Hi Proxmox community, I've encountered a strange issue with my server where the entire node crashes during the restoration of VM backups. This issue has occurred under specific circumstances and I need some advice on troubleshooting and prevention strategies. I'll write out the full story, and then a TL;DR after.
A few weeks ago, I decided to set up 2 virtual machines for hosting an LLM. One would have very limited resources and is just for simply hosting a web UI, and the other is a VM with a lot of resources including a GPU to run the LLMs and host an API.
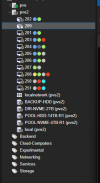
Anyway, what happened is that a few weeks ago when I first made my AI setup, I was messing around with my API VM and wanted to do some config tweaks. Before doing anything of course, I shut down the VM and made a backup. I then proceeded to start up the VM and make my changes, and wouldn't you know, it broke my API config inside the VM. So then I went to restore the backup, and as soon as I hit restore, my entire node said connection lost and all of the VMs, CTs, and storage statuses turned from green checks to grey question marks.
From then, I was able to ping the server from another machine, but that is about it. I couldn't SSH into it because that would just hang, and I couldn't even access any other VMs that were on at the time or their services. I then had someone on site (the server isn't in my house) attempt to shut it down properly by hitting the power button once and then waiting, but that didn't do anything and the server had to be force reset. After that it would go back online and everything would be fine. After that, I deleted the 2 VMs, and everything was fine.
The second time this happened (yesterday), I decided I would play around with AI again, and make a more permanent solution that I can host and keep on 24/7. I created a VM with the API, and a Debian container to host the web UI. I gave my API VM about 70GB ram (out of a total of 128) + 12 vCPUs, and passed through a 3080 Ti. I went through the setup process, which involved some trial and error, so I had to backup and restore the VM a few times, which yielded no issues.
After that, I went to set up a Debian container for my web UI. I then set up the container, installed the web UI, and backed the container up before setting up an account or making any config tweaks. After a while, I decided that I wanted to tweak my initial setup a bit by adding another mount point to store uploaded media for organization purposes. So I shut down the container, went to my backup, pressed restore, and the exact same issue happened again. I had to get someone on site to force restart the machine to bring it back online the very next day.
TL;DR:
I have a server setup specifically for hosting AI services with two VMs: one for a web UI and another resource-intensive VM for running LLMs with a GPU. The problem arises when I attempt to restore backups. On two separate occasions, restoring backups caused my node to crash, losing connectivity and requiring a hard reboot to resolve.
Here is a short event log:
Here is a log snippet from when it happened yesterday after I started a restore job of my web UI container (209):
```
May 04 23:14:54 pve2 postfix/smtp[880938]: 5F620324BF: to=<admin@mydomain.com>, relay=mail.mydomain.com[my ip]:25, delay=0.02, delays=0/0/0.02/0, dsn=4.1.8, status=deferred (host mail.mydomain.com[96.244.139.2] said: 450 4.1.8 <root@pve2.mydomain.com>: Sender address rejected: Domain not found (in reply to RCPT TO command))
May 04 23:15:57 pve2 pvedaemon[875774]: <root@pam> starting task UPID ve2:000D72B7:01BE844C:6636F9ED:vzrestore:209:root@pam:
ve2:000D72B7:01BE844C:6636F9ED:vzrestore:209:root@pam:
May 04 23:15:57 pve2 kernel: loop0: detected capacity change from 0 to 16777216
May 04 23:15:57 pve2 kernel: EXT4-fs (loop0): mounted filesystem a1a9e9ae-13db-462d-b3f8-37c7ee4aa49f r/w with ordered data mode. Quota mode: none.
-- Reboot --
May 05 13:21:48 pve2 kernel: Linux version 6.5.13-5-pve (build@proxmox) (gcc (Debian 12.2.0-14) 12.2.0, GNU ld (GNU Binutils for Debian) 2.40) #1 SMP PREEMPT_DYNAMIC PMX 6.5.13-5 (2024-04-05T11:03Z) ()
May 05 13:21:48 pve2 kernel: Command line: initrd=\EFI\proxmox\6.5.13-5-pve\initrd.img-6.5.13-5-pve root=ZFS=rpool/ROOT/pve-1 boot=zfs quiet intel_iommu=on iommu=pt pcie_acs_override=downstream,multifunction initcall_blacklist=sysfb_init
May 05 13:21:48 pve2 kernel: KERNEL supported cpus:
May 05 13:21:48 pve2 kernel: Intel GenuineIntel
May 05 13:21:48 pve2 kernel: AMD AuthenticAMD
```
This event happened last night at 11:00, and I had someone at the server location reboot it at around 1 PM today (May 5th).
A few things to note:
1. My servers aren't located in my house (as mentioned earlier.)
2. I'm on Proxmox 8.1.11, since I can't update to 8.2 until I am able to get to my server location because of the possibility of the new kernel update invalidating my network config.
3. I did not run out of system resources, since I was well under my RAM cap and most other VMs and CTs were shut down.
4. Any operations I did to these VMs/CTs, I have done before to other VMs plenty of times without issue on a much greater scale.
5. The drive I save backups to is an external 16TB USB hard drive with an XFS filesystem.
6. I have 1 other node in the cluster. (I know that isn't the best practice, but I have another node ready to be set up for when I go to my server location next time.)
I have also uploaded 2 files: one is a server specsheet, and the other is a screenshot of what happened to my node.
Thank you!
A few weeks ago, I decided to set up 2 virtual machines for hosting an LLM. One would have very limited resources and is just for simply hosting a web UI, and the other is a VM with a lot of resources including a GPU to run the LLMs and host an API.
