Hi All,
For the last year i'm running a proxmox cluster with 7 nodes, and except for some minor issue, everything went fine until yesterday.
Yesterday, adding a new node to the cluster (something i did, obviously, several times) i experienced three of the 7 existing nodes to reboot suddenly with no apparent reason. And this lead to a temporary disaster in which for several minutes all our VMs went down.
At this point i'm still struggling to understand what happened, and I'm a bit stucked because I don't feel confortable to attempt to add the new node again to the cluster.
I'm attaching the syslogs for the joining node and from one of the nodes that suffered the sudden reboot.
Anyone can help me to understand?
For the last year i'm running a proxmox cluster with 7 nodes, and except for some minor issue, everything went fine until yesterday.
Yesterday, adding a new node to the cluster (something i did, obviously, several times) i experienced three of the 7 existing nodes to reboot suddenly with no apparent reason. And this lead to a temporary disaster in which for several minutes all our VMs went down.
At this point i'm still struggling to understand what happened, and I'm a bit stucked because I don't feel confortable to attempt to add the new node again to the cluster.
I'm attaching the syslogs for the joining node and from one of the nodes that suffered the sudden reboot.
Anyone can help me to understand?
Attachments
Last edited:
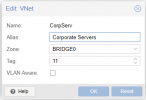
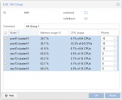
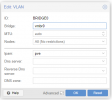
") anything particular/non-default about your corosync.conf?
anything particular/non-default about your corosync.conf?