Hallo,
ich fahre jetzt seit Jahren Proxmox VE und war bis Oktober auch sehr zufrieden. Im September hab ich meinen Main Host bei Hetzner upgraded auf EX62-NVME, da 16 CPU Threads, 64GB Ram und ein 2x1TB NVMe Raid 1 bei dem Preis-/Leistungsverhältnis unschlagbar ist. Relativ zeitnah muss dann auch das Proxmox VE 6 Update gekommen sein, was ich mit einem Dist-Upgrade dann auch drüber gespielt habe.
Seit Oktober besteht nun der Fall, dass der Host alle 10-20 Tage crasht. Anfangs musste ich im Hetzner Robot den Host dann manuell resetten, damit er wieder online kam. Seit Kernel 5.3 rebooted der Host zumindest selbständig und man ist nicht stundenlang offline, wenn so etwas mitten in der Nacht passiert.
Ich habe bereits die komplette Hardware tauschen lassen, die NVMe Drives einzeln tauschen lassen, Proxmox VE vom aktuellen Hetzner Image ueber das Rescue System noch ein mal neu installiert. Ausserdem hab ich aufgrund des I219-LM (rev 10) Netzwerkadapters, der in anderen Threads als problematisch angegeben wird, alles an Offloading deaktiviert, sogar testweise den aktuellen Intel Base Treiber (der Kernel Treiber ist wirklich sehr veraltet) per DKMS ausprobiert. Ich habe testweise einzeln Features deaktiviert, wie Nested Virtualization, Kernel Samepage Mapping. Extra CPU Flags der VMs habe ich entfernt, um den Host die Flags uebergeben zu lassen.
Seit dem Hardware Austausch vor einem Tag und der Neu-Installation von PVE 6.1 crasht der Host sogar alle 3 Stunden. Aktuell teste ich ob Memory Ballooning das Problem sein koennte, und habe den RAM bei allen VMs statisch eingestellt, bei der WIndows VM sogar den Ballooning Service deinstalliert, den Ballooning Treiber deaktiviert und Ballooning in der VM Config komplett deaktiviert. Die Windows 10 1909 VM nutzt die derzeit aktuellen Fedora virtio Treiber 0.1.173 und qemu-agent. Die anderen Hosts laufen entweder auf Fedora 32, pfSense (FreeBSD), CentOS7 oder Debian 10. Bis auf die Windows VM (kvm64) sind alle anderen VMs mit Host CPU konfiguriert. Alle VMs nutzen das Discard Feature für ihre Disks (LVM-Thin) mit VirtIO-SCSI. Seit der Neu-Installation laeuft alles per Defaults, ich habe ausschliesslich den Replication Runner von minutely auf monthly gestellt (kein Cluster), um dem Wearout gegenzuwirken.
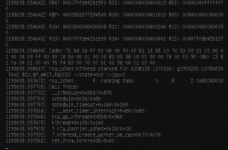
Was alle Crashes gemeinsam haben: Trotz sehr verbosem Logging gibt es exakt NICHTS an Gruenden zu sehen, warum der Host rebooted hat. Nicht eine auffaellige Zeile, auch kein wiederkehrendes Muster an Dingen, die der Host eventuell kurz vor dem Crash begonnen hat. Anhand anderer Threads, nicht nur hier im Forum, erkenne ich dass ich bei dem Problem wohl nicht alleine bin, es berichten auch insgesamt 5 andere Personen von Crash Issues in der Kombination EX62-NVME und PVE 6.1.
Kdump gab mir keine Informationen, ich bin aber nicht sicher, ob kdump richtig funktioniert hat, der Crash Kernel war jedenfalls geladen. Ich bin so langsam mit meinem Latein am Ende. Vielleicht finden Sich ja andere Betroffene, die eventuell sogar eine Lösung gefunden haben?
