pve node status unavailable
- Thread starter benoitc
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

Any detail about your "upgrade"?
Did you check your package version afterwards?
> pveversion -v
it seems the versions have ben correctly installed on that node. I had a quick glance and it looks similar to the other nodes :
Code:
root@pve3:~# pveversion -v
perl: warning: Setting locale failed.
perl: warning: Please check that your locale settings:
LANGUAGE = (unset),
LC_ALL = (unset),
LC_CTYPE = "UTF-8",
LANG = "en_US.UTF-8"
are supported and installed on your system.
perl: warning: Falling back to a fallback locale ("en_US.UTF-8").
proxmox-ve: 6.3-1 (running kernel: 5.4.73-1-pve)
pve-manager: 6.3-2 (running version: 6.3-2/22f57405)
pve-kernel-5.4: 6.3-1
pve-kernel-helper: 6.3-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
pve-kernel-5.4.65-1-pve: 5.4.65-1
pve-kernel-5.4.34-1-pve: 5.4.34-2
ceph: 14.2.15-pve1
ceph-fuse: 14.2.15-pve1
corosync: 3.0.4-pve1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: residual config
ifupdown2: 3.0.0-1+pve3
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.16-pve1
libproxmox-acme-perl: 1.0.5
libproxmox-backup-qemu0: 1.0.2-1
libpve-access-control: 6.1-3
libpve-apiclient-perl: 3.0-3
libpve-common-perl: 6.2-6
libpve-guest-common-perl: 3.1-3
libpve-http-server-perl: 3.0-6
libpve-storage-perl: 6.3-1
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.3-1
lxcfs: 4.0.3-pve3
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.0.5-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.4-3
pve-cluster: 6.2-1
pve-container: 3.3-1
pve-docs: 6.3-1
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-3
pve-firmware: 3.1-3
pve-ha-manager: 3.1-1
pve-i18n: 2.2-2
pve-qemu-kvm: 5.1.0-7
pve-xtermjs: 4.7.0-3
qemu-server: 6.3-1
smartmontools: 7.1-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 0.8.5-pve1So to give more details, once the node restarted the folder /etc/pve was empty. And syslog was returning the following error:
I deleted this folder and restarted pve-cluster which seems to fix the ssl key issue but i still have this status issue. Here are a sample of the logs:
https://www.friendpaste.com/3dhMmLA4J99d2lEmHAMqGA
pveproxy[15720]: /etc/pve/local/pve-ssl.key: failed to load local private key (key_file or key) at /usr/share/perl5/PVE/APIServer/AnyEvent.pm line 1737.I deleted this folder and restarted pve-cluster which seems to fix the ssl key issue but i still have this status issue. Here are a sample of the logs:
https://www.friendpaste.com/3dhMmLA4J99d2lEmHAMqGA
well i just did an apt upgrade. now second node is down. same result /etc/pve empty.Any detail about your "upgrade"?
Did you check your package version afterwards?
> pveversion -v

and following this issue it seems to have attempted to write/read a lot of stuf on SSDs.... I now have the 2 ceph disks wearout to 1%. What does it mean?
The NAND writes and TOTAL_LBAs looks weird. These are brand new disks unused until now.
Bash:
root@pve2:~# smartctl -A /dev/sda
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.73-1-pve] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
9 Power_On_Hours 0x0032 099 099 000 Old_age Always - 1106
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 33
177 Wear_Leveling_Count 0x0013 099 099 005 Pre-fail Always - 1
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0
180 Unused_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 1427
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0
184 End-to-End_Error 0x0033 100 100 097 Pre-fail Always - 0
187 Uncorrectable_Error_Cnt 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0032 063 058 000 Old_age Always - 37
194 Temperature_Celsius 0x0022 063 056 000 Old_age Always - 37 (Min/Max 23/44)
195 ECC_Error_Rate 0x001a 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 0
199 CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
202 Exception_Mode_Status 0x0033 100 100 010 Pre-fail Always - 0
235 POR_Recovery_Count 0x0012 099 099 000 Old_age Always - 22
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 1055935900
242 Total_LBAs_Read 0x0032 099 099 000 Old_age Always - 10306962
243 SATA_Downshift_Ct 0x0032 100 100 000 Old_age Always - 0
244 Thermal_Throttle_St 0x0032 100 100 000 Old_age Always - 0
245 Timed_Workld_Media_Wear 0x0032 100 100 000 Old_age Always - 65535
246 Timed_Workld_RdWr_Ratio 0x0032 100 100 000 Old_age Always - 65535
247 Timed_Workld_Timer 0x0032 100 100 000 Old_age Always - 65535
251 NAND_Writes 0x0032 100 100 000 Old_age Always - 1116867648The NAND writes and TOTAL_LBAs looks weird. These are brand new disks unused until now.
