I'm glad I found this thread which was active as recently as a few weeks ago. I'm having this exact same issue in Truenas SCALE, which is similar to Proxmox in that it's a hypervisor built on top of Debian.
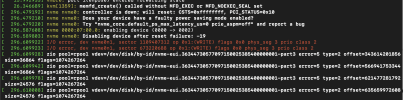
I have a ZFS pool that's a three-way NVME SSD mirror on which I have a number of VMs. One of the SSDs in the pool periodically goes offline, putting the pool into a degraded state (but still functional since it's a mirror). When this happens, I get the same exact error messages as all of you did in /var/log/messages, which is:
Apr 15 20:04:06 patrick-server1 kernel: nvme nvme0: controller is down; will reset: CSTS=0xffffffff, PCI_STATUS=0x10
Apr 15 20:04:06 patrick-server1 kernel: nvme nvme0: Does your device have a faulty power saving mode enabled?
Apr 15 20:04:06 patrick-server1 kernel: nvme nvme0: Try "nvme_core.default_ps_max_latency_us=0 pcie_aspm=off" and report a bug
Apr 15 20:04:06 patrick-server1 kernel: nvme 0000:10:00.0: enabling device (0000 -> 0002)
Apr 15 20:04:06 patrick-server1 kernel: nvme nvme0: Removing after probe failure status: -19
After a failure such as this, if I reboot the server, the SSD typically comes back online, and after a short resilvering operation, it's OK for a while. That could be a couple of hours until it happens again, a couple of days, or if I'm lucky it will be a couple of weeks before the failure occurs again.
This problem started for me a couple of months ago, in late February 2024.
Here is some more detail. First, this only happens with the one SSD installed on a PCIE card. It does not happen with the two SSDs installed In M.2 slots directly on the motherboard. Second, I have tried switching SSDs including adding a brand new SSD, and that doesn't fix the problem. Third, I have tried swapping out the PCIE card that holds the SSD, and that doesn't fix the problem either. Fourth, the kernel version is 6.1.74.
It's only yesterday when it happened that I thought to look in /var/log/messages, so I have not yet tried the recommended fix of disabling power saver mode with nvme_core.default_ps_max_latency_us=0 pcie_aspm=off.
I'm going to try that now, but I'm not optimistic that it will solve the problem since some in this thread have tried it and still had SSD failure. Also, it doesn't seem like an ideal solution because it's bound to increase power consumption overall on the server. Still, since I can't think of anything else to try, I will try it.
If anyone has anything more to report, I would appreciate hearing it.