Anyway, what happened is that a few weeks ago when I first made my AI setup, I was messing around with my API VM and wanted to do some config tweaks. Before doing anything of course, I shut down the VM and made a backup. I then proceeded to start up the VM and make my changes, and wouldn't you know, it broke my API config inside the VM. So then I went to restore the backup, and as soon as I hit restore, my entire node said connection lost and all of the VMs, CTs, and storage statuses turned from green checks to grey question marks.
From then, I was able to ping the server from another machine, but that is about it. I couldn't SSH into it because that would just hang, and I couldn't even access any other VMs that were on at the time or their services. I then had someone on site (the server isn't in my house) attempt to shut it down properly by hitting the power button once and then waiting, but that didn't do anything and the server had to be force reset. After that it would go back online and everything would be fine. After that, I deleted the 2 VMs, and everything was fine.
The second time this happened (yesterday), I decided I would play around with AI again, and make a more permanent solution that I can host and keep on 24/7. I created a VM with the API, and a Debian container to host the web UI. I gave my API VM about 70GB ram (out of a total of 128) + 12 vCPUs, and passed through a 3080 Ti. I went through the setup process, which involved some trial and error, so I had to backup and restore the VM a few times, which yielded no issues.
After that, I went to set up a Debian container for my web UI. I then set up the container, installed the web UI, and backed the container up before setting up an account or making any config tweaks. After a while, I decided that I wanted to tweak my initial setup a bit by adding another mount point to store uploaded media for organization purposes. So I shut down the container, went to my backup, pressed restore, and the exact same issue happened again. I had to get someone on site to force restart the machine to bring it back online the very next day.
TL;DR:
I have a server setup specifically for hosting AI services with two VMs: one for a web UI and another resource-intensive VM for running LLMs with a GPU. The problem arises when I attempt to restore backups. On two separate occasions, restoring backups caused my node to crash, losing connectivity and requiring a hard reboot to resolve.
Here is a short event log:
- Initial Setup: Created two VMs, one with limited resources for a web UI and another with extensive resources, including a GPU, for running LLMs.
- First Crash: Made configuration changes to the API VM and backed it up. Attempted to restore from backup led to a node crash and required a hard reboot.
- Recreation and Second Crash: Set up a more permanent VM for the API and a Debian container for the web UI. Successfully backed up and restored the VM multiple times, but the node crashed again when restoring the container backup.
- Symptoms: Both crashes resulted in loss of connectivity, with VM and container statuses turning to grey question marks. The system was unresponsive, requiring onsite intervention for a hard reset.
- Network and Resource Status: External operations such as pinging were possible, and resource usage was well below limits during the incidents.
Here is a log snippet from when it happened yesterday after I started a restore job of my web UI container (209):
```
May 04 23:14:54 pve2 postfix/smtp[880938]: 5F620324BF: to=<admin@mydomain.com>, relay=mail.mydomain.com[my ip]:25, delay=0.02, delays=0/0/0.02/0, dsn=4.1.8, status=deferred (host mail.mydomain.com[96.244.139.2] said: 450 4.1.8 <root@pve2.mydomain.com>: Sender address rejected: Domain not found (in reply to RCPT TO command))
May 04 23:15:57 pve2 pvedaemon[875774]: <root@pam> starting task UPID
ve2:000D72B7:01BE844C:6636F9ED:vzrestore:209:root@pam:May 04 23:15:57 pve2 kernel: loop0: detected capacity change from 0 to 16777216
May 04 23:15:57 pve2 kernel: EXT4-fs (loop0): mounted filesystem a1a9e9ae-13db-462d-b3f8-37c7ee4aa49f r/w with ordered data mode. Quota mode: none.
-- Reboot --
May 05 13:21:48 pve2 kernel: Linux version 6.5.13-5-pve (build@proxmox) (gcc (Debian 12.2.0-14) 12.2.0, GNU ld (GNU Binutils for Debian) 2.40) #1 SMP PREEMPT_DYNAMIC PMX 6.5.13-5 (2024-04-05T11:03Z) ()
May 05 13:21:48 pve2 kernel: Command line: initrd=\EFI\proxmox\6.5.13-5-pve\initrd.img-6.5.13-5-pve root=ZFS=rpool/ROOT/pve-1 boot=zfs quiet intel_iommu=on iommu=pt pcie_acs_override=downstream,multifunction initcall_blacklist=sysfb_init
May 05 13:21:48 pve2 kernel: KERNEL supported cpus:
May 05 13:21:48 pve2 kernel: Intel GenuineIntel
May 05 13:21:48 pve2 kernel: AMD AuthenticAMD
```
This event happened last night at 11:00, and I had someone at the server location reboot it at around 1 PM today (May 5th).
A few things to note:
1. My servers aren't located in my house (as mentioned earlier.)
2. I'm on Proxmox 8.1.11, since I can't update to 8.2 until I am able to get to my server location because of the possibility of the new kernel update invalidating my network config.
3. I did not run out of system resources, since I was well under my RAM cap and most other VMs and CTs were shut down.
4. Any operations I did to these VMs/CTs, I have done before to other VMs plenty of times without issue on a much greater scale.
5. The drive I save backups to is an external 16TB USB hard drive with an XFS filesystem.
6. I have 1 other node in the cluster. (I know that isn't the best practice, but I have another node ready to be set up for when I go to my server location next time.)
I have also uploaded 2 files: one is a server specsheet, and the other is a screenshot of what happened to my node.
Thank you!