Hi,
On a few of our VMs we see the following behaviour when a backup runs.
The backup started at 05:00:02
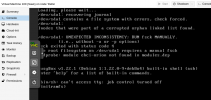
From the outside the VM seems fine (proxmox summary page), but when the backup started the OS changed the disk into read-only mode
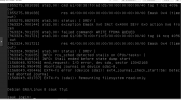
Some time later VM experiences extreme IO degradation:
.png")
The io returns to normal almost immediately after the backup has been canceled (for the above the backup was canceled at 16:16:31)
This has happened a few days in a row.
Today the VM experienced the IO degradation roughly 3 hours after the backup started.
The machine has the following disks mounted via sata:
70G
1050G
1050G
200G
150G
The usual symptom is the disk entering read-only mode, like in the logs above, the last two days have just seen io degradation without read-only mode.
And in very rare occasions leads to the VM corrupting it's partition table (happened to a different VM yesterday).
I read somewhere that a disk's sectors get locked when performing a backup and unlocked once processed, is this true, could this be the cause?
Where can we start to investigate this issue?
Backups run to PBS (although this particular VM changes most of it's disk every day so the incremental backups don't shave off much of the time it takes)
The filesystem on hosts is ZFS for linux.
Hosts have 10gbe.
Thanks for any help
On a few of our VMs we see the following behaviour when a backup runs.
The backup started at 05:00:02
From the outside the VM seems fine (proxmox summary page), but when the backup started the OS changed the disk into read-only mode
Code:
Oct 25 05:00:57 *******-SQL-02 kernel: [5294216.466540] EXT4-fs error (device sdb1): ext4_journal_check_start:61: Detected aborted journal
Oct 25 05:00:57 *******-SQL-02 kernel: [5294216.470832] EXT4-fs (sdb1): Remounting filesystem read-only
Oct 25 05:00:57 *******-SQL-02 kernel: [5294216.529257] EXT4-fs error (device sdb1) in ext4_reserve_inode_write:5875: Journal has abortedSome time later VM experiences extreme IO degradation:
The io returns to normal almost immediately after the backup has been canceled (for the above the backup was canceled at 16:16:31)
This has happened a few days in a row.
Today the VM experienced the IO degradation roughly 3 hours after the backup started.
The machine has the following disks mounted via sata:
70G
1050G
1050G
200G
150G
The usual symptom is the disk entering read-only mode, like in the logs above, the last two days have just seen io degradation without read-only mode.
And in very rare occasions leads to the VM corrupting it's partition table (happened to a different VM yesterday).
I read somewhere that a disk's sectors get locked when performing a backup and unlocked once processed, is this true, could this be the cause?
Where can we start to investigate this issue?
Backups run to PBS (although this particular VM changes most of it's disk every day so the incremental backups don't shave off much of the time it takes)
The filesystem on hosts is ZFS for linux.
Hosts have 10gbe.
Thanks for any help

")

")