hi,
we've got notifications from our monitoring (Icinga2), which is a VM on a PVE 5.2 host, with WD RED(WDC WD10JFCX-68N6GN0) 6 x 1TB (2.5") as Raidz2, because of timeouts (check_icmp).
After a longer investigation, we found out, that these alerts where false positives, because the monitoring VM itself wasn't able to execute checks.
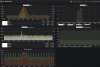
Our metrics from Icinga2 and Telegraf (both in InfluxDB) shows, that the I/O was going up, at exact 6:25, which is the time from cron.daily.
The CPU is a E3-1270 v5 @ 3.5Ghz and we have 64GB DDR4 ECC. Arc is limited from min 6GB till max 12GB ram.
Glad that we are collecting via Telegraf also ZFS stats, but I'm not sure, how to interpret them. Maybe someone can help us out.
We using the Supermicro X11SSH-TF and a LSI/Broadcom controller (SAS3008). The only thing what we can do: we have a single M.2 slot free .. maybe we can use it as cache ?
Any suggestions?
we've got notifications from our monitoring (Icinga2), which is a VM on a PVE 5.2 host, with WD RED(WDC WD10JFCX-68N6GN0) 6 x 1TB (2.5") as Raidz2, because of timeouts (check_icmp).
After a longer investigation, we found out, that these alerts where false positives, because the monitoring VM itself wasn't able to execute checks.
Our metrics from Icinga2 and Telegraf (both in InfluxDB) shows, that the I/O was going up, at exact 6:25, which is the time from cron.daily.
The CPU is a E3-1270 v5 @ 3.5Ghz and we have 64GB DDR4 ECC. Arc is limited from min 6GB till max 12GB ram.
Glad that we are collecting via Telegraf also ZFS stats, but I'm not sure, how to interpret them. Maybe someone can help us out.
We using the Supermicro X11SSH-TF and a LSI/Broadcom controller (SAS3008). The only thing what we can do: we have a single M.2 slot free .. maybe we can use it as cache ?
Any suggestions?
")

")