Proxmox VE Ceph Benchmark 2023/12 - Fast SSDs and network speeds in a Proxmox VE Ceph Reef cluster
- Thread starter martin
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Here are some benchmarks for 100G LACP on a cluster with 7 nodes, 6 (Kioxia DC NVMe) OSDs per node, same bench as the one in the article. Sapphire Rapids Xeon Gold with 1TB of RAM per node, no load (VMs) on any node.
Avg. bandwidth:
write 7239.68 MB/s
rand 7539.36 MB/s
No matter what I do, I can't seem to get much past the 7.5GB/s writes with a single client. If I launch 3 clients, I can get to ~3x4GB/s or filling a single of the dual 100Gbps link. I need to launch all 7 at the same time to get a minimum of ~2GB/s and an average of ~3GB/s on each client (168Gbps across the cluster) and I'm assuming at that point I'm hitting a hard limit on my OSDs as my average IOPS dropped from ~2000 to ~1000 IOPS with 4M writes, benchmarks with 3 nodes maintain 2000 IOPS @ 4M, same as a single node.
For reads, I can get to 4-6GB/s on all nodes simultaneously, I'm assuming that this is because reads from blocks on the node running the bench itself are going to be really fast (1/3 of the reads if you're lucky). I do have 2 separate network switches as well with the backplanes connected over 400Gbps, so again, if you're lucky and you hit the "best" path you can get to ~300Gbps over the 7 nodes. There is lots of variability in that data so that bench is probably not very useful. In most cases, write is what really matters as reads are for most applications significantly cached in memory.
CPU usage never went above 15% (48 cores) although I do notice that for some reason neither the Proxmox nor my Prometheus has data on the 100G network interfaces.
I believe that with the right hardware (more OSD) you can probably fill more than 400G with Ceph with just a few nodes.
Avg. bandwidth:
write 7239.68 MB/s
rand 7539.36 MB/s
No matter what I do, I can't seem to get much past the 7.5GB/s writes with a single client. If I launch 3 clients, I can get to ~3x4GB/s or filling a single of the dual 100Gbps link. I need to launch all 7 at the same time to get a minimum of ~2GB/s and an average of ~3GB/s on each client (168Gbps across the cluster) and I'm assuming at that point I'm hitting a hard limit on my OSDs as my average IOPS dropped from ~2000 to ~1000 IOPS with 4M writes, benchmarks with 3 nodes maintain 2000 IOPS @ 4M, same as a single node.
For reads, I can get to 4-6GB/s on all nodes simultaneously, I'm assuming that this is because reads from blocks on the node running the bench itself are going to be really fast (1/3 of the reads if you're lucky). I do have 2 separate network switches as well with the backplanes connected over 400Gbps, so again, if you're lucky and you hit the "best" path you can get to ~300Gbps over the 7 nodes. There is lots of variability in that data so that bench is probably not very useful. In most cases, write is what really matters as reads are for most applications significantly cached in memory.
CPU usage never went above 15% (48 cores) although I do notice that for some reason neither the Proxmox nor my Prometheus has data on the 100G network interfaces.
I believe that with the right hardware (more OSD) you can probably fill more than 400G with Ceph with just a few nodes.
Last edited:

Hope someone can clarify this for me.
Proxmox 8.1.5 Ceph Reef 18.2.1 cluster, with 4 Dell r630 hosts, 6 ssd drives each, Ceph network with dual 10Ge connectivity.
With rados bench I get what is expected: wirespeed performance for single host test:
rados bench -p ceph01 120 write -b 4M -t 16 --run-name `hostname` --no-cleanup
Total time run: 120.032
Total writes made: 35159
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1171.65
Stddev Bandwidth: 54.414
Max bandwidth (MB/sec): 1268
Min bandwidth (MB/sec): 1004
Average IOPS: 292
Stddev IOPS: 13.6035
Max IOPS: 317
Min IOPS: 251
Average Latency(s): 0.0546073
Stddev Latency(s): 0.019493
Max latency(s): 0.301827
Min latency(s): 0.0217319
rados bench -p ceph01 600 seq -t 16 --run-name `hostname`
Total time run: 88.336
Total reads made: 35159
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1592.06
Average IOPS: 398
Stddev IOPS: 28.5776
Max IOPS: 458
Min IOPS: 325
Average Latency(s): 0.0389745
Max latency(s): 0.450536
Min latency(s): 0.0121847
I think 1171MB/s write, 1592MB/s read is excellent, no complaints whatsoever!
