Hi,
I am trying to configure correctly the retention policy of my PBS. I want to have the following config:
- to keep the last one
- to have 72h per some of the LXCs which is backed up on hourly basis
- to have 7 days backup of all LXC's even this which is backed up on an hourly basis. The others were taken on a daily basis
When implementing this configuration it was normal after 72h to keep the last archive for the day. For example, after 72h must have only one backup for the next 7 days. On day 14 must stay only the last one which is marked as keep last 1. The last one should be removed manually.
Actually, the prune-simulator shows exactly the same.
The reality is different based on what I see.
All archives which are on a daily basis was marked as hourly archives. This means that the first clean should happen after 72 + 7 archives. This means that the data will be kept for 2.5 months.
Another option that I cannot understand is whether it is possible to configure purging per container or VM. Do I need to configure the clean options from PVE or everything must happen on the PBS side?
Here is an example from the log
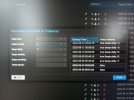
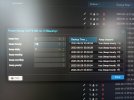
These log is generated from Prun ALL simulation from the PBS datastore section.
The pictures attached show Prun per container what will happen if 72h is present and with no hourly retention value.
Please for some advice on how to make this config useful in my case.
I am trying to configure correctly the retention policy of my PBS. I want to have the following config:
- to keep the last one
- to have 72h per some of the LXCs which is backed up on hourly basis
- to have 7 days backup of all LXC's even this which is backed up on an hourly basis. The others were taken on a daily basis
When implementing this configuration it was normal after 72h to keep the last archive for the day. For example, after 72h must have only one backup for the next 7 days. On day 14 must stay only the last one which is marked as keep last 1. The last one should be removed manually.
Actually, the prune-simulator shows exactly the same.
The reality is different based on what I see.
All archives which are on a daily basis was marked as hourly archives. This means that the first clean should happen after 72 + 7 archives. This means that the data will be kept for 2.5 months.
Another option that I cannot understand is whether it is possible to configure purging per container or VM. Do I need to configure the clean options from PVE or everything must happen on the PBS side?
Here is an example from the log
Code:
2023-06-15T07:18:21+02:00: retention options: --max-depth 0 --keep-last 1 --keep-hourly 72 --keep-daily 7
2023-06-15T07:18:21+02:00: Pruning group :"vm/74109"
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-05-27T02:00:01Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-05-28T02:00:04Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-05-29T02:00:02Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-05-30T02:01:37Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-05-31T02:00:33Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-01T02:00:28Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-02T02:00:59Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-03T02:53:59Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-04T02:51:41Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-05T02:52:32Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-06T02:51:24Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-07T02:53:09Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-08T02:48:42Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-09T02:49:15Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-10T02:52:29Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-11T02:50:05Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-12T02:52:15Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-13T02:49:20Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-14T02:50:27Z
2023-06-15T07:18:21+02:00: would keep vm/74109/2023-06-15T02:50:40Z
2023-06-15T07:18:21+02:00: TASK OKThese log is generated from Prun ALL simulation from the PBS datastore section.
The pictures attached show Prun per container what will happen if 72h is present and with no hourly retention value.
Please for some advice on how to make this config useful in my case.
")
