Hi
New here! Have just completed the installation of 3 Proxmox instances, created a cluster, and installed Ceph on all three.
The same process for all three.
Network-wise, all is good, all three nodes seem perfectly operational.
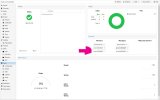
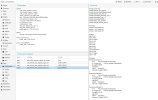
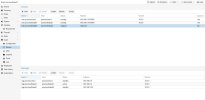
For some reason, on only one of my nodes, I cannot get a monitor to start. It's continually at status Unknown, and when I try anything, it looks like the system doesn't even know about it.
Sorry, I'm not very skilled in this area.
There is nothing in the logs that's of any use.
Looking around, I suspect it's a communications thing with sockets. But why... they were all configured the same way.
Appreciate any help you can give me!
New here! Have just completed the installation of 3 Proxmox instances, created a cluster, and installed Ceph on all three.
The same process for all three.
Network-wise, all is good, all three nodes seem perfectly operational.
For some reason, on only one of my nodes, I cannot get a monitor to start. It's continually at status Unknown, and when I try anything, it looks like the system doesn't even know about it.
Sorry, I'm not very skilled in this area.
There is nothing in the logs that's of any use.
Looking around, I suspect it's a communications thing with sockets. But why... they were all configured the same way.
Appreciate any help you can give me!

")