On a few of my Dell servers I can't get any of the kernel to work properly. I can't pass trough my PERC HBA controller to TrueNas Core (or scale). It hang in different behavior depending of options I'm trying.
Basically, I'm playing with 3 server atm:
r830 using PERC H730p in HBA mode =>NOTHING WORK (grub or uefi)
r730 using PERC H730p in HBA mode => WORK (grub)
r730xp using PERC H730 mini in HBA => NOTHING WORK (grub or uefi)
I think I've re-install proxmox more then 20 times on these severs since the last days.
Fun fact, it worked on my r730. This one is actually using Grub. But all of my journey with the 2 other server in bios Grub wasn't working so actually r730xd and r830 are UEFI (setting stuff around like usual /etc/kernel/cmdline, pve-efiboot-tool refresh)
My "VM use-case" to test the pci pass-through is TrueNasCore latest. For my r730 in grub, nothing special. I've added a pci device, which is my Perc H730p
Code:
root@antares:~# lspci -vmmnn |grep RAID
Class: RAID bus controller [0104]
Device: MegaRAID SAS-3 3108 [Invader] [005d]
So far, all of my 3 servers are up to date based on the bios&firmwares Dell's catalog (using lifecycle controller). I've verified that ALL my bios and device settings are the same as the r730, but the r730xd and the r830 don't work. They hang the whole server when I start TrueNas with the PCI passtrough added. If no passtrhough, no problem (but no drive).
On all 3 machine, everything seems to be enabled:
'find /sys/kernel/iommu_groups/ -type l' outputs the list accordingly
IOMMU is enabled, etc. etc.
Here are the kernel I've tried so far:
apt update && apt install pve-kernel-5.15
apt update && apt install pve-kernel-5.15.7-1-pve
apt update && apt install pve-kernel-5.15.19-1-pve
apt update && apt install pve-kernel-5.15.30-1-pve
I can believe I've spent so much time on this. In fact, I've messed around with a typo (intel=iommu=on instead on the right intel_iommu=on), but that was just a bad typo in my notes. I've very few doc for my situation.
To conclude here are the list of lspci followed by dell idrac invetory report, for the 3 controller from proxmox console
R730
03:00.0 RAID bus controller: Broadcom / LSI MegaRAID SAS-3 3108 [Invader] (rev 02)
PERC H730P Mini 25.5.9.0001
R830
03:00.0 RAID bus controller: Broadcom / LSI MegaRAID SAS-3 3108 [Invader] (rev 02)
PERC H730P Adapter 25.5.9.0001
R730xd
03:00.0 RAID bus controller: Broadcom / LSI MegaRAID SAS-3 3108 [Invader] (rev 02)
PERC H730 Mini 25.5.9.0001
Do we need to wait for a fix? I feel a dead end here so far.
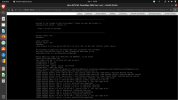
Is there a log I can share to help debugging this? I would like to use tail -f /var/log/syslog but the system hang too early. Only thing I've grabbed a few days ago was from the iDrac remote controller windows, (see attached img)
")