Hello,
we have 2 servers running Proxmox 5.2
.
On one of those servers we have 2 VMs that run CloudLinux 7.6 and have cPanel. I noticed today that the CPU usage was higher than expected, both on the VMs and on the Proxmox Host.
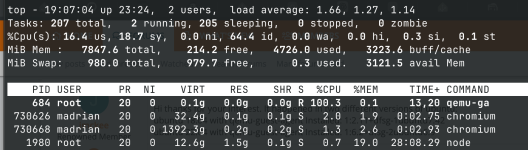
After looking a bit into the VMs it was clear that the usage was caused by the qemu-agent. On both VMs it was on constantly using 100% of CPU. I uninstalled it and after that the load and CPU usage went down, even at the Proxmox host, the screenshots were taken just minutes after uninstalling it.


Is this normal? Did anyone else had this issue?
Thank you very much!
Juan Correa
we have 2 servers running Proxmox 5.2
proxmox-ve: 5.2-2 (running kernel: 4.15.17-1-pve)
pve-manager: 5.2-1 (running version: 5.2-1/0fcd7879)
pve-kernel-4.15: 5.2-1
pve-kernel-4.15.17-1-pve: 4.15.17-9
corosync: 2.4.2-pve5
criu: 2.11.1-1~bpo90
glusterfs-client: 3.8.8-1
ksm-control-daemon: 1.2-2
libjs-extjs: 6.0.1-2
libpve-access-control: 5.0-8
libpve-apiclient-perl: 2.0-4
libpve-common-perl: 5.0-31
libpve-guest-common-perl: 2.0-16
libpve-http-server-perl: 2.0-8
libpve-storage-perl: 5.0-23
libqb0: 1.0.1-1
lvm2: 2.02.168-pve6
lxc-pve: 3.0.0-3
lxcfs: 3.0.0-1
novnc-pve: 0.6-4
proxmox-widget-toolkit: 1.0-18
pve-cluster: 5.0-27
pve-container: 2.0-23
pve-docs: 5.2-3
pve-firewall: 3.0-8
pve-firmware: 2.0-4
pve-ha-manager: 2.0-5
pve-i18n: 1.0-5
pve-libspice-server1: 0.12.8-3
pve-qemu-kvm: 2.11.1-5
pve-xtermjs: 1.0-5
qemu-server: 5.0-26
smartmontools: 6.5+svn4324-1
spiceterm: 3.0-5
vncterm: 1.5-3
zfsutils-linux: 0.7.8-pve1~bpo9
pve-manager: 5.2-1 (running version: 5.2-1/0fcd7879)
pve-kernel-4.15: 5.2-1
pve-kernel-4.15.17-1-pve: 4.15.17-9
corosync: 2.4.2-pve5
criu: 2.11.1-1~bpo90
glusterfs-client: 3.8.8-1
ksm-control-daemon: 1.2-2
libjs-extjs: 6.0.1-2
libpve-access-control: 5.0-8
libpve-apiclient-perl: 2.0-4
libpve-common-perl: 5.0-31
libpve-guest-common-perl: 2.0-16
libpve-http-server-perl: 2.0-8
libpve-storage-perl: 5.0-23
libqb0: 1.0.1-1
lvm2: 2.02.168-pve6
lxc-pve: 3.0.0-3
lxcfs: 3.0.0-1
novnc-pve: 0.6-4
proxmox-widget-toolkit: 1.0-18
pve-cluster: 5.0-27
pve-container: 2.0-23
pve-docs: 5.2-3
pve-firewall: 3.0-8
pve-firmware: 2.0-4
pve-ha-manager: 2.0-5
pve-i18n: 1.0-5
pve-libspice-server1: 0.12.8-3
pve-qemu-kvm: 2.11.1-5
pve-xtermjs: 1.0-5
qemu-server: 5.0-26
smartmontools: 6.5+svn4324-1
spiceterm: 3.0-5
vncterm: 1.5-3
zfsutils-linux: 0.7.8-pve1~bpo9
On one of those servers we have 2 VMs that run CloudLinux 7.6 and have cPanel. I noticed today that the CPU usage was higher than expected, both on the VMs and on the Proxmox Host.
After looking a bit into the VMs it was clear that the usage was caused by the qemu-agent. On both VMs it was on constantly using 100% of CPU. I uninstalled it and after that the load and CPU usage went down, even at the Proxmox host, the screenshots were taken just minutes after uninstalling it.
Is this normal? Did anyone else had this issue?
Thank you very much!
Juan Correa




")