------------------------------------
00:00.0 Host bridge: Intel Corporation 8th Gen Core 8-core Desktop Processor Host Bridge/DRAM Registers [Coffee Lake S] (rev 0a)
00:01.0 PCI bridge: Intel Corporation Skylake PCIe Controller (x16) (rev 0a)
00:02.0 VGA compatible controller: Intel Corporation Device 3e98
00:12.0 Signal processing controller: Intel Corporation Cannon Lake PCH Thermal Controller (rev 10)
00:14.0 USB controller: Intel Corporation Cannon Lake PCH USB 3.1 xHCI Host Controller (rev 10)
00:14.2 RAM memory: Intel Corporation Cannon Lake PCH Shared SRAM (rev 10)
00:16.0 Communication controller: Intel Corporation Cannon Lake PCH HECI Controller (rev 10)
00:17.0 SATA controller: Intel Corporation Cannon Lake PCH SATA AHCI Controller (rev 10)
00:1b.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port (rev f0)
00:1d.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port (rev f0)
00:1f.0 ISA bridge: Intel Corporation Device a308 (rev 10)
00:1f.4 SMBus: Intel Corporation Cannon Lake PCH SMBus Controller (rev 10)
00:1f.5 Serial bus controller [0c80]: Intel Corporation Cannon Lake PCH SPI Controller (rev 10)
00:1f.6 Ethernet controller: Intel Corporation Ethernet Connection (7) I219-LM (rev 10)
01:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981
02:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
Stepping: 12
CPU MHz: 4759.163
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Linux hv1 5.3.13-1-pve #1 SMP PVE 5.3.13-1 (Thu, 05 Dec 2019 07:18:14 +0100) x86_64 GNU/Linux
total used free shared buff/cache available
Mem: 62Gi 19Gi 42Gi 54Mi 701Mi 42Gi
Swap: 6.0Gi 0B 6.0Gi
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg0-root 9.8G 2.2G 7.2G 23% /
/dev/md0 990M 69M 871M 8% /boot
/dev/mapper/vg0-data 196G 61M 186G 1% /data
//storage/backup 500G 231G 270G 47% /mnt/pve/storage
/dev/md0 on /boot type ext3 (rw,relatime)
/dev/mapper/vg0-data on /data type ext4 (rw,relatime,stripe=128)
//storage/backup on /mnt/pve/storage type cifs (rw,relatime,vers=3.0,cache=strict,username=whatever,uid=0,noforceuid,gid=0,noforcegid,addr=1.2.3.4,file_mode=0755,dir_mode=0755,soft,nounix,serverino,mapposix,rsize=4194304,wsize=4194304,bsize=1048576,echo_interval=60,actimeo=1)
State : clean
Number Major Minor RaidDevice State
0 259 4 0 active sync /dev/nvme1n1p1
1 259 2 1 active sync /dev/nvme0n1p1
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data vg0 Vwi-aotz-- 200.00g pve 2.09
pve vg0 twi-aotz-- 936.50g 15.13 17.90
root vg0 -wi-ao---- 10.00g
swap vg0 -wi-ao---- 6.00g
vm-100-disk-0 vg0 Vwi-aotz-- 20.00g pve 16.03
vm-101-disk-0 vg0 Vwi-aotz-- 25.00g pve 54.40
vm-102-disk-0 vg0 Vwi-aotz-- 25.00g pve 64.62
vm-103-disk-0 vg0 Vwi-aotz-- 40.00g pve 58.75
vm-103-disk-1 vg0 Vwi-aotz-- 50.00g pve 52.68
vm-104-disk-0 vg0 Vwi-aotz-- 32.00g pve 29.85
vm-104-disk-1 vg0 Vwi-aotz-- 50.00g pve 32.25
vm-105-disk-0 vg0 Vwi-aotz-- 10.00g pve 51.22
vm-106-disk-0 vg0 Vwi-aotz-- 20.00g pve 27.94
vm-107-disk-0 vg0 Vwi-aotz-- 8.00g pve 32.04
vm-109-disk-0 vg0 Vwi-aotz-- 8.00g pve 23.00
vm-110-disk-0 vg0 Vwi-aotz-- 32.00g pve 22.27
vm-111-disk-0 vg0 Vwi-aotz-- 32.00g pve 19.02
vm-112-disk-0 vg0 Vwi-a-tz-- 8.00g pve 9.03
# cat /sys/module/kvm_intel/parameters/nested
N
# cat /sys/kernel/mm/ksm/run
0
ich fahre jetzt seit Jahren Proxmox VE und war bis Oktober auch sehr zufrieden. Im September hab ich meinen Main Host bei Hetzner upgraded auf EX62-NVME, da 16 CPU Threads, 64GB Ram und ein 2x1TB NVMe Raid 1 bei dem Preis-/Leistungsverhältnis unschlagbar ist. Relativ zeitnah muss dann auch das Proxmox VE 6 Update gekommen sein, was ich mit einem Dist-Upgrade dann auch drüber gespielt habe.
Seit Oktober besteht nun der Fall, dass der Host alle 10-20 Tage crasht. Anfangs musste ich im Hetzner Robot den Host dann manuell resetten, damit er wieder online kam. Seit Kernel 5.3 rebooted der Host zumindest selbständig und man ist nicht stundenlang offline, wenn so etwas mitten in der Nacht passiert.
Ich habe bereits die komplette Hardware tauschen lassen, die NVMe Drives einzeln tauschen lassen, Proxmox VE vom aktuellen Hetzner Image ueber das Rescue System noch ein mal neu installiert. Ausserdem hab ich aufgrund des I219-LM (rev 10) Netzwerkadapters, der in anderen Threads als problematisch angegeben wird, alles an Offloading deaktiviert, sogar testweise den aktuellen Intel Base Treiber (der Kernel Treiber ist wirklich sehr veraltet) per DKMS ausprobiert. Ich habe testweise einzeln Features deaktiviert, wie Nested Virtualization, Kernel Samepage Mapping. Extra CPU Flags der VMs habe ich entfernt, um den Host die Flags uebergeben zu lassen.
Seit dem Hardware Austausch vor einem Tag und der Neu-Installation von PVE 6.1 crasht der Host sogar alle 3 Stunden. Aktuell teste ich ob Memory Ballooning das Problem sein koennte, und habe den RAM bei allen VMs statisch eingestellt, bei der WIndows VM sogar den Ballooning Service deinstalliert, den Ballooning Treiber deaktiviert und Ballooning in der VM Config komplett deaktiviert. Die Windows 10 1909 VM nutzt die derzeit aktuellen Fedora virtio Treiber 0.1.173 und qemu-agent. Die anderen Hosts laufen entweder auf Fedora 32, pfSense (FreeBSD), CentOS7 oder Debian 10. Bis auf die Windows VM (kvm64) sind alle anderen VMs mit Host CPU konfiguriert. Alle VMs nutzen das Discard Feature für ihre Disks (LVM-Thin) mit VirtIO-SCSI. Seit der Neu-Installation laeuft alles per Defaults, ich habe ausschliesslich den Replication Runner von minutely auf monthly gestellt (kein Cluster), um dem Wearout gegenzuwirken.
Was alle Crashes gemeinsam haben: Trotz sehr verbosem Logging gibt es exakt NICHTS an Gruenden zu sehen, warum der Host rebooted hat. Nicht eine auffaellige Zeile, auch kein wiederkehrendes Muster an Dingen, die der Host eventuell kurz vor dem Crash begonnen hat. Anhand anderer Threads, nicht nur hier im Forum, erkenne ich dass ich bei dem Problem wohl nicht alleine bin, es berichten auch insgesamt 5 andere Personen von Crash Issues in der Kombination EX62-NVME und PVE 6.1.
Kdump gab mir keine Informationen, ich bin aber nicht sicher, ob kdump richtig funktioniert hat, der Crash Kernel war jedenfalls geladen. Ich bin so langsam mit meinem Latein am Ende. Vielleicht finden Sich ja andere Betroffene, die eventuell sogar eine Lösung gefunden haben?
