Dell T440 here. Unifi network stack though.Maybe the Unifi UNAS Pro is the common link? Seems like a couple of us have the same NAS.
Anyone having this issue not on the Unifi UNAS Pro?
Severe system freeze with NFS on Proxmox 9 running kernel 6.14.8-2-pve when mounting NFS shares
- Thread starter Krailler
- Start date
-
- Tags
- kernel 6.14 n100 pve 9.0.0~11
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

+1 to this. Running PVE 9.1.5 with kernel 6.14. I have an OpenMediaVault VM which has a disk passed through and exposes a few NFS shares that are mounted in various LXCs and the PVE host itself. During heavy writes CPUs in the OMV MV become hung and occasionally deadlocks the entire host.
I've seen similar behavior running PVE 9.1.5 with kernel 6.17 and also with OMV 8.1 kernel 6.18 and OMV 7.4 with kernels 6.1 and 6.12.
I've seen similar behavior running PVE 9.1.5 with kernel 6.17 and also with OMV 8.1 kernel 6.18 and OMV 7.4 with kernels 6.1 and 6.12.
Has this just "magically" gone away for people or just me?
I have had a huge media conversion job running for the past 8 hours and it has not hung once (normally it cant do more than 30 mins).
I have had a huge media conversion job running for the past 8 hours and it has not hung once (normally it cant do more than 30 mins).
What version are you on? 9.1.6 seams to have improved things, but I don't know if it is 100% resolved.Has this just "magically" gone away for people or just me?
I have had a huge media conversion job running for the past 8 hours and it has not hung once (normally it cant do more than 30 mins).
I have a Dell t440 with TrueNAS and Plex in VMs. Yesterday one of my friends got "Please check that this file exist and the necessary drive is mounted." which has been indicative of this issue, but overall I'm not seeing the kinds of errors or other issues I was before.
I am on 9.1.6What version are you on? 9.1.6 seams to have improved things, but I don't know if it is 100% resolved.
I have a Dell t440 with TrueNAS and Plex in VMs. Yesterday one of my friends got "Please check that this file exist and the necessary drive is mounted." which has been indicative of this issue, but overall I'm not seeing the kinds of errors or other issues I was before.
pve-container is 6.1.2 (which was the thing that had the update that initially started causing me issues. `(dpkg -l | grep pve-container)`
FWIW, I switched my one share that experiences heavy writes to CIFS shortly after posting this and it has been stable for ~1 week so far.+1 to this. Running PVE 9.1.5 with kernel 6.14. I have an OpenMediaVault VM which has a disk passed through and exposes a few NFS shares that are mounted in various LXCs and the PVE host itself. During heavy writes CPUs in the OMV MV become hung and occasionally deadlocks the entire host.
I've seen similar behavior running PVE 9.1.5 with kernel 6.17 and also with OMV 8.1 kernel 6.18 and OMV 7.4 with kernels 6.1 and 6.12.
I'm also suffering this bug:
Hardware:
Proxmox host CPU: AMD Phenom II X6 1090T (AM3)
Proxmox host RAM: 32GB ECC DDR3
NVMe: WD Black SN7100 1TB (VMs/LXC storage)
NFS server: Debian 13 VM running inside the same Proxmox host, ZFS RAIDZ1 4×14TB (passed through), 16GB RAM, ZFS ARC limited to 10GB
Software:
Proxmox VE 9.1 / kernel 6.17.13-1-pve
NFS server: NFSv4.2, sync mount
vzdump backing up to NFS storage (backup-NAS)
Symptoms:
During vzdump backup to NFS storage, the entire Proxmox host freezes and requires hard reboot. The WebUI becomes unresponsive and SSH dies. Interestingly, VMs keep running and communicating with each other via the internal bridge (vmbr0): a Home Assistant VM continued receiving sensor data from an ebusd LXC container via MQTT, with no gaps in the historical graphs - proving that internal VM-to-VM traffic was unaffected while host networking was completely frozen.
Note on bandwidth limiting: Limiting vzdump bandwidth via bwlimit in /etc/vzdump.conf delays the freeze but does not prevent it. The deadlock occurs regardless of write speed, confirming it is not a saturation issue but a fundamental problem in the NFS client under sustained write load.
The NFS mount options at time of freeze:
dmesg from Proxmox host (kernel 6.17.13-1-pve):
Additional evidence isolating the NFS client as the root cause:
The same NFS server exports shares to other physical machines on the network running Debian 13 with kernel 6.12.73+deb13-amd64, all working without any issues under heavy load. This rules out a server-side problem and strongly suggests the issue is specific to the NFSv4.2 client implementation in the Proxmox 6.17-pve kernel, as the standard Debian 6.12 kernel is unaffected.
To further rule out vzdump as a factor, a direct copy of a qcow2 file from the Proxmox host to the NFS mount was performed:
This produced identical symptoms: host freeze, unresponsive WebUI, SSH dead, requiring hard reboot. This confirms the issue is purely the NFS client in kernel 6.17-pve under heavy write load, completely unrelated to vzdump.
Workaround:
Pinning kernel to 6.8.12-18-pve resolved the issue completely. Backups and direct NFS copies now run at full speed (~120 MB/s) without any freezes:
Maybe Related:
Mainline kernel bug report: https://bugzilla.kernel.org/show_bug.cgi?id=219508 (NFS write lockup introduced in 6.11)
Additional notes:
Reproduced consistently with both async and sync NFS mounts
ZFS ARC on NFS server was also limited to 10GB (from default unlimited) as a precaution, but this alone did not solve the issue
vzdump tmpdir set to local NVMe (/etc/vzdump.conf: tmpdir: /mnt/pve/nvme-vms/vzdump-tmp) for performance reasons, but unrelated to the freeze
Hardware:
Proxmox host CPU: AMD Phenom II X6 1090T (AM3)
Proxmox host RAM: 32GB ECC DDR3
NVMe: WD Black SN7100 1TB (VMs/LXC storage)
NFS server: Debian 13 VM running inside the same Proxmox host, ZFS RAIDZ1 4×14TB (passed through), 16GB RAM, ZFS ARC limited to 10GB
Software:
Proxmox VE 9.1 / kernel 6.17.13-1-pve
NFS server: NFSv4.2, sync mount
vzdump backing up to NFS storage (backup-NAS)
Symptoms:
During vzdump backup to NFS storage, the entire Proxmox host freezes and requires hard reboot. The WebUI becomes unresponsive and SSH dies. Interestingly, VMs keep running and communicating with each other via the internal bridge (vmbr0): a Home Assistant VM continued receiving sensor data from an ebusd LXC container via MQTT, with no gaps in the historical graphs - proving that internal VM-to-VM traffic was unaffected while host networking was completely frozen.
Note on bandwidth limiting: Limiting vzdump bandwidth via bwlimit in /etc/vzdump.conf delays the freeze but does not prevent it. The deadlock occurs regardless of write speed, confirming it is not a saturation issue but a fundamental problem in the NFS client under sustained write load.
The NFS mount options at time of freeze:
Code:
nas:/backup/proxmox-VMs on /mnt/pve/backup-NAS type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,fatal_neterrors=none,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.1.40,local_lock=none,addr=192.168.1.250)dmesg from Proxmox host (kernel 6.17.13-1-pve):
Code:
[ 1107.487583] INFO: task CPU 2/KVM:1947 blocked for more than 245 seconds.
[ 1107.487591] Tainted: P O 6.17.13-1-pve #1
...
[ 1107.487626] __schedule+0x468/0x1310
[ 1107.487660] schedule+0x27/0xf0
[ 1107.487673] folio_wait_bit_common+0x124/0x2f0
[ 1107.487708] folio_wait_writeback+0x2b/0xa0
[ 1107.487721] nfs_wb_folio+0x94/0x1e0 [nfs]
[ 1107.487893] nfs_release_folio+0x72/0x110 [nfs]
...
[ 5285.096199] INFO: task iou-wrk-1941:24182 is blocked on an rw-semaphore
[ 5285.096224] task:iou-wrk-1941 state:D ...
[ 5285.096296] rwsem_down_read_slowpath+0x24e/0x540
[ 5285.096308] down_read+0x48/0xc0
[ 5285.096328] do_exit+0x1f2/0xa20
[ 5285.096339] io_wq_worker+0x2d6/0x390
...
[ 5343.886173] systemd[1]: systemd-journald.service: start operation timed out. Terminating.Additional evidence isolating the NFS client as the root cause:
The same NFS server exports shares to other physical machines on the network running Debian 13 with kernel 6.12.73+deb13-amd64, all working without any issues under heavy load. This rules out a server-side problem and strongly suggests the issue is specific to the NFSv4.2 client implementation in the Proxmox 6.17-pve kernel, as the standard Debian 6.12 kernel is unaffected.
To further rule out vzdump as a factor, a direct copy of a qcow2 file from the Proxmox host to the NFS mount was performed:
Code:
cp /mnt/pve/nvme-vms/images/202/vm-202-disk-0.qcow2 /mnt/pve/backup-NAS/test.qcow2This produced identical symptoms: host freeze, unresponsive WebUI, SSH dead, requiring hard reboot. This confirms the issue is purely the NFS client in kernel 6.17-pve under heavy write load, completely unrelated to vzdump.
Workaround:
Pinning kernel to 6.8.12-18-pve resolved the issue completely. Backups and direct NFS copies now run at full speed (~120 MB/s) without any freezes:
Code:
proxmox-boot-tool kernel pin 6.8.12-18-pve
proxmox-boot-tool refresh
rebootMaybe Related:
Mainline kernel bug report: https://bugzilla.kernel.org/show_bug.cgi?id=219508 (NFS write lockup introduced in 6.11)
Additional notes:
Reproduced consistently with both async and sync NFS mounts
ZFS ARC on NFS server was also limited to 10GB (from default unlimited) as a precaution, but this alone did not solve the issue
vzdump tmpdir set to local NVMe (/etc/vzdump.conf: tmpdir: /mnt/pve/nvme-vms/vzdump-tmp) for performance reasons, but unrelated to the freeze
Last edited:
Workaround:
Pinning kernel to 6.8.12-18-pve resolved the issue completely. Backups now run at full speed (~120 MB/s) without any freezes nor direct NFS copies:
Code:proxmox-boot-tool kernel pin 6.8.12-18-pve proxmox-boot-tool refresh reboot
Thank you for putting this all together!! I will try this.
Last edited:
Hi @kouellette,+1 to this. Running PVE 9.1.5 with kernel 6.14. I have an OpenMediaVault VM which has a disk passed through and exposes a few NFS shares that are mounted in various LXCs and the PVE host itself. During heavy writes CPUs in the OMV MV become hung and occasionally deadlocks the entire host.
I've seen similar behavior running PVE 9.1.5 with kernel 6.17 and also with OMV 8.1 kernel 6.18 and OMV 7.4 with kernels 6.1 and 6.12.
I'm having the same issue with PVE 9.1.6 (kernel 6.17) and a similar OpenMediaVault setup. For me, the OMV VM usually breaks first, while other VMs may stay available for a day or two. If it hasn't crashed yet, the entire host will definitely go down when I try to stop the OMV VM.
Have you found a solution yet (e.g., pinning one of the proposed kernels)?
Dell T640 running Proxmox with Plex and Truenas VMs. Since updating to 9.1.6 Plex reading from TrueNAS over NFS had substantially improved.
I do have a fairly complicated network setup with using bonded network connections to different switches. I was playing with both balance-rr and balance-alb, but switching to the simpler active-backup the last of my issues seam to have vanished.
I do have a fairly complicated network setup with using bonded network connections to different switches. I was playing with both balance-rr and balance-alb, but switching to the simpler active-backup the last of my issues seam to have vanished.
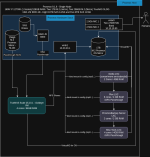
Hello everyone, I am also seeing intermittent NFS deadlocks that force me to reboot the entire server. This is my first proxmox deployment but I'm not new to hypervisors. I've tried to add as much detail as possible about my setup below and in the diagram.
The attached logical diagram of the Rube Goldberg machine is what I've cobbled together under the guidance of internet posts and AI. The purpose of the server is to handle plex, its associated supporting applications like sonarr, and serve files shares for five people or less. The iGPU on the i7 is passed through to the Plex and tools LXC for transcoding tasks.
Truenas scale is setup as a VM running on proxmox and the entire HBA is passed through. The two 256 M.2 drives are setup as a SLOG for the main ~100TB array. A cronjob (every minute) on the proxmox host checks to see if the NFS shares are mounted and mounts them if they are not for the LXCs to use.
Here is an example from /etc/fstab on proxmox host:
Then the LXCs, Plex for example, use the folder to scan and serve media.
For the most part, the server runs ok, but almost every night it will hang. I don't suspect the backup jobs because they run without issue on demand, even the job that backups up the truenas VM to truenas storage does not create significant I/O and completes relatively quickly.
However, I have noticed that the Plex jobs (credits scan for "skip intro" and other tasks) seem to cause issues. However, trying to run these tasks using curl and sending puts to the API did not crash the server - oddly enough.
I am unsure if this is expected behavior or I was doing something unwise, but I wrote a shell script to download a list of files, read from a txt file, using curl. It first it seemed fine, but then after a few files, the server became unresponsive. I ran this in the tools LXC, downloading the files to the mounted NFS on the proxmox host (through the bind mount in the LXC.) I later revised the script to throttle the downlaod speeds to 25Mbit and it still hung the server.
The logs aren't very helpful since I suspect the I/O issues are blocking the logs being written. Another oddity is that I can often open a SSH session on the proxmox host, but as soon as I type /mnt/ and hit <tab> it locks up the terminal. I have to kill the terminal.
I'm not really sure what else to check to troubleshoot this issue. I'm open to suggestions on what to check or changes to the overall architecture. Anyone have any ideas? I've seen mixed results on pinning 6.8 kernel. Will this help?
Some of the things I tried:
- Changed from NFSv4 to NFSv3 (not much success)
- Created vmbr1 (10.20.20.99) for traffic separation
- Tinkered/optimized fstab settings (soft, timeo=30, retrans=2,actimeo=0, noac, bg, retry=3)
- Added bind mounts to containers (instead of NFS inside containers)
- Created systemd mount units
- Adjusted container startup delays
- Created service to wait for truenas to start
- Auto-remount on failure
- ensure-nfs-mounted cron job (every minute)
- Installed 2× 256GB NVMe as mirrored SLOG
- etc etc etc
The attached logical diagram of the Rube Goldberg machine is what I've cobbled together under the guidance of internet posts and AI. The purpose of the server is to handle plex, its associated supporting applications like sonarr, and serve files shares for five people or less. The iGPU on the i7 is passed through to the Plex and tools LXC for transcoding tasks.
Truenas scale is setup as a VM running on proxmox and the entire HBA is passed through. The two 256 M.2 drives are setup as a SLOG for the main ~100TB array. A cronjob (every minute) on the proxmox host checks to see if the NFS shares are mounted and mounts them if they are not for the LXCs to use.
Here is an example from /etc/fstab on proxmox host:
Code:
10.20.20.99:/mnt/Pool/Media /mnt/truenas-media nfs vers=4.1,soft,timeo=30,retrans=2,noatime,nofail,_netdev,x-systemd.mount-timeout=30s 0 0Then the LXCs, Plex for example, use the folder to scan and serve media.
For the most part, the server runs ok, but almost every night it will hang. I don't suspect the backup jobs because they run without issue on demand, even the job that backups up the truenas VM to truenas storage does not create significant I/O and completes relatively quickly.