The odd thing is, if I do a performance test on a VM that has it's disk on the Ceph pool on the cluster. I get the following results with fio tests:
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=15 --direct=1 --sync=1 --rw=write --bs=4M --numjobs=1 --iodepth=1
WRITE: bw=129MiB/s (135MB/s), 129MiB/s-129MiB/s (135MB/s-135MB/s), io=75.5GiB (81.1GB), run=600017-600017msec
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=600 --direct=1 --sync=1 --rw=read --bs=4M --numjobs=1 --iodepth=1
READ: bw=368MiB/s (386MB/s), 368MiB/s-368MiB/s (386MB/s-386MB/s), io=216GiB (232GB), run=600009-600009msec
Using bigger block size of 16M gives better results.
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=30 --direct=1 --sync=1 --rw=write --bs=16M --numjobs=1 --iodepth=1
WRITE: bw=317MiB/s (332MB/s), 317MiB/s-317MiB/s (332MB/s-332MB/s), io=9504MiB (9966MB), run=30002-30002msec
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=30 --direct=1 --sync=1 --rw=read --bs=16M --numjobs=1 --iodepth=1
READ: bw=845MiB/s (886MB/s), 845MiB/s-845MiB/s (886MB/s-886MB/s), io=24.8GiB (26.6GB), run=30005-30005msec
So. Good read performance especially with bigger block sizes, but why is the write performance so slow, if the underlying Ceph can easily do over 1000MB/s?
Test VM config:
agent: 1
boot: order=scsi0;ide2;net0
cores: 4
ide2: none,media=cdrom
memory: 2048
name: testvm
net0: virtio=B6:6B:4E:CA:91:16,bridge=vmbr1
numa: 0
onboot: 1
ostype: l26
scsi0: ceph01:vm-501-disk-0,iothread=1,size=32G
scsi1: ceph01:vm-501-disk-1,iothread=1,size=160G
scsihw: virtio-scsi-single
smbios1: uuid=807fc9e6-7b1d-4af1-a2c1-882b4a0c43b9
sockets: 1
tags:
vmgenid: 0f5e7ed6-e735-4f5b-9b80-8c2a71710a52
Proxmox 8.1.5 Ceph Reef 18.2.1 cluster, with 4 Dell r630 hosts, 6 ssd drives each, Ceph network with dual 10Ge connectivity.
With rados bench I get what is expected: wirespeed performance for single host test:
rados bench -p ceph01 120 write -b 4M -t 16 --run-name `hostname` --no-cleanup
Total time run: 120.032
Total writes made: 35159
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1171.65
Stddev Bandwidth: 54.414
Max bandwidth (MB/sec): 1268
Min bandwidth (MB/sec): 1004
Average IOPS: 292
Stddev IOPS: 13.6035
Max IOPS: 317
Min IOPS: 251
Average Latency(s): 0.0546073
Stddev Latency(s): 0.019493
Max latency(s): 0.301827
Min latency(s): 0.0217319
rados bench -p ceph01 600 seq -t 16 --run-name `hostname`
Total time run: 88.336
Total reads made: 35159
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1592.06
Average IOPS: 398
Stddev IOPS: 28.5776
Max IOPS: 458
Min IOPS: 325
Average Latency(s): 0.0389745
Max latency(s): 0.450536
Min latency(s): 0.0121847
I think 1171MB/s write, 1592MB/s read is excellent, no complaints whatsoever!
The odd thing is, if I do a performance test on a VM that has it's disk on the Ceph pool on the cluster. I get the following results with fio tests:
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=15 --direct=1 --sync=1 --rw=write --bs=4M --numjobs=1 --iodepth=1
WRITE: bw=129MiB/s (135MB/s), 129MiB/s-129MiB/s (135MB/s-135MB/s), io=75.5GiB (81.1GB), run=600017-600017msec
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=600 --direct=1 --sync=1 --rw=read --bs=4M --numjobs=1 --iodepth=1
READ: bw=368MiB/s (386MB/s), 368MiB/s-368MiB/s (386MB/s-386MB/s), io=216GiB (232GB), run=600009-600009msec
Using bigger block size of 16M gives better results.
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=30 --direct=1 --sync=1 --rw=write --bs=16M --numjobs=1 --iodepth=1
WRITE: bw=317MiB/s (332MB/s), 317MiB/s-317MiB/s (332MB/s-332MB/s), io=9504MiB (9966MB), run=30002-30002msec
fio --ioengine=psync --filename=/var/tmp/test_fio --size=5G --time_based --name=fio --group_reporting --runtime=30 --direct=1 --sync=1 --rw=read --bs=16M --numjobs=1 --iodepth=1
READ: bw=845MiB/s (886MB/s), 845MiB/s-845MiB/s (886MB/s-886MB/s), io=24.8GiB (26.6GB), run=30005-30005msec
So. Good read performance especially with bigger block sizes, but why is the write performance so slow, if the underlying Ceph can easily do over 1000MB/s?
Test VM config:
agent: 1
boot: order=scsi0;ide2;net0
cores: 4
ide2: none,media=cdrom
memory: 2048
name: testvm
net0: virtio=B6:6B:4E:CA:91:16,bridge=vmbr1
numa: 0
onboot: 1
ostype: l26
scsi0: ceph01:vm-501-disk-0,iothread=1,size=32G
scsi1: ceph01:vm-501-disk-1,iothread=1,size=160G
scsihw: virtio-scsi-single
smbios1: uuid=807fc9e6-7b1d-4af1-a2c1-882b4a0c43b9
sockets: 1
tags:
vmgenid: 0f5e7ed6-e735-4f5b-9b80-8c2a71710a52
Last edited:
Another question, seeing that enterprise nvmes do not saturate a 100Gbe network. Is there any benefit using separate networks for the Ceph
public and cluster networks or is safe to use all ceph traffic in one 100Gbe network? (I´m talking 3 node cluster with minimun 4OSD per node)
public and cluster networks or is safe to use all ceph traffic in one 100Gbe network? (I´m talking 3 node cluster with minimun 4OSD per node)
Last edited:
Yes I think so.Another question, seeing that enterprise nvmes do not saturate a 100Gbe network. Is there any benefit using separate networks for the Ceph
public and cluster networks or is safe to use all ceph traffic in one 100Gbe network? (I´m talking 3 node cluster with minimun 4OSD per node)
I also think that 100G network seem overkill.
I've never done Ceph before but my setup will look like this:
Code:
8x node
2x 3.2 TB nvme per server (will add more as I need it)
Dual 25G NIC connected to vCP switch setup, bonded with LACP for redundancy and also speed. I will have 50G usable.public traffic, ceph traffic will run via the same NIC, but importantly isolated with their own vlan. It should be just as safe.
___
Does a benchmark exist for different EC levels? E.g EC 2 + 1, 3 + 2, 4 + 2
I'm assuming above benchmark was made using standard Replication.
Last edited:
I'd think it should be safe with 100G network based on my personal experience. My cluster average of 10~15Gbps read traffic from 48 OSD on 12 NVMe across 5 nodes.Another question, seeing that enterprise nvmes do not saturate a 100Gbe network. Is there any benefit using separate networks for the Ceph
public and cluster networks or is safe to use all ceph traffic in one 100Gbe network? (I´m talking 3 node cluster with minimun 4OSD per node)
Ultimately, iit depends on your usage. Most of the VMs in my cluster are not highly active but when busy, my 25G Ceph private network can be saturated. So if you expect very busy I/O, 12NVMe in theory could give 60 to 80 Gbps of traffic.