Last edited:
Hi,
there was an issue with systemd unit ordering that has been addressed now, with the
Regarding the version mismatch for the monitors. The reload icon indicates that a new version has been installed, but the monitor was not restarted yet.
I guess the writes happened, because maybe OSDs were down on the second node? So Ceph needed to preserve redundancy.
there was an issue with systemd unit ordering that has been addressed now, with the
ceph 14.2.15-pve2 package now. This caused the pve-cluster.service startup to fail randomly. Please upgrade to the new version and make sure the cluster and ceph services are running correctly.Regarding the version mismatch for the monitors. The reload icon indicates that a new version has been installed, but the monitor was not restarted yet.
I guess the writes happened, because maybe OSDs were down on the second node? So Ceph needed to preserve redundancy.
Hi there,
we have the same problems regarding the web interface. The installed versions are similiar to the ones posted by benoitc.
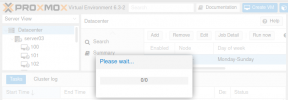
To describe the problem in detail: on the summary page of the virtual machines and the node, the status and metrics are displayed correctly, but in the tree view and on the summary page of the datacenter, there are no infomation available.
The UI seems buggy in further ways, when using the backup functionality, it just freezes and you have to reload (attached screenshot), thus the scheduled backups work just fine. I checked the syslog, but there are no corresponding information written.
Is there a possibility to enable verbose output to provide you with any further information?
we have the same problems regarding the web interface. The installed versions are similiar to the ones posted by benoitc.
To describe the problem in detail: on the summary page of the virtual machines and the node, the status and metrics are displayed correctly, but in the tree view and on the summary page of the datacenter, there are no infomation available.
The UI seems buggy in further ways, when using the backup functionality, it just freezes and you have to reload (attached screenshot), thus the scheduled backups work just fine. I checked the syslog, but there are no corresponding information written.
Is there a possibility to enable verbose output to provide you with any further information?
Attachments
Hi,
are you also running Ceph? What is theHi there,
we have the same problems regarding the web interface. The installed versions are similiar to the ones posted by benoitc.
To describe the problem in detail: on the summary page of the virtual machines and the node, the status and metrics are displayed correctly, but in the tree view and on the summary page of the datacenter, there are no infomation available.
The UI seems buggy in further ways, when using the backup functionality, it just freezes and you have to reload (attached screenshot), thus the scheduled backups work just fine. I checked the syslog, but there are no corresponding information written.
Is there a possibility to enable verbose output to provide you with any further information?
systemctl status pvestatd.service pve-cluster.service? Does clearing the browser cache help?Hi Fabian,
that solved the problem,the UI works fine now. pvestatd.service failed on startup after the reboot. We don't know for sure what caused this problem, but we inserted our local server in the hosts file, because we had problems with some services otherwise because our DNS server is a virtual machine on the same proxmox instance. Maybe this solved the initial problem of pvestatd.service too.
Thanks for your help,
Max
that solved the problem,the UI works fine now. pvestatd.service failed on startup after the reboot. We don't know for sure what caused this problem, but we inserted our local server in the hosts file, because we had problems with some services otherwise because our DNS server is a virtual machine on the same proxmox instance. Maybe this solved the initial problem of pvestatd.service too.
Thanks for your help,
Max
yeah that probably the reason. I am wondering what 1% WEAROUT means though now. Should I contact my hardware supplier to do some exchange, theey were never used until the last 3 weeks... They are supposed to be endurant SSD (Samsung SSD PM883, SATA3, bulk, enterprise medium endurance)Hi,
there was an issue with systemd unit ordering that has been addressed now, with theceph 14.2.15-pve2package now. This caused thepve-cluster.servicestartup to fail randomly. Please upgrade to the new version and make sure the cluster and ceph services are running correctly.
Regarding the version mismatch for the monitors. The reload icon indicates that a new version has been installed, but the monitor was not restarted yet.
I guess the writes happened, because maybe OSDs were down on the second node? So Ceph needed to preserve redundancy.
Last edited:
yeah that probably the reason. I am wondering what 1% WEAROUT means though now. Should I contact my hardware supplier to do some exchange, theey were never used until the last 3 weeks... They are supposed to be endurant SSD (Samsung SSD PM883, SATA3, bulk, enterprise medium endurance)
I'd think they're counting upwards towards 100% and 100% being completely worn out, but of course you should check the disk manual/consult the supplier to make sure that's the case.