However, I have noticed that the Plex jobs (credits scan for "skip intro" and other tasks) seem to cause issues. However, trying to run these tasks using curl and sending puts to the API did not crash the server - oddly enough.
I am unsure if this is expected behavior or I was doing something unwise, but I wrote a shell script to download a list of files, read from a txt file, using curl. It first it seemed fine, but then after a few files, the server became unresponsive. I ran this in the tools LXC, downloading the files to the mounted NFS on the proxmox host (through the bind mount in the LXC.) I later revised the script to throttle the downlaod speeds to 25Mbit and it still hung the server.
The logs aren't very helpful since I suspect the I/O issues are blocking the logs being written. Another oddity is that I can often open a SSH session on the proxmox host, but as soon as I type /mnt/ and hit <tab> it locks up the terminal. I have to kill the terminal.
I'm not really sure what else to check to troubleshoot this issue. I'm open to suggestions on what to check or changes to the overall architecture. Anyone have any ideas? I've seen mixed results on pinning 6.8 kernel. Will this help?
Some of the things I tried:
- Changed from NFSv4 to NFSv3 (not much success)
- Created vmbr1 (10.20.20.99) for traffic separation
- Tinkered/optimized fstab settings (soft, timeo=30, retrans=2,actimeo=0, noac, bg, retry=3)
- Added bind mounts to containers (instead of NFS inside containers)
- Created systemd mount units
- Adjusted container startup delays
- Created service to wait for truenas to start
- Auto-remount on failure
- ensure-nfs-mounted cron job (every minute)
- Installed 2× 256GB NVMe as mirrored SLOG
- etc etc etc
Attachments

i moved away from proxmox the stability was bad even after downgrading.Where are we with this now, nearly 2 months later?
What did you switch to?i moved away from proxmox the stability was bad even after downgrading.
I'm still on 8.4 with an updated kernel ( 6.8.12-22-pve ). Lots of nfs connections on the proxmox host to TN (a vm on this host with the onboard sata controllers passed through). No issue as far as stability. I've been very hesitant to update to 9.x given all these issues and heavy use of nfs here.
I suppose there is the option of pinning the older (6.8 or 6.12) kernel with prox 9.x, but im not ready to go through the effort yet.
I wish I stayed on pve8 longer. After this issue, I pinned to 6.8.12-20-pve from 6.17.13-2-pve and have been stable since. Sadly, the original issue corrupted my zfs pool during a scrub, so I’ve been slowly restoring/rebuilding things from older backups (thank you 3, 2, 1!).
I’m hesitant to move up to the newer kernels as I use a TrueNAS VM on pve to nfs shares into the Proxmox host, mostly for backups.
In my case, I have the SATA controller and the NVMe drives passed through to the VM via PCIe pass through.
I’m hesitant to move up to the newer kernels as I use a TrueNAS VM on pve to nfs shares into the Proxmox host, mostly for backups.
In my case, I have the SATA controller and the NVMe drives passed through to the VM via PCIe pass through.
I have updates on my installation stability. With the upgrade to pve-qemu-kvm 11.0 from 10.2.1, proxmox 8 kernel (6.8.12) was having trouble with i/o threading.
Suddenly every vm was queueing I/o, to the point that global iodelay was greater than 50%
Deactivating "I/O threads" on VMs worked around the problem, but with a performance penalty.
It was not surprising me, proxmox 8 kernel with proxmox 9 userspace is not a supported combination. It was a matter of time that problems arose.
So... I gave it another shot to proxmox 9 kernel (6.17.13). I upgraded to the lastest available one: 6.17.13-11-pve vs initial known-to-fail 6.17.13-1.
10 kernel revisions, I had not much hope, because my stability with 6.17.13+NFS client on proxmox host was really bad, but I had no other option but to try to upgrade.
