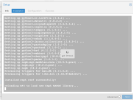
Dec 02 17:58:02 pve3 pvestatd[2706]: status update time (5.137 seconds)
Dec 02 18:02:00 pve3 systemd[1]: Starting Proxmox VE replication runner...
-- Subject: A start job for unit pvesr.service has begun execution
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit pvesr.service has begun execution.
--
-- The job identifier is 84803.
Dec 02 18:02:00 pve3 systemd[1]: pvesr.service: Succeeded.
-- Subject: Unit succeeded
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- The unit pvesr.service has successfully entered the 'dead' state.
Dec 02 18:02:00 pve3 systemd[1]: Started Proxmox VE replication runner.
-- Subject: A start job for unit pvesr.service has finished successfully
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit pvesr.service has finished successfully.
--
-- The job identifier is 84803.
Dec 02 18:02:02 pve3 pvestatd[2706]: got timeout
Dec 02 18:02:02 pve3 pvestatd[2706]: status update time (5.128 seconds)
Dec 02 18:02:03 pve3 pvedaemon[1494765]: VM 106 qmp command failed - VM 106 qmp command 'guest-ping' failed
Dec 02 18:02:12 pve3 pvestatd[2706]: got timeout
Dec 02 18:02:12 pve3 pvestatd[2706]: status update time (5.130 seconds)
Dec 02 18:02:22 pve3 pvestatd[2706]: got timeout
Dec 02 18:02:22 pve3 systemd[1]: Starting Ceph object storage daemon osd.0...
-- Subject: A start job for unit ceph-osd@0.service has begun execution
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has begun execution.
--
-- The job identifier is 84858.
Dec 02 18:02:22 pve3 ceph-osd-prestart.sh[1519360]: OSD data directory /var/lib/ceph/osd/ceph-0 does not exi
Dec 02 18:02:22 pve3 systemd[1]: ceph-osd@0.service: Control process exited, code=exited, status=1/FAILURE
-- Subject: Unit process exited
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- An ExecStartPre= process belonging to unit ceph-osd@0.service has exited.
--
-- The process' exit code is 'exited' and its exit status is 1.
Dec 02 18:02:22 pve3 systemd[1]: ceph-osd@0.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- The unit ceph-osd@0.service has entered the 'failed' state with result 'exit-code'.
Dec 02 18:02:22 pve3 systemd[1]: Failed to start Ceph object storage daemon osd.0.
-- Subject: A start job for unit ceph-osd@0.service has failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has finished with a failure.
--
-- The job identifier is 84858 and the job result is failed.
Dec 02 18:02:22 pve3 pvestatd[2706]: status update time (5.136 seconds)
Dec 02 18:02:22 pve3 pvedaemon[1517739]: VM 106 qmp command failed - VM 106 qmp command 'guest-ping' failed
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Service RestartSec=100ms expired, scheduling restart.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Scheduled restart job, restart counter is at 1.
-- Subject: Automatic restarting of a unit has been scheduled
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Automatic restarting of the unit ceph-osd@0.service has been scheduled, as the result for
-- the configured Restart= setting for the unit.
Dec 02 18:02:23 pve3 systemd[1]: Stopped Ceph object storage daemon osd.0.
-- Subject: A stop job for unit ceph-osd@0.service has finished
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A stop job for unit ceph-osd@0.service has finished.
--
-- The job identifier is 84927 and the job result is done.
Dec 02 18:02:23 pve3 systemd[1]: Starting Ceph object storage daemon osd.0...
-- Subject: A start job for unit ceph-osd@0.service has begun execution
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has begun execution.
--
-- The job identifier is 84927.
Dec 02 18:02:23 pve3 ceph-osd-prestart.sh[1519373]: OSD data directory /var/lib/ceph/osd/ceph-0 does not exi
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Control process exited, code=exited, status=1/FAILURE
-- Subject: Unit process exited
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- An ExecStartPre= process belonging to unit ceph-osd@0.service has exited.
--
-- The process' exit code is 'exited' and its exit status is 1.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- The unit ceph-osd@0.service has entered the 'failed' state with result 'exit-code'.
Dec 02 18:02:23 pve3 systemd[1]: Failed to start Ceph object storage daemon osd.0.
-- Subject: A start job for unit ceph-osd@0.service has failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has finished with a failure.
--
-- The job identifier is 84927 and the job result is failed.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Service RestartSec=100ms expired, scheduling restart.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Scheduled restart job, restart counter is at 2.
-- Subject: Automatic restarting of a unit has been scheduled
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Automatic restarting of the unit ceph-osd@0.service has been scheduled, as the result for
-- the configured Restart= setting for the unit.
Dec 02 18:02:23 pve3 systemd[1]: Stopped Ceph object storage daemon osd.0.
-- Subject: A stop job for unit ceph-osd@0.service has finished
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A stop job for unit ceph-osd@0.service has finished.
--
-- The job identifier is 84996 and the job result is done.
Dec 02 18:02:23 pve3 systemd[1]: Starting Ceph object storage daemon osd.0...
-- Subject: A start job for unit ceph-osd@0.service has begun execution
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has begun execution.
--
-- The job identifier is 84996.
Dec 02 18:02:23 pve3 ceph-osd-prestart.sh[1519380]: OSD data directory /var/lib/ceph/osd/ceph-0 does not exi
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Control process exited, code=exited, status=1/FAILURE
-- Subject: Unit process exited
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- An ExecStartPre= process belonging to unit ceph-osd@0.service has exited.
--
-- The process' exit code is 'exited' and its exit status is 1.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- The unit ceph-osd@0.service has entered the 'failed' state with result 'exit-code'.
Dec 02 18:02:23 pve3 systemd[1]: Failed to start Ceph object storage daemon osd.0.
-- Subject: A start job for unit ceph-osd@0.service has failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has finished with a failure.
--
-- The job identifier is 84996 and the job result is failed.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Service RestartSec=100ms expired, scheduling restart.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Scheduled restart job, restart counter is at 3.
-- Subject: Automatic restarting of a unit has been scheduled
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Automatic restarting of the unit ceph-osd@0.service has been scheduled, as the result for
-- the configured Restart= setting for the unit.
Dec 02 18:02:23 pve3 systemd[1]: Stopped Ceph object storage daemon osd.0.
-- Subject: A stop job for unit ceph-osd@0.service has finished
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A stop job for unit ceph-osd@0.service has finished.
--
-- The job identifier is 85065 and the job result is done.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Start request repeated too quickly.
Dec 02 18:02:23 pve3 systemd[1]: ceph-osd@0.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- The unit ceph-osd@0.service has entered the 'failed' state with result 'exit-code'.
Dec 02 18:02:23 pve3 systemd[1]: Failed to start Ceph object storage daemon osd.0.
-- Subject: A start job for unit ceph-osd@0.service has failed
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- A start job for unit ceph-osd@0.service has finished with a failure.
--
-- The job identifier is 85065 and the job result is failed.
") ).
). sd_op_tp thread 0x7fa3ffe8b700' had timed out after 15
sd_op_tp thread 0x7fa3ffe8b700' had timed out after 15