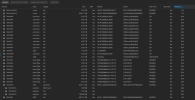
13.305742] audit: type=1400 audit(1716294521.921:2): apparmor="STATUS" operation="profile_load" profile="unconfined" name="swtpm" pid=1531 comm="apparmor_parser"
[ 13.306036] audit: type=1400 audit(1716294521.921:3): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/bin/lxc-start" pid=1532 comm="apparmor_parser"
[ 13.306397] audit: type=1400 audit(1716294521.921:4): apparmor="STATUS" operation="profile_load" profile="unconfined" name="lsb_release" pid=1530 comm="apparmor_parser"
[ 13.307351] audit: type=1400 audit(1716294521.921:5): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe" pid=1526 comm="apparmor_parser"
[ 13.307357] audit: type=1400 audit(1716294521.921:6): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe//kmod" pid=1526 comm="apparmor_parser"
[ 13.307761] audit: type=1400 audit(1716294521.921:7): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/bin/man" pid=1533 comm="apparmor_parser"
[ 13.307766] audit: type=1400 audit(1716294521.921:8): apparmor="STATUS" operation="profile_load" profile="unconfined" name="man_filter" pid=1533 comm="apparmor_parser"
[ 13.307769] audit: type=1400 audit(1716294521.921:9): apparmor="STATUS" operation="profile_load" profile="unconfined" name="man_groff" pid=1533 comm="apparmor_parser"
[ 13.309652] audit: type=1400 audit(1716294521.925:10): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/sbin/chronyd" pid=1528 comm="apparmor_parser"
[ 13.312493] audit: type=1400 audit(1716294521.925:11): apparmor="STATUS" operation="profile_load" profile="unconfined" name="tcpdump" pid=1529 comm="apparmor_parser"
[ 13.338553] softdog: initialized. soft_noboot=0 soft_margin=60 sec soft_panic=0 (nowayout=0)
[ 13.338560] softdog: soft_reboot_cmd=<not set> soft_active_on_boot=0
[ 13.714295] vmbr0: port 1(eno1) entered blocking state
[ 13.714301] vmbr0: port 1(eno1) entered disabled state
[ 13.714367] device eno1 entered promiscuous mode
[ 15.401009] igb 0000:07:00.0 eno1: igb: eno1 NIC Link is Up 100 Mbps Full Duplex, Flow Control: RX/TX
[ 15.401168] vmbr0: port 1(eno1) entered blocking state
[ 15.401172] vmbr0: port 1(eno1) entered forwarding state
[ 15.401359] IPv6: ADDRCONF(NETDEV_CHANGE): vmbr0: link becomes ready
[ 16.081315] bpfilter: Loaded bpfilter_umh pid 1877
[ 16.081582] Started bpfilter
[ 26.304466] L1TF CPU bug present and SMT on, data leak possible. See CVE-2018-3646 and https://www.kernel.org/doc/html/latest/admin-guide/hw-vuln/l1tf.html for details.
[ 65.318382] {1}[Hardware Error]: Hardware error from APEI Generic Hardware Error Source: 1
[ 65.318416] {1}[Hardware Error]: It has been corrected by h/w and requires no further action
[ 65.318417] {1}[Hardware Error]: event severity: corrected
[ 65.318419] {1}[Hardware Error]: Error 0, type: corrected
[ 65.318420] {1}[Hardware Error]: fru_text: CorrectedErr
[ 65.318421] {1}[Hardware Error]: section_type: PCIe error
[ 65.318422] {1}[Hardware Error]: port_type: 0, PCIe end point
[ 65.318423] {1}[Hardware Error]: version: 0.0
[ 65.318424] {1}[Hardware Error]: command: 0xffff, status: 0xffff
[ 65.318425] {1}[Hardware Error]: device_id: 0000:80:02.3
[ 65.318426] {1}[Hardware Error]: slot: 0
[ 65.318427] {1}[Hardware Error]: secondary_bus: 0x00
[ 65.318428] {1}[Hardware Error]: vendor_id: 0xffff, device_id: 0xffff
[ 65.318429] {1}[Hardware Error]: class_code: ffffff
[ 109.345339] sd 0:1:31:0: [sdl] tag#791 Sense Key : Recovered Error [current]
[ 109.345365] sd 0:1:31:0: [sdl] tag#791 Add. Sense: Defect list not found
root@pve:~#