So, after unpinning 6.8.12 kernel and rebooting, and trying to avoid ZFS corruption, I unmounted every NFS on my home network. I created a 100 GB volume on internal NVME, presented it to NAS VM and exported it instead of ZFS.
I copied big files until 100GB volume was full several times. I launched 4 simultaneous copies to the same NAS exported filesystem, copying at ~430 MB/s to NFS filesystem. And proxmox now was rock solid.
It was a BIG improvement. With 6.17.13-1 I couldn't copy more than ~5-10 GB without deadlocking proxmox host.
But the environment was not the same, so I now tried to mount several NFS exports from NAS ZFS on various external clients simulating read load, and launched parallel copies again on proxmox. Rock solid.
As I couldn't reproduce bug, and everything seemed stable, I remounted proxmox backup FS from NAS ZFS, and run the test again. Everything fine. Finally, I launched backups, that were the initial problem I saw...
Nothing, not a single error on dmesg.
This was on may 22, so I can say I had 5 days of stability with 5 nights of backups, and had not a single crash, nor error messages on dmesg.
I cannot 100% assure kernel was the only problem. A lot of other proxmox 9 packages were upgraded since march 8, so it can be kernel, other package or both")
But these two links I found about kernel 6.17 point to a massive NFS code refactoring:
https://www.phoronix.com/news/NFS-Linux-6.17
https://lore.kernel.org/lkml/f94837ec978d8ca505006f024b3cae3c920e5f58.camel@kernel.org/
6.17.13 was the last one in 6.17 series, but ubuntu (from which proxmox kernel is based) is still launching revisions. So they probably backported NFS client code from newest kernels... but I'm only guessing, because I couldn't find ubuntu 6.17.13 kernel changelog...
I will try to downgrade to old 6.17.13-1 kernel this evening and launch tests again. If I'm able to deadlock proxmox, then I'll can assure kernel was the problem.
I will post my results.
Hope this helps anyone. I'm now happy with my stable proxmox 9")
Suddenly every vm was queueing I/o, to the point that global iodelay was greater than 50%
Deactivating "I/O threads" on VMs worked around the problem, but with a performance penalty.
It was not surprising me, proxmox 8 kernel with proxmox 9 userspace is not a supported combination. It was a matter of time that problems arose.
So... I gave it another shot to proxmox 9 kernel (6.17.13). I upgraded to the lastest available one: 6.17.13-11-pve vs initial known-to-fail 6.17.13-1.
10 kernel revisions, I had not much hope, because my stability with 6.17.13+NFS client on proxmox host was really bad, but I had no other option but to try to upgrade.
So, after unpinning 6.8.12 kernel and rebooting, and trying to avoid ZFS corruption, I unmounted every NFS on my home network. I created a 100 GB volume on internal NVME, presented it to NAS VM and exported it instead of ZFS.
I copied big files until 100GB volume was full several times. I launched 4 simultaneous copies to the same NAS exported filesystem, copying at ~430 MB/s to NFS filesystem. And proxmox now was rock solid.
It was a BIG improvement. With 6.17.13-1 I couldn't copy more than ~5-10 GB without deadlocking proxmox host.
But the environment was not the same, so I now tried to mount several NFS exports from NAS ZFS on various external clients simulating read load, and launched parallel copies again on proxmox. Rock solid.
As I couldn't reproduce bug, and everything seemed stable, I remounted proxmox backup FS from NAS ZFS, and run the test again. Everything fine. Finally, I launched backups, that were the initial problem I saw...
Nothing, not a single error on dmesg.
This was on may 22, so I can say I had 5 days of stability with 5 nights of backups, and had not a single crash, nor error messages on dmesg.
I cannot 100% assure kernel was the only problem. A lot of other proxmox 9 packages were upgraded since march 8, so it can be kernel, other package or both
But these two links I found about kernel 6.17 point to a massive NFS code refactoring:
https://www.phoronix.com/news/NFS-Linux-6.17
https://lore.kernel.org/lkml/f94837ec978d8ca505006f024b3cae3c920e5f58.camel@kernel.org/
6.17.13 was the last one in 6.17 series, but ubuntu (from which proxmox kernel is based) is still launching revisions. So they probably backported NFS client code from newest kernels... but I'm only guessing, because I couldn't find ubuntu 6.17.13 kernel changelog...
