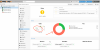
Hi all i am struggling to find the reason why my ceph cluster goes into 75% degraded (as seen in the screenshot above) when i reboot just one node.
The 4 node cluster is new, with no Vm or container so the used space is 0.
Each of the node contains an equal number of SSD OSDs(6 x 465gb) totalling 10TB and there is one poll with default replicated_rule and 3/2 parity + 1024 PG's. CEPH is running on a dedicated 10GBe network in LACP so advertised at 20GBps.
As seen in the screenshot, if i reboot one node i get that error of degraded but in my opinion it should be only 25% degraded (red color on graph) as there are still 3 nodes available. Is there something i am missing? Or do i interpreted incorrectly the graph?
Thank you all in advance.
pve-manager/6.1-5/9bf06119 (running kernel: 5.3.13-1-pve)
The 4 node cluster is new, with no Vm or container so the used space is 0.
Each of the node contains an equal number of SSD OSDs(6 x 465gb) totalling 10TB and there is one poll with default replicated_rule and 3/2 parity + 1024 PG's. CEPH is running on a dedicated 10GBe network in LACP so advertised at 20GBps.
As seen in the screenshot, if i reboot one node i get that error of degraded but in my opinion it should be only 25% degraded (red color on graph) as there are still 3 nodes available. Is there something i am missing? Or do i interpreted incorrectly the graph?
Thank you all in advance.
pve-manager/6.1-5/9bf06119 (running kernel: 5.3.13-1-pve)
Attachments
Last edited:
