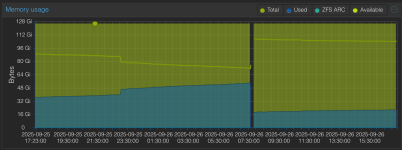
Hi,
Same thing here:
Same thing here:
- Ceph for VM disks and ISO images
- Ethernet controller: Intel Corporation Ethernet Controller E810-XXV for SFP (rev 02)
- Ethernet controller [0200]: Intel Corporation Ethernet Controller E810-XXV for SFP [8086:159b] (rev 02)
Subsystem: Intel Corporation Device [8086:0000]
Kernel driver in use: ice
Kernel modules: ice
Code:
root@pve3:~# cat /proc/cmdline
BOOT_IMAGE=/vmlinuz-6.14.11-2-pve root=UUID=d31b7e52-6351-474c-b8e8-e757557089ac ro nomodeset iommu=pt console=tty0 console=ttyS0,115200n8