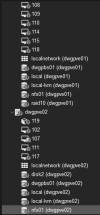
I have two proxmox machines in Cluster and I do not run any vms on shared storage (but I do backups to the shared nfs storage) and no HA or redundancy or remote storage for any vm.
Suddenly, all machines shows question mark and about each 2nd nigth, two of the machines (running really ligth load) is going down for no apparent reason. I can't connect to its console, but I can stop it and start it. Then it runs good for two days (but still with question marks on all machines and all storage).
I suspect this started due to a shared nfs-storage got full due to backups. But again, I do not run any vms off it, so can't understand how it can relate. I have made more space on the backup-nfs-device.
pve-manager/6.2-12/b287dd27
Cluster information
-------------------
Name: XX
Config Version: 2
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Tue Dec 22 01:26:41 2020
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 0x00000002
Ring ID: 1.1cd
Quorate: Yes
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1
0x00000002 1 (local)
Suddenly, all machines shows question mark and about each 2nd nigth, two of the machines (running really ligth load) is going down for no apparent reason. I can't connect to its console, but I can stop it and start it. Then it runs good for two days (but still with question marks on all machines and all storage).
I suspect this started due to a shared nfs-storage got full due to backups. But again, I do not run any vms off it, so can't understand how it can relate. I have made more space on the backup-nfs-device.
pve-manager/6.2-12/b287dd27
Cluster information
-------------------
Name: XX
Config Version: 2
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Tue Dec 22 01:26:41 2020
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 0x00000002
Ring ID: 1.1cd
Quorate: Yes
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1
0x00000002 1 (local)