctl | grep zfs
zfs-import-cache.service loaded active exited Import ZFS pools by cache file
● zfs-import@sas\x2dbackup.service loaded failed failed Import ZFS pool sas\x2dbackup
zfs-import@sas\x2dvmdata.service loaded active exited Import ZFS pool sas\x2dvmdata
zfs-import@sata\x2dstr0.service loaded active exited Import ZFS pool sata\x2dstr0
zfs-mount.service loaded active exited Mount ZFS filesystems
zfs-share.service loaded active exited ZFS file system shares
zfs-volume-wait.service loaded active exited Wait for ZFS Volume (zvol) links in /dev
zfs-zed.service loaded active running ZFS Event Daemon (zed)
system-zfs\x2dimport.slice loaded active active system-zfs\x2dimport.slice
zfs-import.target loaded active active ZFS pool import target
zfs-volumes.target loaded active active ZFS volumes are ready
zfs.target loaded active active ZFS startup targetI have tried adding root delay in both grub and zfs configs with no luck. I have reinstalled proxmox a few times and recreated the same set-up with same error. Previous installation would display same error even after the pools were destroyed, so no idea why it was still trying to import. Any help/feedback greatly appreciated!
Running pve with no subscription. Version:
Code:
root@pve:~# pveversion -v
proxmox-ve: 6.3-1 (running kernel: 5.4.98-1-pve)
pve-manager: 6.3-4 (running version: 6.3-4/0a38c56f)
pve-kernel-5.4: 6.3-5
pve-kernel-helper: 6.3-5
pve-kernel-5.4.98-1-pve: 5.4.98-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.1.0-pve1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: 0.8.35+pve1
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.20-pve1
libproxmox-acme-perl: 1.0.7
libproxmox-backup-qemu0: 1.0.3-1
libpve-access-control: 6.1-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.3-4
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.1-1
libpve-storage-perl: 6.3-7
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.0.8-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.4-5
pve-cluster: 6.2-1
pve-container: 3.3-4
pve-docs: 6.3-1
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-3
pve-firmware: 3.2-2
pve-ha-manager: 3.1-1
pve-i18n: 2.2-2
pve-qemu-kvm: 5.2.0-1
pve-xtermjs: 4.7.0-3
qemu-server: 6.3-5
smartmontools: 7.1-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.3-pve1
")