Well the case is still warm.
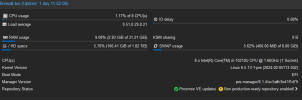
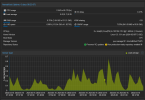
Did more testing. And now im not sure if its hardware issue. Device was unplugged from power and network for 2 days. Yesterdays started doing stress tests using s-tui. no crash. Did iperf3 on all NIC ports. no crash. Left device idling with containers running overnight. 11h no crash.
Not sure what to do now. Anyone got any ideas?
I still havent plugged it to my network, because it was DDOSSING my network when it was having seizure. Ill try to use it over the weekend in production mode, to see if maybe network traffic crashes it. Other than that i dont know what else to do.
Did more testing. And now im not sure if its hardware issue. Device was unplugged from power and network for 2 days. Yesterdays started doing stress tests using s-tui. no crash. Did iperf3 on all NIC ports. no crash. Left device idling with containers running overnight. 11h no crash.
Not sure what to do now. Anyone got any ideas?
I still havent plugged it to my network, because it was DDOSSING my network when it was having seizure. Ill try to use it over the weekend in production mode, to see if maybe network traffic crashes it. Other than that i dont know what else to do.




")