If you bond two 25G in LACP you get 50G worth of bandwidth and also redundancy.So if you expect very busy I/O, 12NVMe in theory could give 60 to 80 Gbps of traffic.
I feel like 50G is more than enough, that's like 5 GB/s throughput, not sure how many iops but that's per node. Across the entire cluster it's going to be way more
The Ceph network is on a pair of 25G LACP bond. However, I don't recall ever seeing transfers go above 25G. It might be the way my network guys set things up or we're doing something wrongIf you bond two 25G in LACP you get 50G worth of bandwidth and also redundancy.
I feel like 50G is more than enough, that's like 5 GB/s throughput, not sure how many iops but that's per node. Across the entire cluster it's going to be way more

With some asterisks/footnotes ;-)If you bond two 25G in LACP you get 50G worth of bandwidth and also redundancy.
In total yes, though not for a single connection. The higher the LACP hash policy is configured (and supported by the switches) the more finely grained the load balancing over the physical connections will be.
From source / dest MAC as the only deciding factor in the lowest variant, to src/dst IP + Port in the highest hash policy.
In regards the need for 100G, depends on your application. In most cases I'm not even hitting 20G, so 10G is too low for my application. There are some databases that use the low latency and throughput but that is rare.
Can you mix Ceph and other things: Yes, I do the same, I have multiple networks (VLAN) configured on Proxmox, I have a VLAN for Ceph and then with the help of the Proxmox GUI I have multiple VLAN networks for "applications" and then the L3 switch can do a latency priority based on VLAN as well. Again, depends on your workload, is it critical to hit a certain target, how large is your cluster etc, can your application and customer accept potentially variable speeds. You should also have the Proxmox cluster (heartbeat etc) also on a network that isn't too loud/busy. Oh, and test that things like LACP work properly:
Intel® Ethernet 700 Series Network Adapters - Special Considerations Each Intel® Ethernet 700 Series Network Adapter has a built-in hardware LLDP engine, which is enabled by default. The LLDP Engine is responsible for receiving and consuming LLDP frames, and also replies to the LLDP frames that it receives. The LLDP engine does not forward LLDP frames to the network stack of the Operating System. LACP may not function correctly in certain environments that require LLDP frames containing LCAP information to be forwarded to the network stack. To avoid this situation, the user must disable the Intel® Ethernet 700 Series Network Adapter's hardware LLDP engine.
ethtool -set-priv-flags disable-fw-lldp on
@jtanio: The reason for the fio bench is that you're using a queue depth and job number of 1, modern SSD use depths of 256 or 1024, but you're still bottlenecked by the latency from the "command being sent" through the CPU, through the networking layer, to the SSD and back. Even raw file access will be relatively slow with that benchmark. So if you're sending 1 command on 1 core at a time, it will be (relatively) slow. Use deeper queues and more cores representative of your actual workload.
Can you mix Ceph and other things: Yes, I do the same, I have multiple networks (VLAN) configured on Proxmox, I have a VLAN for Ceph and then with the help of the Proxmox GUI I have multiple VLAN networks for "applications" and then the L3 switch can do a latency priority based on VLAN as well. Again, depends on your workload, is it critical to hit a certain target, how large is your cluster etc, can your application and customer accept potentially variable speeds. You should also have the Proxmox cluster (heartbeat etc) also on a network that isn't too loud/busy. Oh, and test that things like LACP work properly:
Intel® Ethernet 700 Series Network Adapters - Special Considerations Each Intel® Ethernet 700 Series Network Adapter has a built-in hardware LLDP engine, which is enabled by default. The LLDP Engine is responsible for receiving and consuming LLDP frames, and also replies to the LLDP frames that it receives. The LLDP engine does not forward LLDP frames to the network stack of the Operating System. LACP may not function correctly in certain environments that require LLDP frames containing LCAP information to be forwarded to the network stack. To avoid this situation, the user must disable the Intel® Ethernet 700 Series Network Adapter's hardware LLDP engine.
ethtool -set-priv-flags disable-fw-lldp on
@jtanio: The reason for the fio bench is that you're using a queue depth and job number of 1, modern SSD use depths of 256 or 1024, but you're still bottlenecked by the latency from the "command being sent" through the CPU, through the networking layer, to the SSD and back. Even raw file access will be relatively slow with that benchmark. So if you're sending 1 command on 1 core at a time, it will be (relatively) slow. Use deeper queues and more cores representative of your actual workload.
I am setting up a new cluster with Ceph and plan to use two Cisco Nexus 3132q-x switches in a configuration similar to switch stacking, but in the case of Cisco Nexus, it is called "vPC".
Each switch has 32 physical QSFP ports of 40Gbps that can be configured as Breakout, allowing each port to connect with a special cable into 4 SFP+ ports of 10Gbps. In other words, each 40Gbps port on the switch functions as 4 SFP+ ports of 10Gbps.
Initially, I will connect 12 hyper-converged servers with two 10Gbps SFP+ ports in each server. Each server also has 4 Gigabit Ethernet ports that will be used for other purposes in the cluster.
There will also be 1 RBD client server with four 40Gbps QSFP ports and 2 10Gbps SFP+ ports, plus the 4 Gigabit Ethernet ports. This server will use two of these faster ports to be a Ceph client.
How should I configure the ports through which the OSDs will communicate, given that each node today has 2 10Gbps ports?
Let's see: The SFP+ ports of each server should be connected in an LAG LACP to the vPC (the stack of switches), with each 10Gbps physical port of each server connected to a different switch in the stack to ensure path redundancy, generating greater data availability.
From what I understand so far, configuring the Cisco Nexus switch port as "cut-through" makes it work with lower latency. However, this configuration also reduces the number of available ports on the switch. Each switch, which has 32 physical ports, becomes available with only 24 of these ports.
On the other hand, working with the switch ports configured as "oversubscribed" slightly increases the latency of each port (I don't know the exact numbers), but allows the use of all 32 available ports on each switch (which is better for scalability).
Detail: I plan to use 6 physical ports of each switch for an LAG that will provide data communication between the switches to form the "vPC" stack.
Does anyone have experience with this? How can I best balance this?
Should I use the switch ports configured as "oversubscribed" with all 32 ports available with slightly higher latency or as "cut-through" with lower latency but only 24 ports available?
Thank you.
Each switch has 32 physical QSFP ports of 40Gbps that can be configured as Breakout, allowing each port to connect with a special cable into 4 SFP+ ports of 10Gbps. In other words, each 40Gbps port on the switch functions as 4 SFP+ ports of 10Gbps.
Initially, I will connect 12 hyper-converged servers with two 10Gbps SFP+ ports in each server. Each server also has 4 Gigabit Ethernet ports that will be used for other purposes in the cluster.
There will also be 1 RBD client server with four 40Gbps QSFP ports and 2 10Gbps SFP+ ports, plus the 4 Gigabit Ethernet ports. This server will use two of these faster ports to be a Ceph client.
How should I configure the ports through which the OSDs will communicate, given that each node today has 2 10Gbps ports?
Let's see: The SFP+ ports of each server should be connected in an LAG LACP to the vPC (the stack of switches), with each 10Gbps physical port of each server connected to a different switch in the stack to ensure path redundancy, generating greater data availability.
From what I understand so far, configuring the Cisco Nexus switch port as "cut-through" makes it work with lower latency. However, this configuration also reduces the number of available ports on the switch. Each switch, which has 32 physical ports, becomes available with only 24 of these ports.
On the other hand, working with the switch ports configured as "oversubscribed" slightly increases the latency of each port (I don't know the exact numbers), but allows the use of all 32 available ports on each switch (which is better for scalability).
Detail: I plan to use 6 physical ports of each switch for an LAG that will provide data communication between the switches to form the "vPC" stack.
Does anyone have experience with this? How can I best balance this?
Should I use the switch ports configured as "oversubscribed" with all 32 ports available with slightly higher latency or as "cut-through" with lower latency but only 24 ports available?
Thank you.
@adriano_da_silva the oversubscription option allows you to basically overcommit the available bandwidth and switching capacity.
In a pure Ceph workload, you would unlikely notice the extra microseconds in latency under normal load. Off course if you are going to load this to the edge and consume all the bandwidth at once (eg during a rebuild) you may start to run out of bandwidth.
Did you calculate in your 2-4 stacking ports? (if I’m not mistaken, the Nexus requires you to use ports to stack). I also don’t know if that model has the processing power to also handle LACP and VLAN once you start splitting out to many ports.
In a pure Ceph workload, you would unlikely notice the extra microseconds in latency under normal load. Off course if you are going to load this to the edge and consume all the bandwidth at once (eg during a rebuild) you may start to run out of bandwidth.
Did you calculate in your 2-4 stacking ports? (if I’m not mistaken, the Nexus requires you to use ports to stack). I also don’t know if that model has the processing power to also handle LACP and VLAN once you start splitting out to many ports.
"Detail: I plan to use 6 physical ports of each switch for an LAG that will provide data communication between the switches to form the 'vPC' stack." -- At this point, I mean that I will use 6 ports for stacking (vPC). I don't know exactly how to calculate how many ports would be needed for communication between the stacked switches, but I figured that 6 ports (240Gbps) would be enough, since 12 servers with 2 10Gbps ports each would consume at most that bandwidth. So I made this choice. The above-mentioned RBD clients will use the Ceph Pools to store the virtual disks of the VMs. These include boot virtual disks with various operating systems, as well as virtual disks with file servers or databases such as PostgreSQL, Oracle, Microsoft SQL Server, and InterSystems IRIS.@adriano_da_silva the oversubscription option allows you to basically overcommit the available bandwidth and switching capacity.
In a pure Ceph workload, you would unlikely notice the extra microseconds in latency under normal load. Off course if you are going to load this to the edge and consume all the bandwidth at once (eg during a rebuild) you may start to run out of bandwidth.
Did you calculate in your 2-4 stacking ports? (if I’m not mistaken, the Nexus requires you to use ports to stack). I also don’t know if that model has the processing power to also handle LACP and VLAN once you start splitting out to many ports.
Hi Have similar setup with 3 node MESH Configuration.
AMD EPYC 7543P 32-Core Processor 512GB ram
I have only 2 X 7TB 7450 PRO MTFDKCB7T6TFR per node for now. I did the FRR setup on 100Gbps test with Iperf goes about 96Gbps.
NVME goes about with
fio --ioengine=libaio --filename=/dev/nvme1n1 --direct=1 --sync=1 --rw=write --bs=4M --numjobs=1 --iodepth=1 --runtime=60 --time_based --name=fio

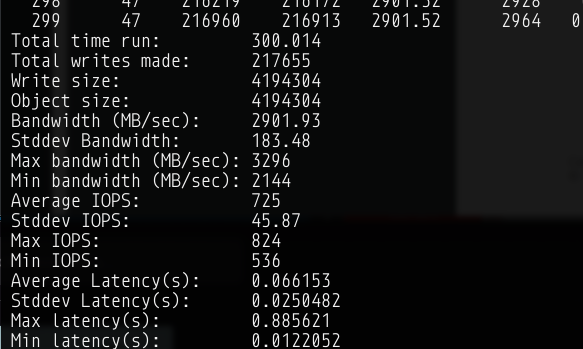
When I run rados bench from 3 nodes I get max 11 12 GBb/s on cluster read
This the rados bench Read
Is this good score ?
I was expecting read in Rados single instance would be little better at least like NVME 5000-6000 MB/s ?
AMD EPYC 7543P 32-Core Processor 512GB ram
I have only 2 X 7TB 7450 PRO MTFDKCB7T6TFR per node for now. I did the FRR setup on 100Gbps test with Iperf goes about 96Gbps.
