And ?You realize the PVE devs do not work on qemu and the linux kernel right?
[SOLVED] VMs freeze with 100% CPU
- Thread starter udo
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
We do, but not too many people and nobody has a full picture of all involved technologies, there's just way too much complexity for that.You realize the PVE devs do not work on qemu and the linux kernel right?
@fiona Could You please try with kernel-devel? Thread at qemu-devel https://lists.nongnu.org/archive/html/qemu-devel/2023-07/msg02073.html seems to be dead. Any plans to try a newer kernel from 6.x series ?
I could try, but I imagine most KVM people are also reading qemu-devel.@fiona Could You please try with kernel-devel?
We haven't been able to reproduce the issue yet, and we'll stay based on the Ubuntu kernel. But if you have a test system, you can try newer upstream kernels yourself (note that they don't have ZFS) via https://kernel.ubuntu.com/~kernel-ppa/mainline/Thread at qemu-devel https://lists.nongnu.org/archive/html/qemu-devel/2023-07/msg02073.html seems to be dead. Any plans to try a newer kernel from 6.x series ?
Hi,
yesterday we had one freeze more… but this happens to an VM with very low IO - so the issue is perhaps not realy IO-related and is more KSM-related.
The node only had app. 8.5GB memory KSM sharing (and round 60% Ram usage overall).
Due freezing, the VM-internal HA is working, and the second VM has take over all traffic (around 16:30).
On the VMs are only few software are running. This is the most used software there (Ubuntu) - mainly network traffic:
haproxy
shorewall
openvpn
telegraf
qemu-agent
heartbeat
nrpe
It's happens with this kind of VM rarely (now the second or third time), but now I've disabled KSM on this pve-node too.
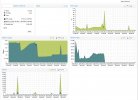
Screenshot with day max to show, that few IO is happens.
VM-config
BTW: If I remember right, all VMs which are freezed (also the most freezed Windows-VMs) has the qemu-agent running! Perhaps it's isn't related, but someone wrote, that bsd is stable (don't know if there an qemu-agent is active).
Udo
yesterday we had one freeze more… but this happens to an VM with very low IO - so the issue is perhaps not realy IO-related and is more KSM-related.
The node only had app. 8.5GB memory KSM sharing (and round 60% Ram usage overall).
Due freezing, the VM-internal HA is working, and the second VM has take over all traffic (around 16:30).
On the VMs are only few software are running. This is the most used software there (Ubuntu) - mainly network traffic:
haproxy
shorewall
openvpn
telegraf
qemu-agent
heartbeat
nrpe
It's happens with this kind of VM rarely (now the second or third time), but now I've disabled KSM on this pve-node too.
Screenshot with day max to show, that few IO is happens.
VM-config
Code:
agent: 1,fstrim_cloned_disks=1
boot: c
bootdisk: scsi0
cores: 2
cpu: host
hotplug: disk,network,usb,memory,cpu
keyboard: de
memory: 3072
name: NAME
net0: virtio=CE:2D:B2:EB:1E:18,bridge=vmbr0
net1: virtio=0A:77:4B:53:74:4C,bridge=vmbr1
numa: 1
onboot: 1
ostype: l26
scsi0: ssd-lvm:vm-104-disk-0,size=25G
scsi1: ssd-lvm:vm-104-disk-1,discard=on,size=10G
scsihw: virtio-scsi-single
serial0: socket
smbios1: uuid=58f34455-c592-493a-a058-aa44ee3a45ab
sockets: 2
tablet: 0
vcpus: 4BTW: If I remember right, all VMs which are freezed (also the most freezed Windows-VMs) has the qemu-agent running! Perhaps it's isn't related, but someone wrote, that bsd is stable (don't know if there an qemu-agent is active).
Udo
Attachments
Hi. Some days ago, my opnSense - based at FreeBSD frozen too and it was after restart it, after upgrade to the newets opnSense. But trick with hibernate/dehibernate worked like a charm! As so far, all my 3 vm had hit by this bug: 1. vm with Windows Server2022 standard; 2. vm with AlamaLinux 9.2 and 3. vm with opnSense based FreeBSD. And yes, QEMU Agent is installed at all 3 vms.Hi,
yesterday we had one freeze more… but this happens to an VM with very low IO - so the issue is perhaps not realy IO-related and is more KSM-related.
The node only had app. 8.5GB memory KSM sharing (and round 60% Ram usage overall).
Due freezing, the VM-internal HA is working, and the second VM has take over all traffic (around 16:30).
On the VMs are only few software are running. This is the most used software there (Ubuntu) - mainly network traffic:
haproxy
shorewall
openvpn
telegraf
qemu-agent
heartbeat
nrpe
It's happens with this kind of VM rarely (now the second or third time), but now I've disabled KSM on this pve-node too.
Screenshot with day max to show, that few IO is happens.
VM-config
Code:agent: 1,fstrim_cloned_disks=1 boot: c bootdisk: scsi0 cores: 2 cpu: host hotplug: disk,network,usb,memory,cpu keyboard: de memory: 3072 name: NAME net0: virtio=CE:2D:B2:EB:1E:18,bridge=vmbr0 net1: virtio=0A:77:4B:53:74:4C,bridge=vmbr1 numa: 1 onboot: 1 ostype: l26 scsi0: ssd-lvm:vm-104-disk-0,size=25G scsi1: ssd-lvm:vm-104-disk-1,discard=on,size=10G scsihw: virtio-scsi-single serial0: socket smbios1: uuid=58f34455-c592-493a-a058-aa44ee3a45ab sockets: 2 tablet: 0 vcpus: 4
BTW: If I remember right, all VMs which are freezed (also the most freezed Windows-VMs) has the qemu-agent running! Perhaps it's isn't related, but someone wrote, that bsd is stable (don't know if there an qemu-agent is active).
Udo
Last edited:
Hi guys,
so I had it so far with 2 VMs - both Ubuntu 22.04 LTS
Both VMs have the QEMU agent installed.
I have now deactivated KSM and ballooning once.
I haven't had any problems with the Windows servers yet.
However, I think the freezing is due to the CPU load of the VMs.
Regards
Rene
so I had it so far with 2 VMs - both Ubuntu 22.04 LTS
Both VMs have the QEMU agent installed.
I have now deactivated KSM and ballooning once.
I haven't had any problems with the Windows servers yet.
However, I think the freezing is due to the CPU load of the VMs.
Regards
Rene
Hey,
we are having the same issue for a couple of weeks now.
We deactivated KSM today and had another freeze just 20 minutes after.
Sadly we did not have the debugger installed yet, so I can only provide the strace (I ran it twice) and general vm information.
The VM is a windows server running SQL Server, so a lot of memory usage with 256GiB of memory assigned.
Compared to the others we don't have 99% ppoll, but still a high percentage with ~70%.
we are having the same issue for a couple of weeks now.
We deactivated KSM today and had another freeze just 20 minutes after.
Sadly we did not have the debugger installed yet, so I can only provide the strace (I ran it twice) and general vm information.
The VM is a windows server running SQL Server, so a lot of memory usage with 256GiB of memory assigned.
Compared to the others we don't have 99% ppoll, but still a high percentage with ~70%.
Code:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
73.10 4.069291 148 27378 ppoll
10.26 0.570895 42 13590 io_submit
8.63 0.480286 10 46514 write
4.97 0.276505 8 32585 read
1.21 0.067184 21 3098 recvmsg
1.14 0.063338 22 2851 37 futex
0.21 0.011657 38 300 mmap
0.21 0.011478 38 302 munmap
0.14 0.007699 12 600 rt_sigprocmask
0.09 0.004885 16 300 mprotect
0.07 0.003704 61 60 sendmsg
0.00 0.000026 2 13 close
0.00 0.000017 1 13 accept4
0.00 0.000007 0 26 fcntl
0.00 0.000004 0 13 getsockname
0.00 0.000002 0 3 ioctl
------ ----------- ----------- --------- --------- ----------------
100.00 5.566978 43 127646 37 total
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
70.23 5.649633 127 44434 ppoll
12.58 1.011917 20 49651 write
7.93 0.638248 15 42460 read
6.70 0.538956 33 16172 io_submit
1.01 0.081349 15 5098 67 futex
0.89 0.071507 14 4954 recvmsg
0.30 0.023958 46 517 munmap
0.10 0.008051 15 514 mmap
0.09 0.007488 325 23 accept4
0.09 0.007421 7 1028 rt_sigprocmask
0.06 0.004726 9 514 mprotect
0.01 0.000998 6 154 ioctl
0.00 0.000240 2 103 1 sendmsg
0.00 0.000183 7 23 close
0.00 0.000011 0 46 fcntl
0.00 0.000008 0 23 getsockname
0.00 0.000001 1 1 1 setsockopt
0.00 0.000000 0 1 getrandom
------ ----------- ----------- --------- --------- ----------------
100.00 8.044695 48 165716 69 total
Code:
agent: 1
balloon: 0
bootdisk: scsi0
cores: 10
cpu: host
cpuunits: 2048
hookscript: local:snippets/taskset-hook.sh
hotplug: disk,network,cpu
ide2: none,media=cdrom
localtime: 0
memory: 262144
name: vapp-220-sql
net0: virtio=EA:C3:C1:25:57:3A,bridge=vmbr0,firewall=1
net1: virtio=D6:30:4C:84:8F:2A,bridge=vmbr1,firewall=1
numa: 1
ostype: win10
sata0: none,media=cdrom
sata1: none,media=cdrom
scsi0: san-001-002:vm-220-disk-0,size=700G,ssd=1
scsi1: san-001-002:vm-220-disk-1,size=1G,ssd=1
scsi10: nas-backup-001-001:vm-220-disk-0,backup=0,size=7T,ssd=1
scsi11: san-003-002:vm-220-disk-0,iothread=1,size=3T,ssd=1
scsi2: san-001-002:vm-220-disk-2,size=1G,ssd=1
scsi3: san-001-002:vm-220-disk-3,size=1G,ssd=1
scsi4: san-001-002:vm-220-disk-4,backup=0,size=1536G,ssd=1
scsi5: san-002-002:vm-220-disk-0,backup=0,size=500G,ssd=1
scsi6: san-001-002:vm-220-disk-6,backup=0,size=300G,ssd=1
scsi7: san-001-002:vm-220-disk-7,backup=0,size=1000G,ssd=1
scsi8: san-001-002:vm-220-disk-8,backup=0,size=200G,ssd=1
scsi9: san-001-002:vm-220-disk-9,backup=0,size=200G,ssd=1
scsihw: virtio-scsi-pci
smbios1: uuid=f3e4fc16-4e9b-4f16-a5a9-b8a022305450
sockets: 2
unused0: san-003-001:vm-220-disk-1
vcpus: 20
vmgenid: 6b47aa34-a3e3-4b71-9c7f-be099ca83a8a
Code:
proxmox-ve: 8.0.1 (running kernel: 6.2.16-3-pve)
pve-manager: 8.0.3 (running version: 8.0.3/bbf3993334bfa916)
pve-kernel-6.2: 8.0.2
pve-kernel-5.15: 7.4-4
pve-kernel-5.13: 7.1-9
pve-kernel-5.11: 7.0-10
pve-kernel-5.4: 6.4-6
pve-kernel-6.2.16-3-pve: 6.2.16-3
pve-kernel-5.3: 6.1-6
pve-kernel-5.15.108-1-pve: 5.15.108-1
pve-kernel-5.13.19-6-pve: 5.13.19-15
pve-kernel-5.13.19-2-pve: 5.13.19-4
pve-kernel-5.11.22-7-pve: 5.11.22-12
pve-kernel-5.11.22-5-pve: 5.11.22-10
pve-kernel-5.4.140-1-pve: 5.4.140-1
pve-kernel-5.4.106-1-pve: 5.4.106-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
pve-kernel-5.4.65-1-pve: 5.4.65-1
pve-kernel-5.3.18-3-pve: 5.3.18-3
pve-kernel-5.3.10-1-pve: 5.3.10-1
ceph-fuse: 17.2.6-pve1+3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown: 0.8.41
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-3
libknet1: 1.25-pve1
libproxmox-acme-perl: 1.4.6
libproxmox-backup-qemu0: 1.4.0
libproxmox-rs-perl: 0.3.0
libpve-access-control: 8.0.3
libpve-apiclient-perl: 3.3.1
libpve-common-perl: 8.0.5
libpve-guest-common-perl: 5.0.3
libpve-http-server-perl: 5.0.3
libpve-rs-perl: 0.8.3
libpve-storage-perl: 8.0.2
libqb0: 1.0.5-1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 5.0.2-4
lxcfs: 5.0.3-pve3
novnc-pve: 1.4.0-2
openvswitch-switch: 3.1.0-2
proxmox-backup-client: 3.0.1-1
proxmox-backup-file-restore: 3.0.1-1
proxmox-kernel-helper: 8.0.2
proxmox-mail-forward: 0.2.0
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.1
proxmox-widget-toolkit: 4.0.5
pve-cluster: 8.0.1
pve-container: 5.0.4
pve-docs: 8.0.4
pve-edk2-firmware: 3.20230228-4
pve-firewall: 5.0.2
pve-firmware: 3.7-1
pve-ha-manager: 4.0.2
pve-i18n: 3.0.4
pve-qemu-kvm: 8.0.2-3
pve-xtermjs: 4.16.0-3
qemu-server: 8.0.6
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.1.12-pve1Hi,
Do you have 100% CPU usage, in particular in all the vCPU threads?