I will try to downgrade to old 6.17.13-1 kernel this evening and launch tests again. If I'm able to deadlock proxmox, then I'll can assure kernel was the problem.
I will post my results.
Hope this helps anyone. I'm now happy with my stable proxmox 9
Update — root cause found
My previous conclusion was inaccurate. Here is the full picture after more investigation today.
Reproduction
On any 6.17.13-x kernel, with pve-qemu-kvm 11.0.0-4, a sustained NFS write load (e.g. 4× parallel dd or cp) reliably deadlocks the proxmox host within ~5-10 GB of data. The dmesg shows the classic chain:
nfs: server nas not responding, still trying
INFO: task CPU x/KVM blocked for more than 122 seconds.
nfs_wb_folio → folio_wait_writeback
→ __folio_split → migrate_pages_batch
→ kvm_mmu_faultin_pfn → npf_interception [kvm_amd]
INFO: task worker:xxxx is blocked on an rw-semaphore,
but the owner is not found. (×N workers)
This was also the case with older pve-quemu-kvm versions, which made me stay with 6.8 kernel for a while.
Downgrading to pve-qemu-kvm 11.0.0-3 + qemu-server 9.1.15 completely eliminates the issue — all 6.17.13 kernels (-1, -11, -13) pass extended stress tests with no deadlock. The NAS VM stops freezing under load, the NFS server keeps responding, and the host stays stable.
The 11.0.0-4 changelog mentions backported fixes for aio=native and virtio-blk. This combination appears to cause the NAS VM itself to stall under sustained write load — which then triggers the known NFS writeback deadlock in the 6.17 kernel client.
Summary
Workarounds
1. Downgrade to pve-qemu-kvm 11.0.0-3 and hold the package.
2. Upgrade to kernel 7.0.6 (which also resolves it).
Note: the QEMU 11.0.0-4 trigger only affects setups where the NFS server is a KVM VM on the same Proxmox host with iothread enabled. However, the underlying kernel 6.17 NFS client deadlock is independent — any condition that causes the NFS server to stop responding can trigger it, including external NAS under load.
For Proxmox developers (some of you replied earlier in this thread):
I believe I have isolated a regression in pve-qemu-kvm 11.0.0-4 that causes instability with NFS when running proxmox-kernel-6.17.13 (the supported kernel for Proxmox VE 9).
With pve-qemu-kvm 11.0.0-3, the environment was completely stable under heavy NFS load — extended stress tests, parallel copies, nightly backups, no issues. After upgrading to 11.0.0-4, any sustained NFS write load reliably deadlocks the host within a few gigabytes, with the call trace shown above. Downgrading back to 11.0.0-3 immediately restores stability.
The 11.0.0-4 changelog mentions backported fixes for aio=native, virtio-blk, and aio. One of those commits appears to cause the NAS VM to stall under write load, which then triggers the NFS client deadlock in the 6.17 kernel. The regression is bisectable: 11.0.0-3 = stable, 11.0.0-4 = broken, on all tested 6.17.13 variants (-1, -11, -13).
Kernel 7.0.6 is not affected — no NFS errors in dmesg, no instability observed under the same load.
Hope this helps narrow it down.
My previous conclusion was inaccurate. Here is the full picture after more investigation today.
Reproduction
On any 6.17.13-x kernel, with pve-qemu-kvm 11.0.0-4, a sustained NFS write load (e.g. 4× parallel dd or cp) reliably deadlocks the proxmox host within ~5-10 GB of data. The dmesg shows the classic chain:
nfs: server nas not responding, still trying
INFO: task CPU x/KVM blocked for more than 122 seconds.
nfs_wb_folio → folio_wait_writeback
→ __folio_split → migrate_pages_batch
→ kvm_mmu_faultin_pfn → npf_interception [kvm_amd]
INFO: task worker:xxxx is blocked on an rw-semaphore,
but the owner is not found. (×N workers)
This was also the case with older pve-quemu-kvm versions, which made me stay with 6.8 kernel for a while.
