Hi,
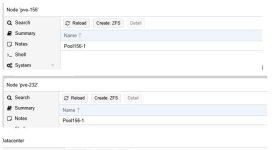
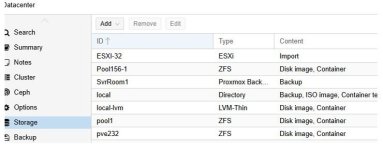
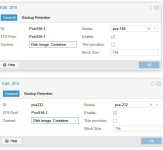
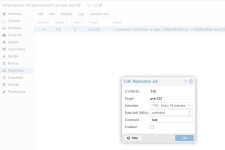
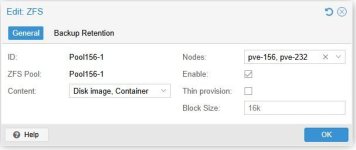
I'm trying to set up a simple replication between two hosts in a cluster that use local storage. I've set up the zfs pools with the same pool name, added them to datacenter storage, and created a replication job (see attached images). The replication fails after 1.3s with this error:
command '/usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=pve-232' -o 'UserKnownHostsFile=/etc/pve/nodes/pve-232/ssh_known_hosts' -o 'GlobalKnownHostsFile=none' root@192.168.120.232 -- pvesr prepare-local-job 119-0 Pool156-1:vm-119-disk-0 --last_sync 0' failed: exit code 255
I think I've followed the steps based on the documentation - what am I missing?
Thanks - Ed
I'm trying to set up a simple replication between two hosts in a cluster that use local storage. I've set up the zfs pools with the same pool name, added them to datacenter storage, and created a replication job (see attached images). The replication fails after 1.3s with this error:
command '/usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=pve-232' -o 'UserKnownHostsFile=/etc/pve/nodes/pve-232/ssh_known_hosts' -o 'GlobalKnownHostsFile=none' root@192.168.120.232 -- pvesr prepare-local-job 119-0 Pool156-1:vm-119-disk-0 --last_sync 0' failed: exit code 255
I think I've followed the steps based on the documentation - what am I missing?
Thanks - Ed
")