I installed PVE on a hardware encrypted NVME in my Lenovo M720q, with mandos automatic decryption and dropbear as a fallback, mainly using these guides and some stuff I found elsewhere about cryptsetup and OPAL, and that was working fine. It would retrieve the key from the mandos server (on 10.10.55.20) and if that wasn't available, I could SSH in using dropbear and enter the password, or type it in locally.
https://forum.proxmox.com/threads/adding-full-disk-encryption-to-proxmox.137051/
https://blog.boyeau.com/booting-an-...server-ubuntu-server-16-04-setup-with-mandos/
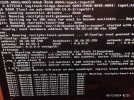
However, when I just tried to boot, it's no longer working. I haven't done any updates recently, and I haven't had time to play with this server in the last couple of weeks so I don't know exactly when it stopped working. As you can see in the attached photo, it's running the process usr/lib/mandos/plugin-runner, the IP address is set to 10.10.55.198 manually in the grub config, and it starts dropbear, but then it gives some I/O errors about nvme0n1 (the only drive) and n1p3 (which is the encrypted root partition), and then it just prints a load of "Running /scripts/local-block...done" before failing and dropping to BusyBox, and it never prompts to enter the password.
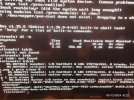
The second photo shows the output from blkid after it's failed to boot. As per the guide, n1p1 is a small EFI partition, around 200MB, n1p2 is the boot partition, around 800MB, and n3 is the encrypted root partition.
I originally installed it on a Crucial self-encrypting SSD before replacing that with the NVME and reinstalling from scratch, so I'll try switching back to the SSD to see if that still works as I haven't wiped it yet, but I can't think of any reason why the NVME should stop working like this.
https://forum.proxmox.com/threads/adding-full-disk-encryption-to-proxmox.137051/
https://blog.boyeau.com/booting-an-...server-ubuntu-server-16-04-setup-with-mandos/
However, when I just tried to boot, it's no longer working. I haven't done any updates recently, and I haven't had time to play with this server in the last couple of weeks so I don't know exactly when it stopped working. As you can see in the attached photo, it's running the process usr/lib/mandos/plugin-runner, the IP address is set to 10.10.55.198 manually in the grub config, and it starts dropbear, but then it gives some I/O errors about nvme0n1 (the only drive) and n1p3 (which is the encrypted root partition), and then it just prints a load of "Running /scripts/local-block...done" before failing and dropping to BusyBox, and it never prompts to enter the password.
The second photo shows the output from blkid after it's failed to boot. As per the guide, n1p1 is a small EFI partition, around 200MB, n1p2 is the boot partition, around 800MB, and n3 is the encrypted root partition.
I originally installed it on a Crucial self-encrypting SSD before replacing that with the NVME and reinstalling from scratch, so I'll try switching back to the SSD to see if that still works as I haven't wiped it yet, but I can't think of any reason why the NVME should stop working like this.

")