------------------------------------
00:00.0 Host bridge: Intel Corporation 8th Gen Core 8-core Desktop Processor Host Bridge/DRAM Registers [Coffee Lake S] (rev 0a)
00:01.0 PCI bridge: Intel Corporation Skylake PCIe Controller (x16) (rev 0a)
00:02.0 VGA compatible controller: Intel Corporation Device 3e98
00:12.0 Signal processing controller: Intel Corporation Cannon Lake PCH Thermal Controller (rev 10)
00:14.0 USB controller: Intel Corporation Cannon Lake PCH USB 3.1 xHCI Host Controller (rev 10)
00:14.2 RAM memory: Intel Corporation Cannon Lake PCH Shared SRAM (rev 10)
00:16.0 Communication controller: Intel Corporation Cannon Lake PCH HECI Controller (rev 10)
00:17.0 SATA controller: Intel Corporation Cannon Lake PCH SATA AHCI Controller (rev 10)
00:1b.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port (rev f0)
00:1d.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port (rev f0)
00:1f.0 ISA bridge: Intel Corporation Device a308 (rev 10)
00:1f.4 SMBus: Intel Corporation Cannon Lake PCH SMBus Controller (rev 10)
00:1f.5 Serial bus controller [0c80]: Intel Corporation Cannon Lake PCH SPI Controller (rev 10)
00:1f.6 Ethernet controller: Intel Corporation Ethernet Connection (7) I219-LM (rev 10)
01:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981
02:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
Stepping: 12
CPU MHz: 4759.163
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Linux hv1 5.3.13-1-pve #1 SMP PVE 5.3.13-1 (Thu, 05 Dec 2019 07:18:14 +0100) x86_64 GNU/Linux
total used free shared buff/cache available
Mem: 62Gi 19Gi 42Gi 54Mi 701Mi 42Gi
Swap: 6.0Gi 0B 6.0Gi
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg0-root 9.8G 2.2G 7.2G 23% /
/dev/md0 990M 69M 871M 8% /boot
/dev/mapper/vg0-data 196G 61M 186G 1% /data
//storage/backup 500G 231G 270G 47% /mnt/pve/storage
/dev/md0 on /boot type ext3 (rw,relatime)
/dev/mapper/vg0-data on /data type ext4 (rw,relatime,stripe=128)
//storage/backup on /mnt/pve/storage type cifs (rw,relatime,vers=3.0,cache=strict,username=whatever,uid=0,noforceuid,gid=0,noforcegid,addr=1.2.3.4,file_mode=0755,dir_mode=0755,soft,nounix,serverino,mapposix,rsize=4194304,wsize=4194304,bsize=1048576,echo_interval=60,actimeo=1)
State : clean
Number Major Minor RaidDevice State
0 259 4 0 active sync /dev/nvme1n1p1
1 259 2 1 active sync /dev/nvme0n1p1
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data vg0 Vwi-aotz-- 200.00g pve 2.09
pve vg0 twi-aotz-- 936.50g 15.13 17.90
root vg0 -wi-ao---- 10.00g
swap vg0 -wi-ao---- 6.00g
vm-100-disk-0 vg0 Vwi-aotz-- 20.00g pve 16.03
vm-101-disk-0 vg0 Vwi-aotz-- 25.00g pve 54.40
vm-102-disk-0 vg0 Vwi-aotz-- 25.00g pve 64.62
vm-103-disk-0 vg0 Vwi-aotz-- 40.00g pve 58.75
vm-103-disk-1 vg0 Vwi-aotz-- 50.00g pve 52.68
vm-104-disk-0 vg0 Vwi-aotz-- 32.00g pve 29.85
vm-104-disk-1 vg0 Vwi-aotz-- 50.00g pve 32.25
vm-105-disk-0 vg0 Vwi-aotz-- 10.00g pve 51.22
vm-106-disk-0 vg0 Vwi-aotz-- 20.00g pve 27.94
vm-107-disk-0 vg0 Vwi-aotz-- 8.00g pve 32.04
vm-109-disk-0 vg0 Vwi-aotz-- 8.00g pve 23.00
vm-110-disk-0 vg0 Vwi-aotz-- 32.00g pve 22.27
vm-111-disk-0 vg0 Vwi-aotz-- 32.00g pve 19.02
vm-112-disk-0 vg0 Vwi-a-tz-- 8.00g pve 9.03
# cat /sys/module/kvm_intel/parameters/nested
N
# cat /sys/kernel/mm/ksm/run
0
Last edited:
")


") )
)