Downgrading to pve-qemu-kvm 11.0.0-3 + qemu-server 9.1.15 completely eliminates the issue — all 6.17.13 kernels (-1, -11, -13) pass extended stress tests with no deadlock. The NAS VM stops freezing under load, the NFS server keeps responding, and the host stays stable.
The 11.0.0-4 changelog mentions backported fixes for aio=native and virtio-blk. This combination appears to cause the NAS VM itself to stall under sustained write load — which then triggers the known NFS writeback deadlock in the 6.17 kernel client.
Summary
| pve-qemu-kvm 11.0.0-3 + any 6.17.13 | ✓ stable |
| pve-qemu-kvm 11.0.0-4 + any 6.17.13 | ✗ NFS deadlock under load |
| pve-qemu-kvm 11.0.0-4 + kernel 7.0.6 | ✓ stable |
1. Downgrade to pve-qemu-kvm 11.0.0-3 and hold the package.
2. Upgrade to kernel 7.0.6 (which also resolves it).
Note: the QEMU 11.0.0-4 trigger only affects setups where the NFS server is a KVM VM on the same Proxmox host with iothread enabled. However, the underlying kernel 6.17 NFS client deadlock is independent — any condition that causes the NFS server to stop responding can trigger it, including external NAS under load.
For Proxmox developers (some of you replied earlier in this thread):
I believe I have isolated a regression in pve-qemu-kvm 11.0.0-4 that causes instability with NFS when running proxmox-kernel-6.17.13 (the supported kernel for Proxmox VE 9).
With pve-qemu-kvm 11.0.0-3, the environment was completely stable under heavy NFS load — extended stress tests, parallel copies, nightly backups, no issues. After upgrading to 11.0.0-4, any sustained NFS write load reliably deadlocks the host within a few gigabytes, with the call trace shown above. Downgrading back to 11.0.0-3 immediately restores stability.
The 11.0.0-4 changelog mentions backported fixes for aio=native, virtio-blk, and aio. One of those commits appears to cause the NAS VM to stall under write load, which then triggers the NFS client deadlock in the 6.17 kernel. The regression is bisectable: 11.0.0-3 = stable, 11.0.0-4 = broken, on all tested 6.17.13 variants (-1, -11, -13).
Kernel 7.0.6 is not affected — no NFS errors in dmesg, no instability observed under the same load.
Hope this helps narrow it down.
@Davidegb You need to send me a way to give you money for a coffee or beer (seriously). You absolutely just saved me.
My results were slightly different than yours however. Kernel 7.0.6-2-pve did NOT resolve my situation. However DOWNGRADING pve-qemu-kvm WORKED IMMEDIATELY!
FWIW I'm using qemu-server 9.1.16 as well. All that was required (for me) was the downgrade of pve-qemu-kvm.
For anyone else who sees this:
```
apt install pve-qemu-kvm=11.0.0-3
apt-mark hold pve-qemu-kvm
apt-mark showholds
```
Then reboot all of your containers (system restart is not required (at least for me))
@Maximiliano any chance this can get looked into? It's been broken for months at this point.
My results were slightly different than yours however. Kernel 7.0.6-2-pve did NOT resolve my situation. However DOWNGRADING pve-qemu-kvm WORKED IMMEDIATELY!
FWIW I'm using qemu-server 9.1.16 as well. All that was required (for me) was the downgrade of pve-qemu-kvm.
For anyone else who sees this:
```
apt install pve-qemu-kvm=11.0.0-3
apt-mark hold pve-qemu-kvm
apt-mark showholds
```
Then reboot all of your containers (system restart is not required (at least for me))
@Maximiliano any chance this can get looked into? It's been broken for months at this point.
Last edited: