You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
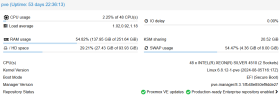
At least configuration of the vm with the issue is needed.
Also what OS is installed and if qemu guest agent is installed and running.
There is a known issue where vm configuration have qemu guest agent enabled but vm don't have the agent installed and running when clean shutdown from the host is not working (fix applied yesterday but new version with it not released), so for workaround in vm without qemu guest agent you must disable it also in the vm configuration so can do an ACPI shutdown.
Also what OS is installed and if qemu guest agent is installed and running.
There is a known issue where vm configuration have qemu guest agent enabled but vm don't have the agent installed and running when clean shutdown from the host is not working (fix applied yesterday but new version with it not released), so for workaround in vm without qemu guest agent you must disable it also in the vm configuration so can do an ACPI shutdown.
We have had Proxmox for 6 months.
We migrate VMs from VMware gradually, we also create new ones.
I have the impression that we had instability (the problem happened this morning!) by exceeding a certain number of VMs.
We resolved the defect temporarily by shutting down non-essential VMs.
I would like to know what could have created this; Here are the changes I made urgently:
In Datacenter/Option: Maximal Workers/Bulk-action 4 --> 8
I noticed that the SWAP usage was 100% of 8GB, I changed the swap to 1 with vm.swappiness = 1
thank you for your help
We migrate VMs from VMware gradually, we also create new ones.
I have the impression that we had instability (the problem happened this morning!) by exceeding a certain number of VMs.
We resolved the defect temporarily by shutting down non-essential VMs.
I would like to know what could have created this; Here are the changes I made urgently:
In Datacenter/Option: Maximal Workers/Bulk-action 4 --> 8
I noticed that the SWAP usage was 100% of 8GB, I changed the swap to 1 with vm.swappiness = 1
thank you for your help
The problem is not clear, from the first vague and dataless message it seemed that you had problems with the shutdown of the VMs from the host but from the second, also vague, perhaps you have a different problem.
If you have full swap on the host, I suppose that the ram is also full and that could be a serious situation that can make the host and the vms unstable.
Another problem I've seen recently is that proxmox doesn't block or warn if you overconfigure the vm ram but it all depends on the user to be careful how they configure it.
But this also remains a supposition, given the lack of data and details.
If you have full swap on the host, I suppose that the ram is also full and that could be a serious situation that can make the host and the vms unstable.
Another problem I've seen recently is that proxmox doesn't block or warn if you overconfigure the vm ram but it all depends on the user to be careful how they configure it.
But this also remains a supposition, given the lack of data and details.

I will try to clarify as much as possible ")
This morning, VMs were shutdown for no Reason, it's absolutely not wanted
Moreover, reactivating them causes the others to stop randomly.
I tell myself, ok this must come from a bad configuration or a resource problem
If you have full swap on the host, I suppose that the ram is also full and that could be a serious situation that can make the host and the vms unstable. --> Exactly, no we were at 54% of the RAM but on the other hand the SWAP was at 100%, I don't understand why
Also what OS is installed and if qemu guest agent is installed and running --> Windows server 2022 and Win 10 22H2. yes guest agent is installed
There is a known issue where vm configuration have qemu guest agent enabled but vm don't have the agent installed and running when clean shutdown from the host is not working --> Thanks for the information, I didn't know
This morning, VMs were shutdown for no Reason, it's absolutely not wanted
Moreover, reactivating them causes the others to stop randomly.
I tell myself, ok this must come from a bad configuration or a resource problem
If you have full swap on the host, I suppose that the ram is also full and that could be a serious situation that can make the host and the vms unstable. --> Exactly, no we were at 54% of the RAM but on the other hand the SWAP was at 100%, I don't understand why
Also what OS is installed and if qemu guest agent is installed and running --> Windows server 2022 and Win 10 22H2. yes guest agent is installed
There is a known issue where vm configuration have qemu guest agent enabled but vm don't have the agent installed and running when clean shutdown from the host is not working --> Thanks for the information, I didn't know
On windows vm you need to check also virtio version, there are version with important issue on disk drivers:
Just to clear up any confusion:
Per Vadim's comment above that post, the next stable public build will be released in mid-end of January 2025.
