Hi guys.
I know that there are some topics with this bug but mine still istn solved.
I have still unsolved problem with some of servers.
I have like 3 host servers and many VMs on those.
Sometimes (totally radom time, and VM) of Guest Debian 7 linux hang...
"task xxx blocked for more than 120 seconds"
It happen mostly where there is not mutch going on inside Guest.
After that VM is not responding and only Reset helps.
Anyway i tried may things to solve this
Which all have in common is that
- qcow2 format
- Virt IO driver
- writeback cache
When i set IDE instead of VirtIO problem is solved but also i have poor performance, and some problems while backupping whole VM while running.
Anyway i tried many kernels also in Host (including newest 4.2.6) and also in guest.
Host proxmox kernel: Linux node1 4.2.6-1-pve #1 SMP Thu Jan 21 09:34:06 CET 2016 x86_64 GNU/Linux
VM kernel: 3.2.0-4-amd64 #1 SMP Debian 3.2.68-1+deb7u2 x86_64 GNU/Linux
Sysctl config of VM:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
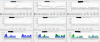
I was able o catch this moment on charts (the moment when cpu drops to zero and also IO disk - after some while you can see that i restarted VM and then everything back to normlal.
This bug is one that i have in half of my setups and its pretty anoying.
Please help")
Here are screens:




I know that there are some topics with this bug but mine still istn solved.
I have still unsolved problem with some of servers.
I have like 3 host servers and many VMs on those.
Sometimes (totally radom time, and VM) of Guest Debian 7 linux hang...
"task xxx blocked for more than 120 seconds"
It happen mostly where there is not mutch going on inside Guest.
After that VM is not responding and only Reset helps.
Anyway i tried may things to solve this
Which all have in common is that
- qcow2 format
- Virt IO driver
- writeback cache
When i set IDE instead of VirtIO problem is solved but also i have poor performance, and some problems while backupping whole VM while running.
Anyway i tried many kernels also in Host (including newest 4.2.6) and also in guest.
Host proxmox kernel: Linux node1 4.2.6-1-pve #1 SMP Thu Jan 21 09:34:06 CET 2016 x86_64 GNU/Linux
VM kernel: 3.2.0-4-amd64 #1 SMP Debian 3.2.68-1+deb7u2 x86_64 GNU/Linux
Sysctl config of VM:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
I was able o catch this moment on charts (the moment when cpu drops to zero and also IO disk - after some while you can see that i restarted VM and then everything back to normlal.
This bug is one that i have in half of my setups and its pretty anoying.
Please help
Here are screens: