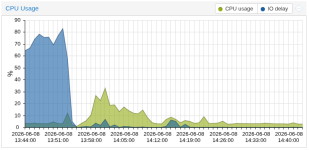
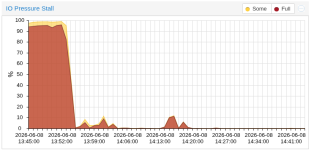
After updating a host from 9.1.4 > 9.2.3 I'm noticing that there is now a noticeable increase in IO pressure.
Update was done an host rebooting at around 2026-06-01@13:00

Same thing with IO Delay:

Anyone else who have updated have the same issue?
Thanks for your help
Update was done an host rebooting at around 2026-06-01@13:00
Same thing with IO Delay:
Anyone else who have updated have the same issue?
Thanks for your help

")

") Still, the values from
Still, the values from