This should include the fixes for
- The fixes for the
viostor(VirtIO SCSI Controller) driver are NOT in v266. - The fixes for the
vioscsi(VirtIO SCSI pass-through controller) driver are in v266.
Per Vadim's comment above that post, the next stable public build will be released in mid-end of January 2025.
This should include the fixes for
viostor.root@pve:~/tmp/ovf# qm config 115
agent: 1
bios: ovmf
boot: order=scsi0;ide0;ide2;net0
cores: 8
cpu: host
efidisk0: local-lvm:vm-115-disk-0,efitype=4m,pre-enrolled-keys=1,size=4M
ide0: local:iso/virtio-win-0.1.262.iso,media=cdrom,size=708140K
ide2: local:iso/fr-fr_windows_server_2022_x64_dvd_9f7d1adb.iso,media=cdrom,size=5436092K
machine: pc-q35-9.0
memory: 16000
meta: creation-qemu=9.0.2,ctime=1728559892
name: 10.0.0.24-DATA-DAO
net0: virtio=BC:24:11:76:E5:65,bridge=vmbr0,firewall=1
numa: 0
ostype: win11
scsi0: local-lvm:vm-115-disk-1,cache=writeback,size=80G
scsi1: local-lvm:vm-115-disk-3,cache=writeback,size=2532G
scsihw: virtio-scsi-pci
smbios1: uuid=cbbd16cc-a097-448b-8f9e-4c869bb7ba12
sockets: 1
tags: f
tpmstate0: local-lvm:vm-115-disk-2,size=4M,version=v2.0
vmgenid: 972382af-765b-458b-ad25-8d1585332f5b
root@pve:~/tmp/ovf# qm config 118
agent: 1
bios: ovmf
boot: order=scsi0;ide0;ide2;net0
cores: 8
cpu: host
efidisk0: local-lvm:vm-118-disk-0,efitype=4m,pre-enrolled-keys=1,size=4M
ide0: local:iso/virtio-win-0.1.262.iso,media=cdrom,size=708140K
ide2: local:iso/fr-fr_windows_server_2022_x64_dvd_9f7d1adb.iso,media=cdrom,size=5436092K
machine: pc-q35-9.0
memory: 16000
meta: creation-qemu=9.0.2,ctime=1730275956
name: 10.0.0.25-DATA
net0: virtio=BC:24:11:B1:65:6F,bridge=vmbr0,firewall=1
numa: 0
onboot: 1
ostype: win11
scsi0: local-lvm:vm-118-disk-1,size=80G
scsi1: local-lvm:vm-118-disk-3,size=1500G
scsihw: virtio-scsi-pci
smbios1: uuid=4ecafe5c-5b56-405c-8188-13528faebe76
sockets: 1
tags: f
tpmstate0: local-lvm:vm-118-disk-2,size=4M,version=v2.0
vmgenid: 351a2ba3-7eaa-40ac-9ba0-9b8c4d55536a
----> VirtIO driver version : 100.95.104.26200
agent: 1
bios: ovmf
boot: order=scsi0;ide0;ide2;net0
cores: 8
cpu: host
efidisk0: local-lvm:vm-115-disk-0,efitype=4m,pre-enrolled-keys=1,size=4M
ide0: local:iso/virtio-win-0.1.262.iso,media=cdrom,size=708140K
ide2: local:iso/fr-fr_windows_server_2022_x64_dvd_9f7d1adb.iso,media=cdrom,size=5436092K
machine: pc-q35-9.0
memory: 16000
meta: creation-qemu=9.0.2,ctime=1728559892
name: 10.0.0.24-DATA-DAO
net0: virtio=BC:24:11:76:E5:65,bridge=vmbr0,firewall=1
numa: 0
ostype: win11
scsi0: local-lvm:vm-115-disk-1,cache=writeback,size=80G
scsi1: local-lvm:vm-115-disk-3,cache=writeback,size=2532G
scsihw: virtio-scsi-pci
smbios1: uuid=cbbd16cc-a097-448b-8f9e-4c869bb7ba12
sockets: 1
tags: f
tpmstate0: local-lvm:vm-115-disk-2,size=4M,version=v2.0
vmgenid: 972382af-765b-458b-ad25-8d1585332f5b
root@pve:~/tmp/ovf# qm config 118
agent: 1
bios: ovmf
boot: order=scsi0;ide0;ide2;net0
cores: 8
cpu: host
efidisk0: local-lvm:vm-118-disk-0,efitype=4m,pre-enrolled-keys=1,size=4M
ide0: local:iso/virtio-win-0.1.262.iso,media=cdrom,size=708140K
ide2: local:iso/fr-fr_windows_server_2022_x64_dvd_9f7d1adb.iso,media=cdrom,size=5436092K
machine: pc-q35-9.0
memory: 16000
meta: creation-qemu=9.0.2,ctime=1730275956
name: 10.0.0.25-DATA
net0: virtio=BC:24:11:B1:65:6F,bridge=vmbr0,firewall=1
numa: 0
onboot: 1
ostype: win11
scsi0: local-lvm:vm-118-disk-1,size=80G
scsi1: local-lvm:vm-118-disk-3,size=1500G
scsihw: virtio-scsi-pci
smbios1: uuid=4ecafe5c-5b56-405c-8188-13528faebe76
sockets: 1
tags: f
tpmstate0: local-lvm:vm-118-disk-2,size=4M,version=v2.0
vmgenid: 351a2ba3-7eaa-40ac-9ba0-9b8c4d55536a
----> VirtIO driver version : 100.95.104.26200
Attachments
Last edited:
virtio-win-0.1.262 is bugged on virtioscsi driver, and you should upgrade to .266
keep attention on virtio upgrade because can remove some network configuration fields and you need to insert them again after.
if you use lvm thin storage you should enable trim/discard in the vm disks configuration and inside the vm or you can have space issue (because don't free it when you delete something inside the vm)
other possible improvements is to enable iothread
keep attention on virtio upgrade because can remove some network configuration fields and you need to insert them again after.
if you use lvm thin storage you should enable trim/discard in the vm disks configuration and inside the vm or you can have space issue (because don't free it when you delete something inside the vm)
other possible improvements is to enable iothread
Last edited:
Thank you for your advice, I will update the drivers
I think my VM configuration is not optimal either or the problem of the SWAP at 100%
I think my VM configuration is not optimal either or the problem of the SWAP at 100%
Your Windows configs look ok. Maybe use
Your situation of 100% swap usage but non-saturated RAM is perplexing. Did you check the historic data (graphs) to see the RAM usage prior to this situation?
Do you use ZFS? If so be aware of the situation of SWAP on ZFS. Also you may want to look at the ARC settings here.
Has your RAM been tested? Have you checked the logs at the time of the VMs sudden shutdowns?
scsihw: virtio-scsi-single as this is now the default (& recommended) with IO Thread. You may get better performance.Your situation of 100% swap usage but non-saturated RAM is perplexing. Did you check the historic data (graphs) to see the RAM usage prior to this situation?
Do you use ZFS? If so be aware of the situation of SWAP on ZFS. Also you may want to look at the ARC settings here.
Be aware that to make this change boot-persistent you need to change it in theI changed the swap to 1 with vm.swappiness = 1
/etc/sysctl.conf file, as the above posted docs instruct.Has your RAM been tested? Have you checked the logs at the time of the VMs sudden shutdowns?
Hello, I have attached the system log
There are indeed some interesting things, "oom-kill" cuts off the VMs due to lack of memory.
Today the SWAP has returned to 91% despite yesterday's "vm.swappiness = 1".
We will test the RAM soon
exemple :
Dec 18 08:44:41 pve kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=qemu.slice,mems_allowed=0-1,global_oom,task_memcg=/qemu.slice/118.scope,task=kvm,pid=2297402,uid=0
Dec 18 08:44:41 pve kernel: Out of memory: Killed process 2297402 (kvm) total-vm:34039852kB, anon-rss:32798808kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:65088kB oom_score_adj:0
Dec 18 08:44:41 pve systemd[1]: 118.scope: A process of this unit has been killed by the OOM killer.
Dec 18 08:44:41 pve systemd[1]: 118.scope: Failed with result 'oom-kill'.
Dec 18 08:44:41 pve systemd[1]: 118.scope: Consumed 35min 32.420s CPU time.
Dec 18 08:44:41 pve kernel: fwbr118i0: port 2(tap118i0) entered disabled state
Dec 18 08:44:41 pve kernel: tap118i0 (unregistering): left allmulticast mode
Dec 18 08:44:41 pve kernel: fwbr118i0: port 2(tap118i0) entered disabled state
Dec 18 08:44:41 pve qmeventd[2546033]: Starting cleanup for 118
@gfngfn256
ok pour "scsihw: virtio-scsi-single" , I just added "/etc/sysctl.conf" for boot-persistent
RAM usage ~40-55% max (we have 256GB)
I don't use ZFS, should I instead of LVM ?
thanks
There are indeed some interesting things, "oom-kill" cuts off the VMs due to lack of memory.
Today the SWAP has returned to 91% despite yesterday's "vm.swappiness = 1".
We will test the RAM soon
exemple :
Dec 18 08:44:41 pve kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=qemu.slice,mems_allowed=0-1,global_oom,task_memcg=/qemu.slice/118.scope,task=kvm,pid=2297402,uid=0
Dec 18 08:44:41 pve kernel: Out of memory: Killed process 2297402 (kvm) total-vm:34039852kB, anon-rss:32798808kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:65088kB oom_score_adj:0
Dec 18 08:44:41 pve systemd[1]: 118.scope: A process of this unit has been killed by the OOM killer.
Dec 18 08:44:41 pve systemd[1]: 118.scope: Failed with result 'oom-kill'.
Dec 18 08:44:41 pve systemd[1]: 118.scope: Consumed 35min 32.420s CPU time.
Dec 18 08:44:41 pve kernel: fwbr118i0: port 2(tap118i0) entered disabled state
Dec 18 08:44:41 pve kernel: tap118i0 (unregistering): left allmulticast mode
Dec 18 08:44:41 pve kernel: fwbr118i0: port 2(tap118i0) entered disabled state
Dec 18 08:44:41 pve qmeventd[2546033]: Starting cleanup for 118
@gfngfn256
ok pour "scsihw: virtio-scsi-single" , I just added "/etc/sysctl.conf" for boot-persistent
RAM usage ~40-55% max (we have 256GB)
I don't use ZFS, should I instead of LVM ?
thanks
Attachments
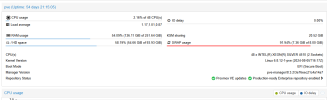
Last edited:
So is confirmed is a problem related to ram configuration of the vm (the host shouldn't have a huge ram consumption since you don't use zfs FWIK, unless you have installed/configured something special).
As I spotted recently proxmox don't have any protection or warning if user set and start vms with too many ram to cause issue and it all depends on the users (how they configure and start the VMs): https://forum.proxmox.com/threads/l...ms-have-balloning-disabled.158904/post-729948
The first thing to do would be to check all the ram configurations of the vm, I think that at least the sum of the minimum ram size of all the vm enabled must not be > (total host ram -1gb), otherwise the probability of killing processes in the vm (if there is ram managed by ballooning) and by the host (including the killing of qemu processes and therefore "brutal shutdown" of the vm) is very high.
If instead of the minimum memory you consider the maximum, then you should almost eliminate the risk (but you could have a significant underutilization of ram). For example on the kvm servers that I manage (not proxmox, to which I am migrating in production only in the last few months) for many years I have not used dynamic ram management but all the vms with minimum and maximum ram equivalent and whose sum does not exceed that of the host -2 gb and I have eliminated such problems.
As I spotted recently proxmox don't have any protection or warning if user set and start vms with too many ram to cause issue and it all depends on the users (how they configure and start the VMs): https://forum.proxmox.com/threads/l...ms-have-balloning-disabled.158904/post-729948
The first thing to do would be to check all the ram configurations of the vm, I think that at least the sum of the minimum ram size of all the vm enabled must not be > (total host ram -1gb), otherwise the probability of killing processes in the vm (if there is ram managed by ballooning) and by the host (including the killing of qemu processes and therefore "brutal shutdown" of the vm) is very high.
If instead of the minimum memory you consider the maximum, then you should almost eliminate the risk (but you could have a significant underutilization of ram). For example on the kvm servers that I manage (not proxmox, to which I am migrating in production only in the last few months) for many years I have not used dynamic ram management but all the vms with minimum and maximum ram equivalent and whose sum does not exceed that of the host -2 gb and I have eliminated such problems.
Last edited: