Hi,
I have 4 node PVE Cluster with CephFS deployed and from a couple of months ago i get MDS oom kills and sometimes MDS are deployed on another node and get stucked on clientreplay status, so i need to restart this MDS again to gain acces to cephfs from all clients
Checked scheduled jobs or ceph syslog but cannot get what kind of job could be running to use all memory avaliable on node so i don't know were to look to avoid this issues
Cluster has 4 nodes, 2 with 96 GB RAM and another 2 with 192 GB RAM, all with 24 cores Intel(R) Xeon(R) CPU X5675 @ 3.07GHz (2 Sockets)
PVE still on 7.3.3 and Ceph Version 17.2.5
Get 2 Ceph pools:
FAST with nvme disks (2 disks / OSD 2 TB per node )
SLOW with HDD disks (2 disks / OSD 2 TB per node )
Only 1 cephfs on FAST with 2 MDS active and another 2 MDS on standby, this setup was made after some issues with only one MDS to keep critical services deployed on cephfs working in case of mds fails without automatic recovery works
Get this errors mostly on weekends, beginning friday night till monday morning (no weekend backups to PBS enabled now)

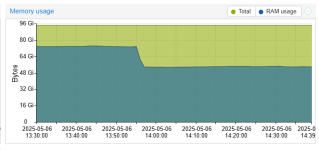
Each memory peak get a oom-kill event on node and mostly of RAM were used by mds

Try to limit memory usage but no luck



I've checked doc about ceph with no clue about root cause, only some referers to possible memory leak on ceph, but no way how to check it
Any clue about this??
Thanks and regards
I have 4 node PVE Cluster with CephFS deployed and from a couple of months ago i get MDS oom kills and sometimes MDS are deployed on another node and get stucked on clientreplay status, so i need to restart this MDS again to gain acces to cephfs from all clients
Checked scheduled jobs or ceph syslog but cannot get what kind of job could be running to use all memory avaliable on node so i don't know were to look to avoid this issues
Cluster has 4 nodes, 2 with 96 GB RAM and another 2 with 192 GB RAM, all with 24 cores Intel(R) Xeon(R) CPU X5675 @ 3.07GHz (2 Sockets)
PVE still on 7.3.3 and Ceph Version 17.2.5
Get 2 Ceph pools:
FAST with nvme disks (2 disks / OSD 2 TB per node )
SLOW with HDD disks (2 disks / OSD 2 TB per node )
Only 1 cephfs on FAST with 2 MDS active and another 2 MDS on standby, this setup was made after some issues with only one MDS to keep critical services deployed on cephfs working in case of mds fails without automatic recovery works
Get this errors mostly on weekends, beginning friday night till monday morning (no weekend backups to PBS enabled now)
Code:
-- Journal begins at Fri 2022-10-28 12:19:59 CEST, ends at Mon 2025-04-28 08:51:01 CEST. --
Apr 25 00:00:00 zpveo1 ceph-mds[782250]: 2025-04-25T00:00:00.080+0200 7f8d3c47c700 -1 received signal: Hangup from killall -q -1 ceph-mon ceph-mgr ceph-mds ceph-osd ceph-fuse radosgw rbd-mirror cephfs-mirror (PID: 3615629) UID: 0
Apr 25 00:00:00 zpveo1 ceph-mds[782250]: 2025-04-25T00:00:00.104+0200 7f8d3c47c700 -1 received signal: Hangup from (PID: 3615630) UID: 0
Apr 25 23:55:34 zpveo1 systemd[1]: ceph-mds@zpveo1.service: A process of this unit has been killed by the OOM killer.
Apr 25 23:55:38 zpveo1 systemd[1]: ceph-mds@zpveo1.service: Main process exited, code=killed, status=9/KILL
Apr 25 23:55:38 zpveo1 systemd[1]: ceph-mds@zpveo1.service: Failed with result 'oom-kill'.
Apr 25 23:55:38 zpveo1 systemd[1]: ceph-mds@zpveo1.service: Consumed 1d 1h 11min 37.806s CPU time.
Apr 25 23:55:38 zpveo1 systemd[1]: ceph-mds@zpveo1.service: Scheduled restart job, restart counter is at 7.
Apr 25 23:55:38 zpveo1 systemd[1]: Stopped Ceph metadata server daemon.
Apr 25 23:55:38 zpveo1 systemd[1]: ceph-mds@zpveo1.service: Consumed 1d 1h 11min 37.806s CPU time.
Apr 25 23:55:39 zpveo1 systemd[1]: Started Ceph metadata server daemon.
Apr 25 23:55:39 zpveo1 ceph-mds[794009]: starting mds.zpveo1 at
Apr 26 00:00:00 zpveo1 ceph-mds[794009]: 2025-04-26T00:00:00.091+0200 7f8bc83c9700 -1 received signal: Hangup from killall -q -1 ceph-mon ceph-mgr ceph-mds ceph-osd ceph-fuse radosgw rbd-mirror cephfs-mirror (PID: 798340) UID: 0
Apr 26 00:00:00 zpveo1 ceph-mds[794009]: 2025-04-26T00:00:00.127+0200 7f8bc83c9700 -1 received signal: Hangup from (PID: 798341) UID: 0
Apr 27 00:00:00 zpveo1 ceph-mds[794009]: 2025-04-27T00:00:00.097+0200 7f8bc83c9700 -1 received signal: Hangup from killall -q -1 ceph-mon ceph-mgr ceph-mds ceph-osd ceph-fuse radosgw rbd-mirror cephfs-mirror (PID: 2171840) UID: 0
Apr 27 00:00:00 zpveo1 ceph-mds[794009]: 2025-04-27T00:00:00.121+0200 7f8bc83c9700 -1 received signal: Hangup from (PID: 2171841) UID: 0
Apr 28 00:00:00 zpveo1 ceph-mds[794009]: 2025-04-28T00:00:00.074+0200 7f8bc83c9700 -1 received signal: Hangup from killall -q -1 ceph-mon ceph-mgr ceph-mds ceph-osd ceph-fuse radosgw rbd-mirror cephfs-mirror (PID: 3543923) UID: 0
Apr 28 00:00:00 zpveo1 ceph-mds[794009]: 2025-04-28T00:00:00.102+0200 7f8bc83c9700 -1 received signal: Hangup from (PID: 3543924) UID: 0Each memory peak get a oom-kill event on node and mostly of RAM were used by mds
Try to limit memory usage but no luck
I've checked doc about ceph with no clue about root cause, only some referers to possible memory leak on ceph, but no way how to check it
Any clue about this??
Thanks and regards