Hi,
Sorry for the provocative punchline but there is something really strange going on here ...
I'm running ProxMox 4.3 but since my migration to ProxMox 4 (I was happily running a ProxMox 3 cluster before ...), I have a very weird (and dangerous) behaviour with ProxMox installed on SSDs.
So, to be clear, I'm running ProxMox in cluster mode (currently 14 nodes) with servers equipped that way :
I was using the exact same setup for more than a year with ProxMox 3 with no problem.
Since I migrated to ProxMox 4, my SSDs began to fail one after the other just a few months later.
At first, I thought it was a bad SSDs batch and I returned nearly half of it for RMA.
While sending back those disks, I replaced them with new ones, some Corsair, some Samsung.
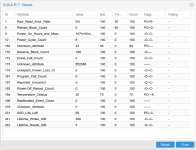
Since Corsair was the brand of the faulty disks, I monitorized them regularly and saw the SMART 231/SSD_Life_Left value going down slowly but since I thought they were pretty bad disks ... I didn't pay too much attention since I'm replacing them with Intel DC S3520 soon.
What really got my attention was the Samsung 830 I used to replace a faulty disk.
It was a new disk, freshly unboxed that was never used.
I know this is not a "Pro" disk but I already used many of those disks in many different situations and they are quite robust.
I installed it in my node about 2 months ago and guess what ? It is already at 10% wearout !!
10% !! In 2 months !!
I don't understand why it is like this ... there is nearly no activity on those disks, only log files and my whole /var/log accounts for under 100MB which is not enough to kill a SSD, even a bad one.
The only activity I see with iotop is this :
The "[jbd2/dm-0-8]" process is always on top of the list and eating the most of the ios but still ... this is not much, under 5% most of the time.
Other processes concerns mostly ceph but ceph OSDs are not the SSD and I don't use the SSD as journaling disk.
As I said ... only logs are written on this disk.
Any idea ?
Is there a way to preserve my SSDs or do I have to replace them with mechanical hard drives ??
Best regards.
Sorry for the provocative punchline but there is something really strange going on here ...
I'm running ProxMox 4.3 but since my migration to ProxMox 4 (I was happily running a ProxMox 3 cluster before ...), I have a very weird (and dangerous) behaviour with ProxMox installed on SSDs.
So, to be clear, I'm running ProxMox in cluster mode (currently 14 nodes) with servers equipped that way :
- 1x little SATA SSD drive with base ProxMox installation but used for nothing except the system itself (not used for local storage or LVM Thin)
- 4x SAS 15k drives used as OSDs for CEPH
I was using the exact same setup for more than a year with ProxMox 3 with no problem.
Since I migrated to ProxMox 4, my SSDs began to fail one after the other just a few months later.
At first, I thought it was a bad SSDs batch and I returned nearly half of it for RMA.
While sending back those disks, I replaced them with new ones, some Corsair, some Samsung.
Since Corsair was the brand of the faulty disks, I monitorized them regularly and saw the SMART 231/SSD_Life_Left value going down slowly but since I thought they were pretty bad disks ... I didn't pay too much attention since I'm replacing them with Intel DC S3520 soon.
What really got my attention was the Samsung 830 I used to replace a faulty disk.
It was a new disk, freshly unboxed that was never used.
I know this is not a "Pro" disk but I already used many of those disks in many different situations and they are quite robust.
I installed it in my node about 2 months ago and guess what ? It is already at 10% wearout !!
10% !! In 2 months !!
I don't understand why it is like this ... there is nearly no activity on those disks, only log files and my whole /var/log accounts for under 100MB which is not enough to kill a SSD, even a bad one.
The only activity I see with iotop is this :
Code:
Total DISK READ : 3.16 K/s | Total DISK WRITE : 4.67 M/s
Actual DISK READ: 3.16 K/s | Actual DISK WRITE: 4.93 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
789 be/3 root 0.00 B/s 15.39 K/s 0.00 % 4.29 % [jbd2/dm-0-8]
4912 be/4 root 0.00 B/s 2.38 M/s 0.00 % 1.01 % ceph-mon -i 2 --pid-file /var/run/ceph/mon.2.pid -c /etc/ceph/ceph.conf --cluster ceph -f
4445 be/4 root 0.00 B/s 96.70 K/s 0.00 % 0.08 % ceph-mon -i 2 --pid-file /var/run/ceph/mon.2.pid -c /etc/ceph/ceph.conf --cluster ceph -f
1989 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.07 % dmeventd -f
38396 be/4 root 808.30 B/s 0.00 B/s 0.00 % 0.04 % ceph-osd -i 8 --pid-file /var/run/ceph/osd.8.pid -c /etc/ceph/ceph.conf --cluster ceph -f
5487 be/4 root 808.30 B/s 0.00 B/s 0.00 % 0.04 % ceph-osd -i 7 --pid-file /var/run/ceph/osd.7.pid -c /etc/ceph/ceph.conf --cluster ceph -f
38359 be/4 root 0.00 B/s 808.30 B/s 0.00 % 0.02 % ceph-osd -i 8 --pid-file /var/run/ceph/osd.8.pid -c /etc/ceph/ceph.conf --cluster ceph -f
5369 be/4 root 0.00 B/s 1212.45 B/s 0.00 % 0.01 % ceph-osd -i 6 --pid-file /var/run/ceph/osd.6.pid -c /etc/ceph/ceph.conf --cluster ceph -f
5094 be/4 root 0.00 B/s 808.30 B/s 0.00 % 0.01 % ceph-osd -i 7 --pid-file /var/run/ceph/osd.7.pid -c /etc/ceph/ceph.conf --cluster ceph -fThe "[jbd2/dm-0-8]" process is always on top of the list and eating the most of the ios but still ... this is not much, under 5% most of the time.
Other processes concerns mostly ceph but ceph OSDs are not the SSD and I don't use the SSD as journaling disk.
As I said ... only logs are written on this disk.
Any idea ?
Is there a way to preserve my SSDs or do I have to replace them with mechanical hard drives ??
Best regards.