Hello,
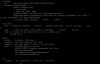
we have the same problem. We have 4 node cluster with ceph and HA for VMs. When 4 nodes are up, performance is good:
Object prefix: benchmark_data_vm-host5_509634
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 239 223 891.928 892 0.0874671 0.0706119
2 16 454 438 875.92 860 0.0648146 0.0710034
3 16 672 656 874.575 872 0.0482636 0.0717775
4 16 900 884 883.904 912 0.0464978 0.0716867
5 16 1129 1113 890.303 916 0.024642 0.0715882
But when 1 node goes down, this happens:
Object prefix: benchmark_data_vm-host5_509929
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 34 18 71.9934 72 0.0223113 0.0443496
2 16 34 18 35.995 0 - 0.0443496
3 16 34 18 23.9968 0 - 0.0443496
4 16 34 18 17.9976 0 - 0.0443496
5 16 34 18 14.3981 0 - 0.0443496
6 16 34 18 11.9984 0 - 0.0443496
we use pve-manager/6.0-7/28984024 (running kernel: 5.0.21-2-pve) on our 4 nodes.
CEPH.CONF
[global]
auth_client_required = cephx
auth_cluster_required = cephx
auth_service_required = cephx
cluster_network = 10.37.28.0/24
fsid = d2a41b91-e4ec-4e4c-bab9-c08c9fedc78c
mon_allow_pool_delete = true
mon_host = 10.37.28.6 10.37.28.5 10.37.28.4 10.37.28.3
osd_pool_default_min_size = 2
osd_pool_default_size = 3
public_network = 10.37.27.0/24
ms_bind_port_max = 8300
debug asok = 0/0
debug auth = 0/0
debug bdev = 0/0
debug bluefs = 0/0
debug bluestore = 0/0
debug buffer = 0/0
debug civetweb = 0/0
debug client = 0/0
debug compressor = 0/0
debug context = 0/0
debug crush = 0/0
debug crypto = 0/0
debug dpdk = 0/0
debug eventtrace = 0/0
debug filer = 0/0
debug filestore = 0/0
debug finisher = 0/0
debug fuse = 0/0
debug heartbeatmap = 0/0
debug javaclient = 0/0
debug journal = 0/0
debug journaler = 0/0
debug kinetic = 0/0
debug kstore = 0/0
debug leveldb = 0/0
debug lockdep = 0/0
debug mds = 0/0
debug mds balancer = 0/0
debug mds locker = 0/0
debug mds log = 0/0
debug mds log expire = 0/0
debug mds migrator = 0/0
debug memdb = 0/0
debug mgr = 0/0
debug mgrc = 0/0
debug mon = 0/0
debug monc = 0/00
debug ms = 0/0
debug none = 0/0
debug objclass = 0/0
debug objectcacher = 0/0
debug objecter = 0/0
debug optracker = 0/0
debug osd = 0/0
debug paxos = 0/0
debug perfcounter = 0/0
debug rados = 0/0
debug rbd = 0/0
debug rbd mirror = 0/0
debug rbd replay = 0/0
debug refs = 0/0
debug reserver = 0/0
debug rgw = 0/0
debug rocksdb = 0/0
debug striper = 0/0
debug throttle = 0/0
debug timer = 0/0
debug tp = 0/0
debug xio = 0/0
[client]
keyring = /etc/pve/priv/$cluster.$name.keyring
[mon]
mon allow pool delete = True
mon health preluminous compat = True
mon osd down out interval = 300
[osd]
bluestore cache autotune = 0
bluestore cache kv ratio = 0.2
bluestore cache meta ratio = 0.8
bluestore cache size ssd = 8G
bluestore csum type = none
bluestore extent map shard max size = 200
bluestore extent map shard min size = 50
bluestore extent map shard target size = 100
bluestore rocksdb options = compression=kNoCompression,max_write_buffer_number=32,min_write_buffer_number_to_merge=2,recycle_log_file_num=32,compaction_style=kCompactionStyleLevel,write_buffer_size=67108864,target_file_size_base=67108864,max_background_compactions=31,level0_file_num_compaction_trigger=8,level0_slowdown_writes_trigger=32,level0_stop_writes_trigger=64,max_bytes_for_level_base=536870912,compaction_threads=32,max_bytes_for_level_multiplier=8,flusher_threads=8,compaction_readahead_size=2MB
osd map share max epochs = 100
osd max backfills = 5
osd memory target = 4294967296
osd op num shards = 8
osd op num threads per shard = 2
osd min pg log entries = 10
osd max pg log entries = 10
osd pg log dups tracked = 10
osd pg log trim min = 10
 Why did I do that ?
Why did I do that ?