Hi all, i've a 3 nodes cluster (Proxmox VE 4.1) with active subscription. On this cluster i had a HA configured for one VM. I've delete this HA configuration because of a network maintenance. But now, when i am going in HA i can see this message on the "master" line :
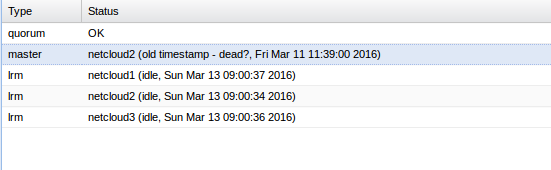
Any idea for this issue ?
kind regards,
--
Christophe Casalegno
http://www.christophe-casalegno.com
Any idea for this issue ?
kind regards,
--
Christophe Casalegno
http://www.christophe-casalegno.com
")