70% is not that unusual. QEMU uses ppoll to detect if there any events to handle in the main loop and IO threads, so there will be many ppoll calls. Just compare it with other VMs that are not frozen.Compared to the others we don't have 99% ppoll, but still a high percentage with ~70%.
Do you have 100% CPU usage, in particular in all the vCPU threads?
The futex errors might be a hint, but difficult to say without more information. Since it might not be the same issue, GDB traces might contain additional hints if we are lucky.Code:% time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 73.10 4.069291 148 27378 ppoll 10.26 0.570895 42 13590 io_submit 8.63 0.480286 10 46514 write 4.97 0.276505 8 32585 read 1.21 0.067184 21 3098 recvmsg 1.14 0.063338 22 2851 37 futex 0.21 0.011657 38 300 mmap 0.21 0.011478 38 302 munmap 0.14 0.007699 12 600 rt_sigprocmask 0.09 0.004885 16 300 mprotect 0.07 0.003704 61 60 sendmsg 0.00 0.000026 2 13 close 0.00 0.000017 1 13 accept4 0.00 0.000007 0 26 fcntl 0.00 0.000004 0 13 getsockname 0.00 0.000002 0 3 ioctl ------ ----------- ----------- --------- --------- ---------------- 100.00 5.566978 43 127646 37 total % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 70.23 5.649633 127 44434 ppoll 12.58 1.011917 20 49651 write 7.93 0.638248 15 42460 read 6.70 0.538956 33 16172 io_submit 1.01 0.081349 15 5098 67 futex 0.89 0.071507 14 4954 recvmsg 0.30 0.023958 46 517 munmap 0.10 0.008051 15 514 mmap 0.09 0.007488 325 23 accept4 0.09 0.007421 7 1028 rt_sigprocmask 0.06 0.004726 9 514 mprotect 0.01 0.000998 6 154 ioctl 0.00 0.000240 2 103 1 sendmsg 0.00 0.000183 7 23 close 0.00 0.000011 0 46 fcntl 0.00 0.000008 0 23 getsockname 0.00 0.000001 1 1 1 setsockopt 0.00 0.000000 0 1 getrandom ------ ----------- ----------- --------- --------- ---------------- 100.00 8.044695 48 165716 69 total
You have many disks, but iothread only on one of them. And you needCode:agent: 1 balloon: 0 bootdisk: scsi0 cores: 10 cpu: host cpuunits: 2048 hookscript: local:snippets/taskset-hook.sh hotplug: disk,network,cpu ide2: none,media=cdrom localtime: 0 memory: 262144 name: vapp-220-sql net0: virtio=EA:C3:C1:25:57:3A,bridge=vmbr0,firewall=1 net1: virtio=D6:30:4C:84:8F:2A,bridge=vmbr1,firewall=1 numa: 1 ostype: win10 sata0: none,media=cdrom sata1: none,media=cdrom scsi0: san-001-002:vm-220-disk-0,size=700G,ssd=1 scsi1: san-001-002:vm-220-disk-1,size=1G,ssd=1 scsi10: nas-backup-001-001:vm-220-disk-0,backup=0,size=7T,ssd=1 scsi11: san-003-002:vm-220-disk-0,iothread=1,size=3T,ssd=1 scsi2: san-001-002:vm-220-disk-2,size=1G,ssd=1 scsi3: san-001-002:vm-220-disk-3,size=1G,ssd=1 scsi4: san-001-002:vm-220-disk-4,backup=0,size=1536G,ssd=1 scsi5: san-002-002:vm-220-disk-0,backup=0,size=500G,ssd=1 scsi6: san-001-002:vm-220-disk-6,backup=0,size=300G,ssd=1 scsi7: san-001-002:vm-220-disk-7,backup=0,size=1000G,ssd=1 scsi8: san-001-002:vm-220-disk-8,backup=0,size=200G,ssd=1 scsi9: san-001-002:vm-220-disk-9,backup=0,size=200G,ssd=1 scsihw: virtio-scsi-pci smbios1: uuid=f3e4fc16-4e9b-4f16-a5a9-b8a022305450 sockets: 2 unused0: san-003-001:vm-220-disk-1 vcpus: 20 vmgenid: 6b47aa34-a3e3-4b71-9c7f-be099ca83a8a
scsihw: virtio-scsi-single instead of scsihw: virtio-scsi-pci as a prerequisite for the setting. I'd suggest using the correct SCSI controller and activating iothread for more/all of the disks. That can help with performance and sometimes guest hangs too.100% CPU usage shown in the web interface and the VM is non responsive. The monitoring running within the VM is also missing all data. The console via the web interface is also staying black.Do you have 100% CPU usage, in particular in all the vCPU threads?
Thank you, we will apply these changes.You have many disks, but iothread only on one of them. And you needscsihw: virtio-scsi-singleinstead ofscsihw: virtio-scsi-pcias a prerequisite for the setting. I'd suggest using the correct SCSI controller and activating iothread for more/all of the disks. That can help with performance and sometimes guest hangs too.
I will report back once we have an other freeze with a GDB trace.

Still running without freeze kilobug? We were also plagued by random freezes on 7.4 on kernel 5.19, 6.1 and 6.2 (AMD EPYC 7702P and 7713P here). Reverting to 5.15 solved it, but i am kinda worried about upgrading to proxmox 8 nowHello,
So it has been over 10 days since we upgraded to Proxmox 8.0, disabled KSM and mitigations, and we didn't have a single crash so far. So I'm starting to feel confident we actually "solved" the problem (even if disabling mitigations is not something I'm very happy about).
Regards,
") Well on 5.15 we are unable to live migrate (freezes after migration), but its lesser of the two evils.
Well on 5.15 we are unable to live migrate (freezes after migration), but its lesser of the two evils.Hi,Still running without freeze kilobug? We were also plagued by random freezes on 7.4 on kernel 5.19, 6.1 and 6.2 (AMD EPYC 7702P and 7713P here). Reverting to 5.15 solved it, but i am kinda worried about upgrading to proxmox 8 now
fiona wrote, that the migration issue is fixed: https://forum.proxmox.com/threads/vms-freeze-with-100-cpu.127459/page-6#post-578345
But I woudn't say, that this it's lesser of the two evils - in this case the whole node must be restartet and not only a single VM.
Udo
Well, we don't know it's the same migration issueHi,
fiona wrote, that the migration issue is fixed: https://forum.proxmox.com/threads/vms-freeze-with-100-cpu.127459/page-6#post-578345
But I woudn't say, that this it's lesser of the two evils - in this case the whole node must be restartet and not only a single VM.
Udo
")
Feel free to open a thread about the migration issue, sharing the output ofStill running without freeze kilobug? We were also plagued by random freezes on 7.4 on kernel 5.19, 6.1 and 6.2 (AMD EPYC 7702P and 7713P here). Reverting to 5.15 solved it, but i am kinda worried about upgrading to proxmox 8 now
pveversion -v for source and target and the configuration of an affected VM qm config <ID> --current. Do other VMs freeze too or just the migrated one?Well yes we need to restart the whole node, but its on our terms during maintenance window, not randomly anytime.Hi,
fiona wrote, that the migration issue is fixed: https://forum.proxmox.com/threads/vms-freeze-with-100-cpu.127459/page-6#post-578345
But I woudn't say, that this it's lesser of the two evils - in this case the whole node must be restartet and not only a single VM.
Udo
Probably not the same issue, it only happens from 7713P to 7702P (from higher frequency cpu to lower), not the other way around. And only the migrated VM is unresponsive right after migration. But we are gonna solve this with CPUs swap next year, the random freezes of running VMs on kernels above 5.15 are higher concern.Well, we don't know it's the same migration issue
Feel free to open a thread about the migration issue, sharing the output ofpveversion -vfor source and target and the configuration of an affected VMqm config <ID> --current. Do other VMs freeze too or just the migrated one?
What CPU type do you use in the VM configuration? Note that you cannot use typeProbably not the same issue, it only happens from 7713P to 7702P (from higher frequency cpu to lower), not the other way around. And only the migrated VM is unresponsive right after migration. But we are gonna solve this with CPUs swap next year, the random freezes of running VMs on kernels above 5.15 are higher concern.
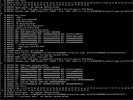
host if you have different physical CPUs: see the CPU Type section in https://pve.proxmox.com/pve-docs/chapter-qm.html#qm_cpuEPYC, tried with kvm64 and qemu64 with same result. Qemu64 at least produce the error on screenshot before freezing.What CPU type do you use in the VM configuration? Note that you cannot use typehostif you have different physical CPUs: see theCPU Typesection in https://pve.proxmox.com/pve-docs/chapter-qm.html#qm_cpu
Attachments
Last edited:
Yes, not a single crash so far. So upgrading to proxmox 8 (and the latest 6.2.16-6-pve kernel), disabling mitigations and KSM fixed it for us. I'm not exactly sure which part is responsible of it (and I can't really try, since it would negatively affect our production VM).Still running without freeze kilobug? We were also plagued by random freezes on 7.4 on kernel 5.19, 6.1 and 6.2 (AMD EPYC 7702P and 7713P here). Reverting to 5.15 solved it, but i am kinda worried about upgrading to proxmox 8 now