Hallo miteinander,
Ich habe zuhause einen Wireguard in einem LXC Container laufen.
Hostname: sv19-wireguard
ID: 119
Nun ist es so, dass die Kiste um 11:54:06 Uhr einfach abgeschaltet hat.
Mitbekommen habe ich dies dann über mein Monitoring als Push.
Die Kiste läuft gut, ich nutze sie gerade viel, da ich im Kurzurlaub bin und meinen ganzen Traffic übers Hotel-WLAN via VPN nach Hause schicke.
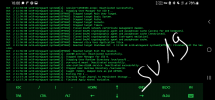
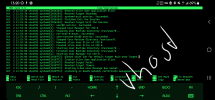
Ich habe nun in der Syslog vom Proxmox Host reingeschaut und auch in der des LXCs.
Das was ich auf dem Host an Informationen gefunden habe hilft mir nicht wirklich weiter. Ich würde gerne wissen wollen, warum die Kiste einfach aus geht. Nachdem ich dann ca 20 nach 12 auf mein Handy geschaut habe, hab ich den Container wieder eingeschaltet. Er läuft wieder. Ohne Probleme.
Frage an euch:
Wo kann ich noch nachgucken?
Ich habe natürlich auch in die Auth.log geguckt, aber da ist nichts auffälliges zu erkennen. Das Monitoring meldet sich halt jede Minute einmal an um den Zustand zu Prüfen. (zu meiner Verteidigung: ich habe erst vor ein paar Tagen auf SNMP umgestellt^^)
Ich hänge hier noch Screenshots an. Vielleicht geben die etwas Aufschluss.
Wäre klasse, wenn sich vielleicht doch noch jemand findet, der ein wenig was sagen kann.
Vielen Dank und einen schönen Sonntag an alle!")
Ich habe zuhause einen Wireguard in einem LXC Container laufen.
Hostname: sv19-wireguard
ID: 119
Nun ist es so, dass die Kiste um 11:54:06 Uhr einfach abgeschaltet hat.
Mitbekommen habe ich dies dann über mein Monitoring als Push.
Die Kiste läuft gut, ich nutze sie gerade viel, da ich im Kurzurlaub bin und meinen ganzen Traffic übers Hotel-WLAN via VPN nach Hause schicke.
Ich habe nun in der Syslog vom Proxmox Host reingeschaut und auch in der des LXCs.
Das was ich auf dem Host an Informationen gefunden habe hilft mir nicht wirklich weiter. Ich würde gerne wissen wollen, warum die Kiste einfach aus geht. Nachdem ich dann ca 20 nach 12 auf mein Handy geschaut habe, hab ich den Container wieder eingeschaltet. Er läuft wieder. Ohne Probleme.
Frage an euch:
Wo kann ich noch nachgucken?
Ich habe natürlich auch in die Auth.log geguckt, aber da ist nichts auffälliges zu erkennen. Das Monitoring meldet sich halt jede Minute einmal an um den Zustand zu Prüfen. (zu meiner Verteidigung: ich habe erst vor ein paar Tagen auf SNMP umgestellt^^)
Ich hänge hier noch Screenshots an. Vielleicht geben die etwas Aufschluss.
Wäre klasse, wenn sich vielleicht doch noch jemand findet, der ein wenig was sagen kann.
Vielen Dank und einen schönen Sonntag an alle!