Hi. There are 2 PNG (there are 2 MX records). Both PMG are in the cluster. The first PMG sends emails through the first ISP, the second PMG sends emails through the second ISP. PMG version 8.0.7.
DNS servers on domain controllers (MS Active Directory). The NTP servers are specified by Google (8.8.8.8 and 8.8.4.4).
Both PMG have been working like this for 3-4 years. There were no problems at all.
Now for 10 days there is a problem with the second PMG. The settings were not changed, no new settings were made. The Internet provider checked everything, there are no problems on their part.
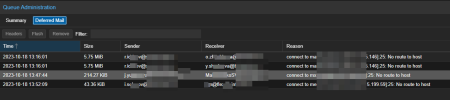
The problem is the following: on the second PMG periodically (quite often) outgoing emails get into the queue. At the same time, there are no problems with incoming emails (they all arrive at once). Outgoing emails end up in a queue with statuses: "No Route to host" and "Network Unreachable". If you go into the queue and execute the "Flush Queue", then as luck would have it, the letters can leave immediately, or they can only on the 20th attempt (thus, something will leave in 1 minute, something in 30 minutes). That is, when you click the Flush Queue, the emails will either leave immediately or you need to wait for time, otherwise they will again get in line with the same statuses. I didn't understand what it depends on. It's as if he doesn't understand where to send him, and then from the 10th or 20th attempt he understands where he needs to go.
I repeat that everything is perfect at the first PMG. There are no problems with incoming messages on the second PMG, the problem is only with outgoing emails.
There is no additional information in the logs. Everything is the same as in the screenshot. There's just the same status No route to host, Network Unreachable. That is, there is no additional information to grab onto.
What are the possible options? All settings on both hosts have not changed and are identical.
DNS servers on domain controllers (MS Active Directory). The NTP servers are specified by Google (8.8.8.8 and 8.8.4.4).
Both PMG have been working like this for 3-4 years. There were no problems at all.
Now for 10 days there is a problem with the second PMG. The settings were not changed, no new settings were made. The Internet provider checked everything, there are no problems on their part.
The problem is the following: on the second PMG periodically (quite often) outgoing emails get into the queue. At the same time, there are no problems with incoming emails (they all arrive at once). Outgoing emails end up in a queue with statuses: "No Route to host" and "Network Unreachable". If you go into the queue and execute the "Flush Queue", then as luck would have it, the letters can leave immediately, or they can only on the 20th attempt (thus, something will leave in 1 minute, something in 30 minutes). That is, when you click the Flush Queue, the emails will either leave immediately or you need to wait for time, otherwise they will again get in line with the same statuses. I didn't understand what it depends on. It's as if he doesn't understand where to send him, and then from the 10th or 20th attempt he understands where he needs to go.
I repeat that everything is perfect at the first PMG. There are no problems with incoming messages on the second PMG, the problem is only with outgoing emails.
There is no additional information in the logs. Everything is the same as in the screenshot. There's just the same status No route to host, Network Unreachable. That is, there is no additional information to grab onto.
What are the possible options? All settings on both hosts have not changed and are identical.
Attachments

Last edited:
