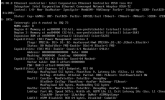
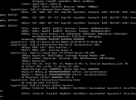
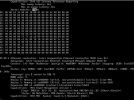
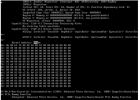
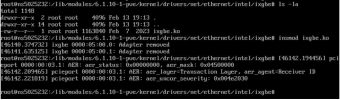
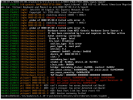
Thanks for this, Tim. Since the pastebin will expire soon, I opened this bugzilla report to preserve it indefinitely.
I don't think this is the ECAM/MCFG issue that I first suspected.
I don't have a good theory, but if you have a change, you might see whether booting with "amd_iommu=off" makes any difference. More details in the bugzilla I opened.
I don't think this is the ECAM/MCFG issue that I first suspected.
I don't have a good theory, but if you have a change, you might see whether booting with "amd_iommu=off" makes any difference. More details in the bugzilla I opened.
") - would be nice if problem can be identified / resolved but I realize that may not happen in short term, but we shall see.
- would be nice if problem can be identified / resolved but I realize that may not happen in short term, but we shall see.