Hello,
We have a need to migrate machines between nodes, but we need to do it quickly.
Is there a possibility of optimization?
Are there any magic parameters?
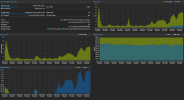
It seems that in our case the processor is the bottleneck.,When starting the migration it used full CPU, which causes us not to be able to saturate the disk and network interface (only 50%) and the migration takes relatively long. Each of the VM disks has only a single TB. The server seems to be relatively new but still we think it is not optimal. We would like the effect that both the disks and the network are fully saturated.
What can we do to make it faster?
something like RDMA ?
screeen attached
We have a need to migrate machines between nodes, but we need to do it quickly.
Is there a possibility of optimization?
Are there any magic parameters?
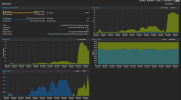
It seems that in our case the processor is the bottleneck.,When starting the migration it used full CPU, which causes us not to be able to saturate the disk and network interface (only 50%) and the migration takes relatively long. Each of the VM disks has only a single TB. The server seems to be relatively new but still we think it is not optimal. We would like the effect that both the disks and the network are fully saturated.
What can we do to make it faster?
something like RDMA ?
screeen attached
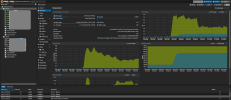
") ? I would be happy reaching 25GB/s
? I would be happy reaching 25GB/s