NVME goes about with
fio --ioengine=libaio --filename=/dev/nvme1n1 --direct=1 --sync=1 --rw=write --bs=4M --numjobs=1 --iodepth=1 --runtime=60 --time_based --name=fio
When I run rados bench from 3 nodes I get max 11 12 GBb/s on cluster read
This the rados bench Read
Is this good score ?
I was expecting read in Rados single instance would be little better at least like NVME 5000-6000 MB/s ?
Can you post your system your configuration and what command you have used? It looks OK, but If your unsure check 'ceph osd perf' while benchmarking to see if one of your nvme is peforming bad. Ceph tell is also useful to see if one nvme is not working as the others regarding performance. But I guess your fine.Hi Have similar setup with 3 node MESH Configuration.
AMD EPYC 7543P 32-Core Processor 512GB ram
I have only 2 X 7TB 7450 PRO MTFDKCB7T6TFR per node for now. I did the FRR setup on 100Gbps test with Iperf goes about 96Gbps.
NVME goes about with
fio --ioengine=libaio --filename=/dev/nvme1n1 --direct=1 --sync=1 --rw=write --bs=4M --numjobs=1 --iodepth=1 --runtime=60 --time_based --name=fio
View attachment 77464
When I run rados bench from 3 nodes I get max 11 12 GBb/s on cluster read
This the rados bench Read
Is this good score ?
I was expecting read in Rados single instance would be little better at least like NVME 5000-6000 MB/s ?
Last edited:
@tane: Ceph bench simulates multiple clients at once, your bandwidth is 100Gbps and you get ~96Gbps (12*8) throughput, that seems to be acceptable. If you have the capacity to do 2x100G per server, you may be able to get better results. Note that Ceph is distributing each write to 3 nodes.
Last edited:
Sorry it's a Mesh config I have Dual 2x100G but no switch. Which is ok for me. I have also 6x10Gb/s (Also no switch for this) maybe move ceph public network there but I think It would be probably slower ? What do you think ?@tane: Ceph bench simulates multiple clients at once, your bandwidth is 100Gbps and you get ~96Gbps (12*8) throughput, that seems to be acceptable. If you have the capacity to do 2x100G per server, you may be able to get better results.
Currently setting up 5 nodes ceph with the following spec (only serving as storage node)
chassis & motherboard: AS -1114S-WN10RT H12SSW-NTR, CSE-116TS-R706WBP5-N10,RoHS
cpu: single Milan X 7773X DP/UP 64C/128T 2.2G 768M 280W SP3 3D V-cache
ram: 32GB DDR4-3200 2RX4 LP ECC RDIMM x 32 (384GB)
os drives: Micron 7450 PRO 480GB NVMe PCIe 4.0 M.2 22x80mm 3D TLC x 2 (ZFS mirror)
osd drives: Samsung PM9A3 3.8TB NVMe PCIe4x4 U.2 7mm 1DWPD 5YR SED Opal x 10
network: AOC-S100G-B2C-O dual port 100G x 1
switch 2 x Dell Z9100-ON with VLT
chassis & motherboard: AS -1114S-WN10RT H12SSW-NTR, CSE-116TS-R706WBP5-N10,RoHS
cpu: single Milan X 7773X DP/UP 64C/128T 2.2G 768M 280W SP3 3D V-cache
ram: 32GB DDR4-3200 2RX4 LP ECC RDIMM x 32 (384GB)
os drives: Micron 7450 PRO 480GB NVMe PCIe 4.0 M.2 22x80mm 3D TLC x 2 (ZFS mirror)
osd drives: Samsung PM9A3 3.8TB NVMe PCIe4x4 U.2 7mm 1DWPD 5YR SED Opal x 10
network: AOC-S100G-B2C-O dual port 100G x 1
switch 2 x Dell Z9100-ON with VLT
Hello guys, any command you would like me to generate some numbers before putting this with data?