Hello all,
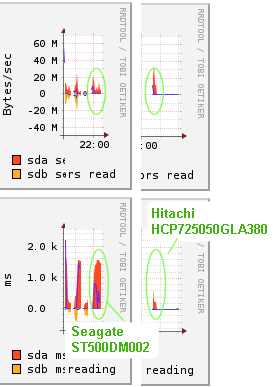
I'm running Proxmox 1.8 on a Supermicro server with 8 hot-swap bays with hardware raid and 2 normals bays for sata disks (used for back-up).
This night, when the back-ups started, both sata disks crashed suddenly.
[TD="align: right"]11.07GB[/TD]
[TD="align: right"]11.40GB[/TD]
[TD="align: right"]7.29GB[/TD]
[TD="colspan: 2"]unable to create temporary directory '/mnt/backup2/vzdump-qemu-107-2011_11_11-02_14_34.tmp' at /usr/share/perl5/PVE/VZDump.pm line 830.[/TD]
When I checked the disk, it was mounted as read-only. I could still see the data, but nothing was working.
When I checked /mnt/backup1, wich isn't used for snapshot back-ups, i noticed it was also mounted as read-only.
I umounted both sata disks and tried to mount them again:
proxmox01:/mnt# mount -a
mount: wrong fs type, bad option, bad superblock on /dev/sdc1,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
mount: wrong fs type, bad option, bad superblock on /dev/sdb1,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
After this I did dmesg | tail
proxmox01:/mnt# dmesg | tail
sd 5:0:1:0: [sdc] Unhandled error code
sd 5:0:1:0: [sdc] Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
sd 5:0:1:0: [sdc] CDB: Read(10): 28 00 00 00 00 24 00 00 02 00
end_request: I/O error, dev sdc, sector 36
EXT3-fs (sdc1): error: unable to read superblock
sd 5:0:0:0: [sdb] Unhandled error code
sd 5:0:0:0: [sdb] Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
sd 5:0:0:0: [sdb] CDB: Read(10): 28 00 00 00 00 24 00 00 02 00
end_request: I/O error, dev sdb, sector 36
EXT3-fs (sdb1): error: unable to read superblock
I tried to recover with fsck:
proxmox01:/mnt# fsck /dev/sdb1
fsck 1.41.3 (12-Oct-2008)
e2fsck 1.41.3 (12-Oct-2008)
fsck.ext2: Attempt to read block from filesystem resulted in short read while trying to open /dev/sdb1
Could this be a zero-length partition?
I located the back-up superblocks:
mke2fs -n /dev/sdb1
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Tried to restore from a back-up superblock:
fsck -b 32768 /dev/sdb1
fsck -b 214990848 /dev/sdb1
Same error as with normal superblock
After this I installed smartctl and checked the disks SMART status, it's OK on both disks.
I try to read the partitions:
fdisk -l = nogo
proxmox01:/mnt# fdisk /dev/sdb
Unable to read /dev/sdb
I tried to format the disks:
Warning: could not read block 0: Attempt to read block from filesystem resulted in short read
Nothing is working, not even formatting the disks. Somehow the server lost those 2 sata disks without a real disk problem.
I had this problem before on a smaller server. When I was doing snapshots + normal file back-up, the disks crashed constantly. Maybe this is the samen problem I have now.
At this moment I can't shutdown the Proxmox host, it's live now and located in a datacenter. Can anyone tell me what I can try to recover those drives? I don't care if it needs to be formatted, I just need them back for good back-ups.
proxmox01:/mnt# pveversion -v
pve-manager: 1.8-18 (pve-manager/1.8/6070)
running kernel: 2.6.35-1-pve
proxmox-ve-2.6.35: 1.8-11
pve-kernel-2.6.32-4-pve: 2.6.32-33
pve-kernel-2.6.35-1-pve: 2.6.35-11
qemu-server: 1.1-30
pve-firmware: 1.0-11
libpve-storage-perl: 1.0-17
vncterm: 0.9-2
vzctl: 3.0.28-1pve1
vzdump: 1.2-14
vzprocps: 2.0.11-2
vzquota: 3.0.11-1
pve-qemu-kvm: 0.14.1-1
ksm-control-daemon: 1.0-6
proxmox01:/mnt# pveperf
CPU BOGOMIPS: 32003.38
REGEX/SECOND: 660707
HD SIZE: 9.17 GB (/dev/mapper/pve-os)
BUFFERED READS: 293.76 MB/sec
AVERAGE SEEK TIME: 9.94 ms
FSYNCS/SECOND: 1288.16
DNS EXT: 57.91 ms
The hardware is: http://www.supermicro.com/Aplus/system/2U/2022/AS-2022G-URF.cfm
With 64GB mem and 1 AMD 8 core cpu, running around 20+ vm's
8 sata disks with a adaptec 2805 hardware raid
2 sata disks connected to the motherboard sata connectors (non-raid)
I'm running Proxmox 1.8 on a Supermicro server with 8 hot-swap bays with hardware raid and 2 normals bays for sata disks (used for back-up).
This night, when the back-ups started, both sata disks crashed suddenly.
| VMID | NAME | STATUS | TIME | SIZE | FILENAME |
| 101 | X | OK | 00:08:36 | /mnt/backup2/vzdump-qemu-101-2011_11_11-02_00_01.tar | |
| 105 | XX | OK | 00:02:16 | /mnt/backup2/vzdump-qemu-105-2011_11_11-02_08_37.tar | |
| 106 | XXX | OK | 00:03:41 | /mnt/backup2/vzdump-qemu-106-2011_11_11-02_10_53.tar | |
| 107 | VM 107 | FAILED | 00:00:00 |
[TD="align: right"]11.07GB[/TD]
[TD="align: right"]11.40GB[/TD]
[TD="align: right"]7.29GB[/TD]
[TD="colspan: 2"]unable to create temporary directory '/mnt/backup2/vzdump-qemu-107-2011_11_11-02_14_34.tmp' at /usr/share/perl5/PVE/VZDump.pm line 830.[/TD]
When I checked the disk, it was mounted as read-only. I could still see the data, but nothing was working.
When I checked /mnt/backup1, wich isn't used for snapshot back-ups, i noticed it was also mounted as read-only.
I umounted both sata disks and tried to mount them again:
proxmox01:/mnt# mount -a
mount: wrong fs type, bad option, bad superblock on /dev/sdc1,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
mount: wrong fs type, bad option, bad superblock on /dev/sdb1,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
After this I did dmesg | tail
proxmox01:/mnt# dmesg | tail
sd 5:0:1:0: [sdc] Unhandled error code
sd 5:0:1:0: [sdc] Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
sd 5:0:1:0: [sdc] CDB: Read(10): 28 00 00 00 00 24 00 00 02 00
end_request: I/O error, dev sdc, sector 36
EXT3-fs (sdc1): error: unable to read superblock
sd 5:0:0:0: [sdb] Unhandled error code
sd 5:0:0:0: [sdb] Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
sd 5:0:0:0: [sdb] CDB: Read(10): 28 00 00 00 00 24 00 00 02 00
end_request: I/O error, dev sdb, sector 36
EXT3-fs (sdb1): error: unable to read superblock
I tried to recover with fsck:
proxmox01:/mnt# fsck /dev/sdb1
fsck 1.41.3 (12-Oct-2008)
e2fsck 1.41.3 (12-Oct-2008)
fsck.ext2: Attempt to read block from filesystem resulted in short read while trying to open /dev/sdb1
Could this be a zero-length partition?
I located the back-up superblocks:
mke2fs -n /dev/sdb1
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Tried to restore from a back-up superblock:
fsck -b 32768 /dev/sdb1
fsck -b 214990848 /dev/sdb1
Same error as with normal superblock
After this I installed smartctl and checked the disks SMART status, it's OK on both disks.
I try to read the partitions:
fdisk -l = nogo
proxmox01:/mnt# fdisk /dev/sdb
Unable to read /dev/sdb
I tried to format the disks:
Warning: could not read block 0: Attempt to read block from filesystem resulted in short read
Nothing is working, not even formatting the disks. Somehow the server lost those 2 sata disks without a real disk problem.
I had this problem before on a smaller server. When I was doing snapshots + normal file back-up, the disks crashed constantly. Maybe this is the samen problem I have now.
At this moment I can't shutdown the Proxmox host, it's live now and located in a datacenter. Can anyone tell me what I can try to recover those drives? I don't care if it needs to be formatted, I just need them back for good back-ups.
proxmox01:/mnt# pveversion -v
pve-manager: 1.8-18 (pve-manager/1.8/6070)
running kernel: 2.6.35-1-pve
proxmox-ve-2.6.35: 1.8-11
pve-kernel-2.6.32-4-pve: 2.6.32-33
pve-kernel-2.6.35-1-pve: 2.6.35-11
qemu-server: 1.1-30
pve-firmware: 1.0-11
libpve-storage-perl: 1.0-17
vncterm: 0.9-2
vzctl: 3.0.28-1pve1
vzdump: 1.2-14
vzprocps: 2.0.11-2
vzquota: 3.0.11-1
pve-qemu-kvm: 0.14.1-1
ksm-control-daemon: 1.0-6
proxmox01:/mnt# pveperf
CPU BOGOMIPS: 32003.38
REGEX/SECOND: 660707
HD SIZE: 9.17 GB (/dev/mapper/pve-os)
BUFFERED READS: 293.76 MB/sec
AVERAGE SEEK TIME: 9.94 ms
FSYNCS/SECOND: 1288.16
DNS EXT: 57.91 ms
The hardware is: http://www.supermicro.com/Aplus/system/2U/2022/AS-2022G-URF.cfm
With 64GB mem and 1 AMD 8 core cpu, running around 20+ vm's
8 sata disks with a adaptec 2805 hardware raid
2 sata disks connected to the motherboard sata connectors (non-raid)
Last edited:
")