Good morning everyone, I would like to submit an event that happened to a customer I follow and for whom I maintain a Proxmox Cluster.
The server cluster (3 nodes) is located on a public provider (OVH) that offers the 3 identical physical machines (dedicated servers). All nodes have an active Enterprise Community licence and are updated to the latest version 7.1-8.
The first node is the "master" of the cluster and the other two nodes are the "slaves", the servers have been joined together in a Cluster because inside they run different VMs and LXCs that communicate with each other using internal VLANs (also offered by OVH) and some of these have also configured replication between different nodes.
At the HW level all servers have a RAID1 ZFS as a 250GB boot disk on a SATA SSD and a second RAID1 ZFS with a 1TB NVME disk for data. All VMs and LCX are on the NVME disk and backups are done at a different location offered by OVH using an internal network over SMB.
Last week I noticed that some replication jobs were failing and when I connected to the management interface there were synchronization errors. Since it had already happened in the past that by carrying out system updates and a reboot of the nodes everything was working again I preceded this.
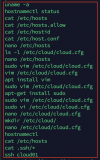
Unfortunately, nodes 2-3 came online and node1 remained offline (can access only by SSH), after a careful analysis I realize that, in the history of bash I find these commands attached image. Basically someone has changed the hostname of node1 with the consequent deletion of the directory /etc/pve, maybe caused by the server restart that with a different hostname has tried to reconfigure itself.
I analyzed all the system logs and there are no SSH violations on all 3 nodes and as a precaution I changed the passwords of all the servers.
Now my questions are two:
1. How did they run those commands if I can't find any kind of ssh access? Is there any bug/vulnerability in the Proxmox GUI? (Maybe fixed with version 7.1-10 released today?)
2. Now I'm stuck with node1 which I tried reconfiguring by hand taking the pve folder from node2 and editing the various links to the correct node1 configurations. I've also tried upgrading to the no-subscription version but it keeps giving me an error on installing pve-manager.
Do you think I can get it working again somehow? If needed I could share more information from the service error logs.
Or is it better to redo node1 and reinstall it from scratch? In this case, how would node2 and node3 behave if I went to "pvecm delnode node1"? Would it self-promote node2 to master within the cluster quorum? Can I then subsequently re-add the node1, re-prepared from scratch, and promote it as master again? (I have already removed nodes from clusters in the past, but they were secondary and I had no problems).
I remain available for any clarifications or other to understand how to solve the problem of node1 but especially to secure this and all other Proxmox Servers I manager, and be sure that cannot be a vulnerability of Proxmox GUI.
Max Colombo
The server cluster (3 nodes) is located on a public provider (OVH) that offers the 3 identical physical machines (dedicated servers). All nodes have an active Enterprise Community licence and are updated to the latest version 7.1-8.
The first node is the "master" of the cluster and the other two nodes are the "slaves", the servers have been joined together in a Cluster because inside they run different VMs and LXCs that communicate with each other using internal VLANs (also offered by OVH) and some of these have also configured replication between different nodes.
At the HW level all servers have a RAID1 ZFS as a 250GB boot disk on a SATA SSD and a second RAID1 ZFS with a 1TB NVME disk for data. All VMs and LCX are on the NVME disk and backups are done at a different location offered by OVH using an internal network over SMB.
Last week I noticed that some replication jobs were failing and when I connected to the management interface there were synchronization errors. Since it had already happened in the past that by carrying out system updates and a reboot of the nodes everything was working again I preceded this.
Unfortunately, nodes 2-3 came online and node1 remained offline (can access only by SSH), after a careful analysis I realize that, in the history of bash I find these commands attached image. Basically someone has changed the hostname of node1 with the consequent deletion of the directory /etc/pve, maybe caused by the server restart that with a different hostname has tried to reconfigure itself.
I analyzed all the system logs and there are no SSH violations on all 3 nodes and as a precaution I changed the passwords of all the servers.
Now my questions are two:
1. How did they run those commands if I can't find any kind of ssh access? Is there any bug/vulnerability in the Proxmox GUI? (Maybe fixed with version 7.1-10 released today?)
2. Now I'm stuck with node1 which I tried reconfiguring by hand taking the pve folder from node2 and editing the various links to the correct node1 configurations. I've also tried upgrading to the no-subscription version but it keeps giving me an error on installing pve-manager.
Do you think I can get it working again somehow? If needed I could share more information from the service error logs.
Or is it better to redo node1 and reinstall it from scratch? In this case, how would node2 and node3 behave if I went to "pvecm delnode node1"? Would it self-promote node2 to master within the cluster quorum? Can I then subsequently re-add the node1, re-prepared from scratch, and promote it as master again? (I have already removed nodes from clusters in the past, but they were secondary and I had no problems).
I remain available for any clarifications or other to understand how to solve the problem of node1 but especially to secure this and all other Proxmox Servers I manager, and be sure that cannot be a vulnerability of Proxmox GUI.
Max Colombo